Regarding the comments about complexity of existing formats - I agree, with the exception of PNG. In terms of complexity, QOI is very similar to PNG filtering phases, i.e. when you strip primary compression phase (Huffman coding) from PNG.
Also, I admire how the author combined a lot of common and cool tricks into QOI:
- Block tags form a sort of a prefix code, making it easy to differentiate block types with differing sizes
- Look-back array is used (common trick from LZW family)
- Delta-coding is used when storing pixel diffs
- In the end, if nothing else works, full pixel value is written
Also, the fact that everything is byte aligned is very appreciated.
This is a breath of fresh air and really impressive how good performance (both processing and size reduction) this gets with so little (very readable!) C.
Traditional compression research usually prioritized compression ratio, so more images would fit on your floppy disks and were faster to download over 28.8k modems. It usually means increased complexity.
Png has it’s own story as it’s #1 design goal was to avoid techniques that were patented at the time. So they combined a simple set of prepasses with zip/gzip compression. There were better techniques known at the time, but the idea was that combining simple, and known patent-free solutions was the safest way to achieve a free format.
The most important is probably the difference between lossy and lossless compression...
(The GP-mentioned Bink is lossy ! Then he also for some reason uses a picture tending towards photo realistic which does NOT play well with lossless !)
Yeah there’s a difference in techniques used for lossy vs lossless. But my point was that in compression research, runtime performance was much less important than compression performance, that was no different for lossy compression.
speaking of runtime performance if you look at lzma for instance it's horrible on runtime performance but it produces some of the best compression ratio of all of them
lzma usually decompresses significantly faster than bzip2, which is what it mostly replaced in e.g. package distribution. It also decompresses fast enough that for slow enough connections download + decompression is faster than deflate. Compression is slow though, yes.
I know you don't like "design by committee" and overly complex formats. Also, the compression algorithm itself is somewhat independent of the "container format" that it's used with.
However, if I may make a suggestion: If you do end up rolling your own container format for any reason, always include a way to store the colour space of the image!
Treating RGB images as arrays of bytes without further tags is like treating char* as "text" without specifying the code page. It could be UTF8. Or Latin-1. Or something else. You don't know. Other people don't know. There's often no way to tell.
Similarly with colour spaces: sRGB, Display P3, and Adobe RGB are just close enough to be easily confused, but end up looking subtly wrong if mixed up.
I think the author's intending to use this only as a data packing format (ex. for app/game development) and not a general-purpose exchange format. If all you want to do is pack image/texture data for your game then I totally get why they assume RGBA8 storage and leave out metadata such as color space information.
Right - this thread of people asking for colorspaces, dpi data, arbitrary metadata collections… all are exhibiting precisely the ‘expert group’ committee mindset that this format is supposed to avoid.
If you want all that, there are formats galore that support it! The point is more: where are the formats for people who don’t need all that? Here is one. Please don’t try to ruin it.
You don’t need to support a ton of complex stuff, but if an rgb image format doesn’t then it should just have a version marker and the spec can simply say “the rgb data represents sRGB colors”.
Just like e.g. some compilers don’t support a lot of source file encodings but their non-support consists of clearly stating that a source file is UTF-8.
Note that this requirement is only for an image exchange format. A raw-er image format used internally in e.g a game doesn’t need it as badly.
But in an exchange format every user needs to know whether the image data is sRGB or Adobe. Because the reader didn’t encode the data.
Because this thing looks like it could fill the same need as ProRes while being simpler and open source. For the applications are you are talking about, the format cannot be ruined because it is an internal implementation detail, in the same way that the stb_* libraries can never be ruined. They are yours and everyone's for forever.
The GPs advice about recording color space is spot on. Why design a new container when there are tons of ones off the shelf ones. The collection of files inside a Zip is my goto.
I know games tend to assume color spaces from context, and do other hacky things like reusing alpha for height maps or RGB for vector coordinates.
But this approach is a source of endless conflict with image processing tooling, because nobody except the game author knows what the channels mean. Game developers keep complaining about image processing tools doing anything other than bytes-in-bytes-out on that data (e.g. clearing "unused" alpha or treating RGB as human-perceptible colors), because it breaks the unstated assumptions.
I wonder if color profiles will be important to images used for AI. Right now, as far as I can tell, people generally ignore details like that but I wonder if someday people are going to say, "oh wait, we've been completely ignoring color profiles. We could have been using that" or "we didn't realize how ignoring that messed things up"
I'm in the computer vision space and have looked into the effect of color spaces and encodings.
People had basically exactly the epiphany you described. For example, there are several color models which try to be more lighting-invariant or (racially) color blind (this is a very similar problem, humans are all more or less "orange" hue-wise due to melanin's spectrum). TSL is one such space, there are others.
Quick question, from the context and how the wikipedia article was written I assumed TSL was fairly new, however looking at the dates of the published papers it all seems be late 90's early 2000's. Is this still in use somehow? I've never heard of it before, even though I've dabbled a bit in image processing from time to time in my line of work.
Videogames don't need color spaces, but they have different compression formats on GPUs, like S3TC, BC7, or ASTC. These things save not just storage, also VRAM bandwidth.
Videogames do need color spaces once you want to do any advanced enough lighting, it's jus that the only ones you want are sRGB or linear (floating point) so it can often be assumed by context.
S3TC, BC7, and ASTC are all lossy compressions so they are really not comparable.
A lot of people don't want to play games that look bad - I'd assume that this is going to be a particular issue when a game goes for photo-realistic graphics, only to end with people with orange skin colour on lots of monitors...
I work in a VFX adjacent space, so I have some pretty strong feelings about what data should be stored in the colorspace tags. The colorspace data should be an arbitrary string. I would also like to have "usage intent" tag for whether this is color or non-color data. You would think that the colorspace would tell you, but people do silly things like save specular maps as sRGB. For completeness I would want the following fields:
- colorspace - arbitrary string, the colorspace of the color data on disk.
- rgb_primaries - arbitrary string, indicates the physical meaning of the linear RGB values.
- transfer_function - arbitrary string, indicates the function to use to linearise the values from disk into the RGB primaries.
- intent - one of display, texture, data, or an arbitrary string. Display images get tone-mapped, textures do not, data only gets linearised, even if it has rgb_primaries attached, other values only have internal meaning to the concrete art pipeline.
For the first three, rgb_primaries and transfer_function take precedence over colorspace. The reason I want them is because people do mix and match. You could say that you can put the same data in some string format in the colorspace tag, but then everyone will invent their own slightly different way of specifying it and interoperability will suffer. Best to just force the values to be unstructured.
A lot of arbitrary strings, but that's how it is - there is really no standard list of colorspace names. These four fields can cover pretty much everything I have seen people do.
Though currently a lot of people just tag the filename with a colorspace suffix and call it a day. OpenColorIO even has a function to directly get a colorspace from a filename.
I've never understood the need for color profiles on images themselves. On monitors and displays, sure, those vary, but why allow people to specify a color profile on an image, thus making images no longer a ground truth for pixel value? It seems like the main use case is dealing with images that already have color profiles. What is the point?
The point is to use bits effectively and not waste them, by accounting for what usually happens on most displays and in our eyes & brains. If we don’t account for it, then (for example) a 1-bit difference between two bright colors means something very different from a 1-bit difference between two dark colors.
So what is “ground truth” exactly? We need to know what units we’re talking about; is it lumens, or “tristimulus” values (what we want our eyes to see), or LCD monitor voltages, or something else? First we have to agree on what ground truth means.
A big reason for common formats like PNG and JPEG to need color profiles is because 8 bits per channel is not enough color resolution unless you store the colors non-linearly. 8 bits is barely enough (or some would say almost enough) to represent low-dynamic-range images on TVs and monitors even when you have the colors gamma encoded or use a perceptual color space.
The problem with storing “ground truth” values for pixels in 8-bits-per-channel formats is that many experts would probably say this implies a linear color space. And a linear color space encoded in 8 bits leaves noticeable gaps between colors, such that you can see color banding if you try to render a smooth gradient. You lose up to 2 bits of color precision in some regions, notably the dark colors.
So, in order to not have color banding, we correct the colors before storing them by trying to make the colors have even steps between any 1-bit change in the spectrum. The color profile is just a record of what was done to correct the colors, so someone else can un-correct them as needed.
You might think we could do away with color profiles for high-dynamic-range images, but the non-linearity of our vision and our displays means that linear encodings are still inefficient with their bits even if you have 32 bits per channel.
Right, which begs the question why on earth would there be more than one image color profile. The image color profile should just be implied and the same everywhere.
> We're stuck with images stored in the display profile of old CRTs by default, because that was the most practical option at the time.
The analogue in photography is photographs lose color clarity and fade as they age. Why should I care if this is the case in images as display technology evolves when this is already a problem with every physical medium?
> For correct editing operations, and correct display. Sadly, it's not pedantry, it's reality.
I've been designing images and graphics for the web and sometimes for print off and on as a regular part of my various job functions since ~2009 and I have yet to see a situation where a color profile on an image isn't a huge pain and something that needs to be stripped away to get seemingly correct results.
Back to my point, I still don't see the value of having a color profile applied to an image. Images exist in the ether as platonic ideals, and we try to approximate them with our various display technologies. Why complicate the matter by also having multiple "flavors" of the platonic ideal itself? When I say (255, 0, 0), I expect the display to show me its best approximation of red. When I say (255, 255, 255), I expect the display to show me something as close to white as possible (and at the brightest possible setting). When I say (0, 0, 0), I expect the display to show me something that looks as close to black as possible. It's up to the display technology to decide whether this means just turn off that pixel on the screen or disengage the backlight or do whatever, but at the end of the day it's just trying to approximate black.
This is complicated enough, why do I need an image that will look good on only one kind of display and will have it's greens look pink on other displays. Isn't having a color profile for the display enough?
> When I say (255, 0, 0), I expect the display to show me its best approximation of red.
Which red? There isn't a single, true "red". And different materials produce different reds (my work's Sony BVM-X300's reddest red is going to look way different than your monitor's red). Not all displays use only RGB color primaries, too. For example, at Dolby's office in San Francisco they have a projector in their theater that uses 5 (IIRC) color primaries, not 3. 6-primary projectors exist. And other non-RGB displays.
> When I say (255, 255, 255), I expect the display to show me something as close to white as possible
Which white? D50? D55? D60? D65? D67? Something else? And yes, these different white points (and many others) are actually used in practice.
> (and at the brightest possible setting).
100 nits looks way, way different than 4,000 nits. Some monitors can do 10,000 nits.
> When I say (0, 0, 0), I expect the display to show me something that looks as close to black as possible. It's up to the display technology to decide whether this means just turn off that pixel on the screen or disengage the backlight or do whatever, but at the end of the day it's just trying to approximate black.
Which black? This might sound dumb, because we can agree that there is an objective "absolute black" (i.e. zero photons). But when an artist creates an image, the monitor they use has some version of black. If you don't account for that, the image may be distorted. Blacks can be crushed, for example.
An absolute color space exists. It's called XYZ. We could use it. Some image formats support it.
And the red in my left eye isn't the same as the red in my right eye. Yes, when the lighting conditions are just right, I see different hues out of each eye [1]. I have to wonder how one would (or should?) correct for that in an image file format.
I think the best we can do with file-level metadata is account for only objective metrics. Subjective differences are best handled outside of the file metadata. The user can tune their display settings to match their preferences. This allows for correcting for physiological differences and stylistic preferences. If all files had correct metadata (for objective metrics), it would be a lot easier for an end user to tune the system to their liking because their end results would be consistent with their preferences.
took me a while to notice that I perceive color and light intensity differently in my two eyes. I think this is actually pretty natural (IE, it happens commonly?). Either way, I can also see polarization (haidinger's brush) which confused me a bunch when I was trying to explain what I saw and everybody else thought I was crazy).
Okay, fair enough two out of three primaries are imaginary colors, but nobody said you have to use the whole color space when your processing pipeline is meant to be using 32 bit floats. Delivery formats might want to be using a more real color space.
ACES (AP0) is an archive format for when you want to be absolutely sure you’re not clipping any colours. As a working space it’s terrible and AP1 should be preferred, either as ACEScg or ACEScc
AP1 is almost the same as rec.2020? I'm not sure what you mean by 'working space' but if preserving all colors was a primary or even secondary goal I definitely wouldn't cut myself down that far.
You're assigning a color profile to the image in your model - the color profile of the display. Hence no color conversion needed, as source and target match.
What "red" and "green" are has changed quite dramatically with different display technologies. A display designed to meet Rec.2020 can show colors that other displays literally cannot produce and the deviation between the primaries is so big that everything looks like garbage if you don't do a color space conversion. Take some sRGB content and display it on a DCI P3 display. Looks like shit. Humans look like crabs.
> On monitors and displays, sure, those vary, but why allow people to specify a color profile on an image
The sole reason why we have device profiles defining device color spaces is so that we can convert from the image's color space to the device's color space. If images don't have a profile assigned to them, you don't need a device profile.
So you either have both image and device profile, or neither. Just one doesn't make sense.
But if you were forced to always use the same color profile on images? Why allow more than one? Wouldn't that vastly simplify the problem, as then you just have to worry about the device profile, instead of worrying about variation on both ends?
I get what you mean, but... the color profile of the image is the profile of the display where the image can be displayed without adjustment. Think of it as the display profile of the guy that sent you the image. The magic math transforms the image to your display profile. That means it will look exactly the same on both displays. If they both have a correct display profile.
If your green is going pink, then either your profiles are wrong, or your software is broken. Maybe it really is pink, and it just looks green for you, because you're ignoring color profiles.
But the fact is, most software is broken, and you should store images with the sRGB profile.
And also, you can actually calibrate consumer hardware, so that you can scan a photo, and reprint it. And the scan, display, and print will look exactly the same. (It's not the case by default, because consumer printers do what you do, stretch or fit the color space to the printer's. The Vivid and Natural profiles in the driver, respectively. This is a good default for documents, not for professional photography.)
Right, so sRGB should really just be the only allowed profile for images. That's my whole argument. There should be some standard profile all images should use, and then displays should deal with the work of converting things to a suitable display profile. Allowing more than one image-level profile just makes things way more complex for no perceivable benefit.
>That means it will look exactly the same on both displays. If they both have a correct display profile
We can continue believing that Santa exists, or we can accept that effectively nobody has correct color profiles, and doesn't care either.
It's nice metadata you have there, would be a shame if I applied night mode to it at 6PM.
> also, you can actually calibrate consumer hardware
...with professional hardware that costs more than the one you have at hand.
Again, pretty much everyone will just tweak their monitor/printer settings until they get results that look OK.
>display and print will look exactly the same
Until you turn off the lights. Or until you turn on the lights (what color temperature is you light?). Or until the wind blows, moving that cloud over the sun, changing light temperature.
Or — wait for it — actually, that's all, while you've been waiting the sun has set.
The point being, all we can shoot for is FF0000 being what would be "red" for most, 00FF00 being "green", and 0000FF being "blue" — and then accept the "fade" of the digital image from one screen to another as a fact of life.
So, learn how to stop worrying and love unspecified RGB colorpsaces. Magenta only exists in your brain anyway [1]
Side note: did you ever think about how your recorded music isn't adjusted for the frequency response of the loudspeakers, and half the people will listen to it with the "BASS MEGABOOST" feature on anyway?
That's why the art of mastering exists. It's accepting the reality, and putting work into making it work with uncalibrated, crappy hardware — as well as hi-fi gear.
PS: have fun calibrating your vision to make sure that you don't see green where I see red
As you mention, our brain adapts pretty easily to varying lighting conditions in the real world, and that could also work on a screen[1], but the ambiant context is what matters: if you look at an image “A” in your said “undefined color space” after having spent quite some times looking at sRGB images for a while, then your image “A” would look absolutely horrible until your brain starts to adapt, like when you put sunglasses on or off for instance. The big difference being: with sunglasses, we have no choice but wait for our brain to adapt, but on a computer all the user would do is close the image.
[1]: even though for some reason I don't know, it works much less well: if you try and take pictures with the wrong white balance setting, the picture will look like shit no matter how long you look at it.
Thankfully, "as bright as the sun" is waaaaaaay outside of what a monitor is capable of : SDR is (supposed to) top out at 10^2 cd/m^2, HDR10 at 10^3, Dolby Vision maxes out at 10^4 cd/m^2, but the midday sun is... ~10^9 !
sRGB is quite literally defined as "the average 90s CRT in an office environment", i.e. full-white sRGB on a HDR display should be around 100 nits or so in those reference conditions (i.e. display set to "reasonable" brightness).
Do you have a recent iPhone? Try taking a picture with the sun in it: the white of it will appear white as well, but the phone will display it considerably brighter than the white UI surrounding it.
> This is complicated enough, why do I need an image that will look good on only one kind of display and will have it's greens look pink on other displays.
That is precisely what attaching a profile to the image is supposed to avoid. It indicates what (255, 0, 0) in that image actually means. Then you convert that to the display profile to get the triplet that you must send to the display to actually get something that looks like it.
> Isn't having a color profile for the display enough?
> The analogue in photography is photographs lose color clarity and fade as they age. Why should I care if this is the case in images as display technology evolves when this is already a problem with every physical medium?
What does "255" mean? If you just take it to mean "max saturation that your display can output" then it's going to be perceived as a different color depending on the viewer's display. That is undesirable. And due to historical reasons (the capabilities of CRT monitors) the meaning of "max saturation" was de facto standardized to what we now call sRGB. If you want to encode a greater range of colors than sRGB then you need to be able to say that hey, this "255" is more saturated than what sRGB considers "255" and should not be displayed on sRGB without conversion.
Because display technology can't reproduce the full set of colors we see and and moreover, we have a finite number of bits to encode the value of any pixel. A color space/profile is both a target for display manufacturers to produce and a way of standardizing the trade off between bit depth and quantization error.
Unfortunately, that's not the case in pragmatic reality.
When I say #ff0000, do I mean "sRGB red", as a TV would display in pure red phosphors back in the 1970s, or do I mean "1000K" / 700nm red (daylight is 6500K), which can only be reproduced by specialized displays?
Most people from the time before Apple made Display P3 wide color displays standard in all their products — so, most HN commenters — believe that #ff0000 just means "only red, no green or blue" — but all web browsers currently are left to invent their own answer for what #ff0000 means, and they do not all invent the same answer. Yet.
So it is with images.
In the beginning times, people made sixteen-color images for NTSC monitors, and then other people learned you could display synthetic colors that don't exist by mangling the image bitstream to the monitor, and those sixteen colors were hard-coded but varied by like +/-5% per device due to acceptable manufacturing tolerances, so they were internally consistent anyways.
And so we end up, today, trying to solve color profiles for file formats that specify colors as RGB hex values — which are, by definition, restricted to sRGB and thus wildly insufficient. But if we plan too far, we get file formats that are totally ridiculous - TIFF comes to mind - that can represent anything under the sun, at the cost of having a 1:1 mapping of "pixels" to "bytes" or worse.
You may also find the history of the EXR format relevant here, as it supports a functionally infinite amount of dynamic range in images, and there are definitely good niche use cases for it — but pragmatically, it's ridiculously overkill for normal everyday purposes. You could argue that everyone should use EXR in Lab, but then someone would suggest Oklab (since it makes better perceptual compromises) or HSLuv (what a great name), or you could try storing raw CIE 1931 chromaticity coordinates, which has been deprecated by CIE 170-2 to address serious flaws in the 1931 system.
Tying this back to engineering, there are often very good reasons for designing a processor or a byte store to be RISC or CISC, big or little endian, and we simply cannot predict what will work most pragmatically for all cases universally ahead of time, any more than the metric system was invented early enough in time to prevent miles per hour from being a unit of measure.
A color space and color profile are not the same. The point is knowing what a byte represents in a byte array. Is it red, hu, saturation, alpha, brightness etc?
No single color space is complete. Each has trade-offs. I would actually say that color profiles help get closer to ground truth, that is, rendering intent.
Isn’t that kind of like saying Real numbers are complete? Yes, it’s true, but we don’t have an infinite level of precision for each colour. So we have to, practically speaking, limit how many colours can be specified to some reasonable (and arbitrary) number, e.g. 10 million or 1 billion or more (in terms of number of colours in a colour space) and representation in digital bits. Also, since I conflated the two a bit, it is often helpful to restrict what the max range of a colour is so that you can get more useful data out of the same precision. It’s kind of like creating a dictionary to compress data, you can express more useful values with less data by choosing to display a subset of colours and by picking where the white point is for your display. These optimizations used to mean more than they do today, perhaps, but it can still take a lot of effort to transfer 10-bit or 12-bit raw pixel data at 4K resolution, 120 times a second… And it’s worth pointing out that while 8-bit is all you might need as precision for perceptually lossless HDR (with dithering), that kind of range isn’t good enough for colour editing work. It’s like starting a photo edit from the JPEG rather than the RAW file.
8 bit just objectively isn't enough for hdr. 8 bits is few enough that you can pretty easily see banding on a simple color gradient in sdr. Dithering helps a lot, but once you get to HDR 10 bits is pretty much the minimum.
If you compare Rec.2020 with 10 bits per channel and sRGB at 9.5 bits per channel, both of them using the same peak brightness, you should see similar amounts of banding on both.
Increasing the maximum brightness can require a lot of extra bits to keep things smooth, but that's a separate thing from which colors are possible.
Ah, I see your point, but I still don't understand this argument, because in practice not only we want extra brightness in colours around the usual white points, but also we need the extra potential physical brightness to extend the colour space itself in terms of "colours only" (not sure that this even makes sense ?) because of the differing needs of different colours.
(I'd assume that this is especially relevant for backlit displays like the liquid crystal ones, since they have to use the same potential maximum source power for all of the channels.)
Gamut is affected by brightness but not that much.
Rec.709 has 10 and 12 bit modes too, and it needs them, even though it has the same gamut as sRGB.
The reason 10 bits isn't enough for Rec.2020 is because 10 bits was never enough to fully represent any gamut. Once you add enough bits to properly support a gamut, then extending it to match human vision is a tiny cost.
And to be extra clear, when I initially said "The difference between all visible colors and a more constrained color space", I was talking about taking a color space and expanding its gamut without changing anything else about it.
I guess when I said "no color space is complete" I meant "no color space is faithfully bijective to nominative human visual sensory response." Because such a thing is basically impossible (or insanely nonlinear and unwieldy).
Also these color systems all or almost all assume a "norminal" (to steal a word from Everyday Astronaut, normal+nominal) average human vision system. If your system isn't norminal, average, human, or even visual (visible light), then your color space is an incomplete map of the territory.
So for any given array of pixel channel, there is either an implicit assumption or explicit color space of what those values "mean".
So GP's question was basically "why do we need color profile?" and the short answer is "to know what images should look like".
In order to know what an image should look like, a "perfect" or "complete" representation, at minimum the real colors must be injective to the color space (every value has at most 1 color). You could argue that the color space needn't be injective (values that have no color), which is probably fine if your image is static and you never manipulate it. As soon as you manipulate values of your image in your color space, you run the risk of falling outside the color domain.
But really to unpack this whole thread, my essential point is that color spaces are about engineering tradeoffs. sRGB can't reproduce many colors. CIE 1931 represents all color but has imaginary colors.
Ergo, I contend there is no "complete" color space.
Yes, it has to be injective from the real world to the file format. It doesn't have to be bijective.
> As soon as you manipulate values of your image in your color space, you run the risk of falling outside the color domain.
If your manipulation could go outside the domain, then your manipulation is incorrect. Like, if I have a number from 0 to 99 that I store in a byte, it's fine that a byte is not bijective to those numbers, and if I end up with a byte representing 105, then I did something wrong that corrupted my byte.
If I'm doing incorrect math, a bijective color space doesn't fix the problem, it just guarantees that I get an incorrect color out the other end instead of possibly getting an incorrect color or possibly getting an error value.
Good luck representing that with only 3 channels, without using "bytes representing 105" (aka imaginary colors), and trying to stay percepetually uniform !
It gets even worse : the real color space is non-Euclidean : it stretches out, parallel lines drift further apart, etc.
> without using "bytes representing 105" (aka imaginary colors)
I think you misunderstood my point.
I'm saying it doesn't matter if certain byte sequences are invalid and don't correlate to real colors.
Imagine you're encoding two digit numbers into bytes. It's not bijective but that's fine, no correct two-digit math will give you an invalid byte.
Or imagine you're encoding numbers into bytes the way UTF-8 works. It's not bijective to all sequences of bytes but that's fine. No correct manipulation will give you a sequence that can't decode.
If you're trying to do incorrect math, you've already lost, and no color space will help. For example, overflowing your red channel in sRGB could turn your eggshell into a cyan.
> and trying to stay percepetually uniform
Where did that come from?
Zero encodings will be perceptually uniform, therefore being non-uniform isn't a disqualifier.
If you author an image on Display A and save its colours, then how does Display B know to render colours correctly that looks consistently with Display A?
You have two options:
1.) Tag Display A's colour space into the image, then convert colours to match Display B's colour space when rendering;
2.) Convert colour data from Display A colour space into a generic colour space (like sRGB, Display P3, ACEScg, etc) and embed that in to the image, then convert colours to match Display B's colour space when rendering.
Since we are talking container formats, I would recommend something in the IFF/RIFF family (which includes "true" Four-byte-type IFFs like RIFF, WAV, WEBP, and variants like PNG, MOV, MP4). They are about as simple as you can get as a container format. It has its limitations but it's basically the simplest "boxed" format you can implement - Type-Length-Value.
I would absolutely recommend basing on some sort of container format (vs "raw" data structures), it makes it really easy to add functionality without breaking backwards compatibility.
Basically all container formats follow this idea of "collection of boxes" pattern. The IFF series are box-length based. Ogg uses capture patterns but no explicit box size (I think). The former means you have to know the box size ahead of time (or seek back and write it in), the latter is better for streaming, but harder to seek (without indexes).
I don't think that's a good idea. Most images, like photos and screenshots, don't have physical dimensions. Some image tools like to put in bogus default DPI values that are guaranteed to be wrong, and it can be a bit of pain.
Reproducing images at the "right" size is a very niche requirement. Most images don't even have a right size, including all photographs unless they either use an ortographic projection (they won't) or the object is completely flat and parallel to the focus plane (with recilinear projection, which most normal camera lenses come close to). Having this as a standard attribute in a generic image format makes no sense.
You are complaining about a format - with the stated goal to be very simple - not supporting some scientific usecase. What...? Use a different format then. That's not what this is trying to be. In fact, it's the exact opposite of what it's trying to be.
If you want any interop you'd better standardize some keys, allowing for extensions. Store those in key,len,data records and you have iff/ riff formats ... used by .avi and .wav formats.
This is something I've never understood. DPI only makes sense if you need to accurately represent some physical dimensions in an image. Most of the time, you do not. You would just map it onto screen pixels somehow, most probably dictated by the UI layout around it.
Color profiles however, yes, those are indeed important.
well nobody can control what will happen to a file's content either if you want to be pedantic.
If are worried about dumb users renaming it...I think most users know to not change things after a '.', so could just put the colorspace code there. And then could put another '.QOI' to end the filename.
If want to keep cruft out of the file itself, then putting it in the filename works.
you're talking apples and kumquats. changing the name of the file (metadata in and of itself) does not affect the file at all. changing the contents of the file will have affects on the file. some changes might not negatively affect the file (like adding metadata when none was present) if the format allows for it. you can know the file will no longer be the same by running a hash on it. name changes will not affect the hash.
also, changing the name of a file is not like, uncommon. if it is an image sequence, some people prefer an underscore before the frame number, some prefer a dot, and some even prefer a space. some places have strict file naming policies, and file names will be modified to comply.
anyone depending on crucial information to be preserved in a filename is just a Sisyphean effort of control.
the color scheme is not "crucial information". It is just meta-data. It could be contained in the file, or in the filename, or outside the file in a separate metadata file.
> To keep things O(n) when encoding, there's only one lookup into this array. The lookup position is determined by a “hash” of the rgba value (really just r^g^b^a).
Is a bit imprecise.
The algorithm would still be O(n) even with a linear search through the "seen pixel array", as it is bounded by 64 length and therefore a constant factor that gets eaten by the Big-O notation.
Because of this hash the algorythm seems to do something else than first described though.
Instead of "a running array of the 64 pixels it previously encountered", it's actually the previous 64 pixel _values_ previously encountered, which allows for much bigger jumpback.
By deterministically computing this array during execution it itself seems to act as a kind of compressed jumpback table, allowing for approximated arbitrary jumpback with just 6 bit.
Quite impressive!
Edit:
I think there might be an interesting tweak that could increase the effectiveness of the hashing technique used.
If one were to walk and store the pixels in a Z-Curve order, the runtime would stay the same but the locality of the color value pool, might be increased.
> Because of this hash the algorythm seems to do something else than first described though. Instead of "a running array of the 64 pixels it previously encountered", it's actually the previous 64 pixel _values_ previously encountered, which allows for much bigger jumpback.
It's somewhere in between. Because these values are hashed into single slots, assuming that hash codes are random, the probability that a value is still in the table after k intervening values is pow(63/64, k).
That means the table is unlikely to contain all 64 values, but it will also retain some older values. Since older values are less likely to be useful in the future the encoding performance is likely somewhat worse than if the algorithm used strictly the last 64 distinct values.
This means that the algorithm is a bit sensitive to hash collisions, which seem particularly likely for primary colors (i.e. with each of the components at value 0 or 255):
- Slot 0: black, ALL SHADES OF magenta (x ^ 0 ^ x = 0), yellow (etc.) and cyan.
- Slot 15: white (255 ^ 255 ^ 255 = 255), red (255 ^ 0 ^ 0 = 255), green (etc.), blue.
Except black and white, these are unlikely to occur often in photographic images but could well occur in bitmaps with a handcrafted palette, or when the RGB values are converted from a system with a lower color space. For example, the 16 color CGA palette maps to just 3 different slots.
In an image with very limited colors you would have long runs of the same color and it would compress well from just the run-length encoding alone.
Also, it's non-obvious that older values will be less useful. Going through the pixels in order like this doesn't preserve locality well, so older values may actually be closer to a given pixel than more recent ones.
I was about to post the same idea about a locality preserving pixel order. I was thinking about hilbert curves, never heard of z-curves. Would be nice to see if/how that affects the compression ratios. How surprising that a few simple principles can give quite a good image format
After making the edit, I saw that someone made the same suggestion on twitter!
Hilbert curves have slightly better locality than Z-curves, but Z-Curves are trivial to produce.
If you have a N dimensional space over unsigned integers, then you can place each point on a one dimensional Z-Curve by interleaving their bits into a new integer.
So for any point (X, Y) in the X-Y coordinates of an image the Z-Curve coordinate is X_1,Y_1,X_2,Y_2...
Which can be achieved with a bunch of bit shifts and masks, (or a bunch of wires if you happen to use it in an FPGA ^^')
I added Z-order curve to a ray tracer many years ago. Rather than using nested loops over X and Y pixel coordinates I used a single loop and de-interleaved the count to get X and Y. My thought was that this would increase the cache hit rate due to the locality of the pixels. It worked and the speedup was on the order of 10 percent. Because images are rarely power of 2 or even the same in both dimensions I opted to make a list of 32x32 blocks and rendered the blocks in Z-order as well as the pixels within (which still helped vs just tiling).
Hilbert curves are not that much more complex. Maybe ten or so lines of code. Interleaving bits is already a pretty complicated operations if you don't have builtins for it.
I agree that de-interleaving is fairly complicated, but interleaving can be done fairly easily with a lookup from a table for each dimension and then combining them: xbits[x] | ybits[y] | channelbits[c].
The nice thing about this is that just by changing the tables, you can get things like z-curve, tiles, row-major, or column-major pixel orders (or even combinations), plus swizzled, interleaved, or planar layouts for the color channels.
Based on some quick* testing using z-order instead of going row by row ends up taking 1-10% less space. Most images were on the lower end but I didn't run into any taking more space.
* Swapping to z-order requires about 5 lines of changes if you ignore all the little edge cases like non power-of-two image sizes. Images used in testing may or may not be representative of anything.
I wonder how much worse the compression would be if you just had the last 64 colors, but didn't update when using the run length byte codes. Seems like it would be close to the same, and the decoder wouldn't need to hash the pixels.
Out of curiosity, I modified the benchmark program to simply toss the pixel data into lz4/lz4hc for comparison (patch file: https://paste.debian.net/1220663/).
I'm actually quite impressed how the resulting size is a little bit smaller than lz4hc (actually not even that far away from libpng), while the encoding speed is quite close to lz4, despite seemingly not having as many hacks and tweaks under the hood to get there. So the encoder is IMO doing amazingly well actually.
However, the decoding speed of liblz4 is off by roughly an order of magnitude. But again, liblz4 probably benefits from decades of tweaking & tuning to get there. It would be interesting how much performance could be gotten out of the qoi decoder.
Here are the totals I get for the "textures" benchmark samples:
I believe (from quick code inspection) that the symmetry in encode/decode performance for QOI is because it has to generate the hash-table on decode too.
Normal fast encoders use some kind of hash table or search to find matches, but encode the offset of the match in the source rather than in the table. QOI is encoding the offset into the table, which gives much shorter offsets but means the decoder has to maintain the table too.
(The slow PPM compressors etc do maintain the same table in both encoder and decoder, and have symmetrical encode/decode performance too. See http://www.mattmahoney.net/dc/text.html)
Its not really in the spirit of of QOI to add the complexity, but I'd imagine allowing the encoder to specify how big the hash table was would be only a small tweak, and encoding literal blocks instead of pixel-by-pixel will improve handling input that QOI can't compress better.
I would be curious to know if planar helps or hinders. Perhaps even see what QOI makes of YUV etc. And I want to see 'heat maps' of encoded images, showing how cheap and expensive parts of them are, and which block type gets used. Yeah, going a bit beyond the spirit of QOI :D
And from looking at the code I'm a bit confused how 3-channel is handled for literals because the alpha still looks like it gets encoded. Would have to walk through the code to understand that a bit better. Is it going to deref off the end of the source RGB image? Etc.
Like the author said this is completely unoptimized. The natural next step in optimization might be to profile and then SIMD optimize the slow bits in compression and decompression. This would likely produce a significant speedup and may even bridge the gap with lz4.
The algorithm is extremely resistant to SIMD optimizations.
Every pixel uses a different encoding, 95% of the encodings rely on the value of the previous pixel, or the accumulated state of all previously processed pixels. The number of bytes per pixel and pixels per byte swing wildly.
SIMD optimization would basically require redesigning it from scratch.
I believe libpng default zlib compression level is 6. libpng may use CRC (or adler) checksums, which account for around 30% of the decode time. In my experience with zlib, the higher compression levels have faster decode times. My reasoning at the time was (early '00s) that higher compression tends to code longer runs of copying of the dictionary. More time in the copy loop rather than the input and decode loop.
> liblz4 probably benefits from decades of tweaking & tuning to get there
Decade, singular. LZ4 was proper around 2011. But the real reason it's faster is because its not doing nearly as much work as QOI. LZ4 is just about as asymmetric as you can get.
QOI_DIFF16 {
u8 tag : 3; // b110
u8 dr : 5; // 5-bit red channel difference: -15..16
u8 dg : 4; // 4-bit green channel difference: -7.. 8
u8 db : 4; // 4-bit blue channel difference: -7.. 8
}
I'd think that the extra bit ought to be given to green, since that tracks most closely with luminance. That would make this somewhat analogous to the RGB565 layout for 16-bit pixels (https://en.wikipedia.org/wiki/High_color#16-bit_high_color).
Though I wouldn't be myself if I didn't have few nitpicks ;)
- You are mixing lossy and lossless compression in your rant. And you are mixing containers with formats. Thing about lossy compression is that it is by design stupidly slow and complex to produce smallest possible results which has best perceived quality. Compress once and trade time for both image and compression quality. Lossless is not that bad, although your simple solution is well, simple :)
- I feel like the benchmark suite is lacking. For better overview you probably should include libpng results with max compression level and lowest compression level. Lossless modes of AVIF and WEBP would be nice. (also could throw similar project to yours like https://github.com/catid/Zpng) Not saying the benchmark is bad, but IMHO doesn't paint the full picture. From quick test I got significantly better compression on libpng, ofc in expense of time, but you didn't configure libpng for speed either. So we have some results, but they are not really representative imho.
- I understand it is pet project, but don't forget about importance of image metadata, like colorspace and so on.
- Also keep in mind that compression is easy at the beginning, but the tricky part is how to squeeze more.
I wrote a small test bench for my own uses as wanted to compare with different codecs and see how "raw compression" would work, how would QOI+ZSTD combination work and so on.
Really cool encoding, it is a bit incredible that such simple rules can archive such good results.
It is so interesting that if the image have few colors, method #2 alone (An index into a previously seen pixel) encodes the whole image into an indexed colour space (with the hash table becoming the pallet).
Ive seen already some comments recommending adding some vertical locality by tiling, Hilbert order, or Z order. I have yet another different vertical locality suggestion to try:
While encoding/decoding keep a ring buffer the size of one full line of the image, storing each encoded/decoded bit there. Then add a variation of method #3 (The difference to the previous pixel) which instead encodes the difference to the pixel above the current (the last pixel from the ring buffer). Maybe, due to the limited "tag" space it would not be worth it to implement it for DIFF8, but only for DIFF16 (taking one bit from red to the additional tag bit) and DIFF24 (I'm not sure which bit I would steal there).
Edit: Also, when thinking about video encoding in the future you may want to keep a ring buffer fitting the full last frame of video. And then temporal locality is probably even more important, so then you may want to change the tags to encode more commands relating to the pixel from the previous frame.
having done my own experiments with indexed pallets I suspect method #2 is responsible for most of the compression here. most photographs only have half a million distinct colors and it drops considerably as you focus in on an area. if you're willing to relax the single-pass requirement, partitioning the whole image by pallet similarly to how one encodes high-color images into multi-framed gifs can yield surprisingly good compression.
nice idea, I think it is somewhat more in line with the keep it simple option, as I e.g. have no idea what a hilbert curve for an arbitrary size rectangle looks like. And you still get compression for x and y directions (though no run length encoding the vertical, perhaps a further addition).
I quite like this approach of defining a few compression methods, see which one works best, and apply that one. I used a similar strategy for time series compression where I would take a chunk of data, apply z few different compression algorithms on it (RLE, delta RLE, etc) and just keep which ever one was smallest. Of course here it is done on a per pixels basis, and I used arbitrary size chunks. The latter is trivial to parallelize. Same could be applied here though, split the image in half and compress both parts independently
These kinds of formats have been somewhat explored by camera makers for their raw formats. Since the computing resources in the cameras can be quite limited there are a few formats that try to occupy this space of simplicity with still some tricks for compression. Samsung's various SRW encodings remind me most of this:
Lossy RAW is sometimes even simpler than that. E.g. Nikon's old compression was just remapping values in a log-like fashion, which reduced resolution in the brightest few stops[1] to save a few bits per sample.
[1] Perception is pretty logarithmic as usual, so for a 14-bit readout, half the values represent the brightest stop and a little bit, the other half holds the other 12+ stops.
There are a few formats that use a curve and less bits. They do become lossy and doing dithering on decompress is useful to avoid banding.
The Nikon one you mention was only used very early and is decoded by decode_8bit_wtable() in that file. It's just looking up the 8 bit value in the table and then adding some randomness to prevent the banding.
This is impressive, I was curious if it was just better on simpler images with many duplicate pixels but it's nice to see it working well with photography too
When I download that PNG file it is 10785 KB. If I re-encode it using FLIF 0.4 (to my knowledge still the best off-the-shelf lossless image compression) it is 7368 KB. That's 57% of the size of qoi, quite a lot smaller. You pay for it in encode/decode time though.
FLIF has been superseded[1] by JPEG XL, which, in my very limited testing, performed better (speed and compression-wise; libjxl) than FLIF.
Interesting though that FLIF 0.4 was released 3 days ago. I haven't checked out that new release (and won't), but the previous one wasn't great code and was a pain to use (ended up using its CLI instead of the lib). We ended up going back to PNG because of interoperability and speed. I haven't looked at libjxl's API yet.
Edit: 8605KB in 11.5s with libjxl, so it's not actually better than FLIF 0.4 (7368KB in 23.9s)
Interestingly I actually managed to shave 400kb off of that PNG by just running it through some PNG optimizers. Not great savings but were still some to be had!
Can be made smaller for sure, but if I'm say working with 10,000 images in my app and decoding all the time, a 3-4x speedup in the decode time can be a major saving for ~ 10-40% increase in file size with a lib I can just drop in my project without effort
I have a honest question about the source code, a lot of time since I coded anything meaningful in C, but I remember the header files did not have that much code on it, while here I see most of the code is in the header file. Why is this the case? Inline compilation? What are the advantages?
There's an important difference between STB-style 'single file libraries', and C++ 'stdlib-style' header-only-libraries: STB-style libraries put the implementation code into a separate section inside an "#ifdef IMPLEMENTATION" block, while most C++ header-only-libraries use inline code (and thus pay a higher compilation cost each time this header is included).
STB-style libraries skip the implementation already in the preprocessor and compile the implementation only once for the whole project.
So what's the compelling reason to ship these as a single source file, instead of using the more logical and standard solution of a single header and a single source file?
Unlike C++ header-only libraries, C libraries like this still need their implementation included exactly once.
I understand the benefits of keeping the implementation in a single source file (simplifies integrating in existing build systems, interprocedural optimizations, etc.) but combining the source and header files too makes them awkward to use, with little benefit beyond being able to claim "our implementation is only 1 file!" which is about as impressive as saying "our implementation is only 1 line!" if you've just deleted all the whitespace.
> So what's the compelling reason to ship these as a single source file, instead of using the more logical and standard solution of a single header and a single source file?
C doesn't have a packaging format or dependency manager, so having to keep track of two files would be pretty cumbersome.
In general, STB-style headers simplify C/C++ build system shenanigans.
E.g. one benefit is that you can configure the implementation via preprocessor defines without the defines leaking into the build system. Just add the config defines in front of the implementation include.
It's also trivial to write "extension headers" which need to directly peek into the (otherwise private) implementation of the base library. Just include the extension header implementation after the base library implementation.
> It's also trivial to write "extension headers" which need to directly peek into the (otherwise private) implementation of the base library. Just include the extension header implementation after the base library implementation.
I'm not sure what this means. Can you give an example? Is this being used in the above library?
> Why not two files, one a header and one an implementation? The difference between 10 files and 9 files is not a big deal, but the difference between 2 files and 1 file is a big deal. You don't need to zip or tar the files up, you don't have to remember to attach two files, etc.
This is kind of nonsense to me. The difference between 2 files and 1 file is barely relevant, and doesn't weigh against the awkwardness of having no clear distinction between declarations and definitions, and having to pull in definitions by setting a magic preprocessor header.
> Any better than the two-file version:
> #define LIB_KNOB 123
> #include "lib.c"
See, now you have 3 files, the .h/.c file pair of the library, and your own implementation source file with the configuration which includes a .c file. How is this better than having two files?
> Too vague. How is it better, concretely?
I can only assume from that question that you haven't had the "pleasure" to work much with C/C++ build systems yet, at least when it comes to integrating 3rd party libraries.
Since the implementation of the base library is in the same compilation unit as the extension library, the extension library has direct access to the private implementation details of the base library without having to add a separate 'private but actually public API'.
> no clear distinction between declarations and definitions
STB-style libraries have this clear distinction, C++ style header-only libraries don't.
> See, now you have 3 files, the .h/.c file pair of the library, and your own implementation source file with the configuration which includes a .c file.
The third source file is what the library authors suggested; I'd just create a seperate Makefile target for the implementation, which is then linked into the binary. (Yes, that's an extra target, but that costs very little and allows you to avoid unnecessary rebuilds.)
Why don't you give me a concrete counterexample where the single-header-setup makes things simpler? If it's so obviously beneficial it shouldn't be so hard to come up with a concrete example.
And you've saved a line (and removed the need for obscure preprocessor macros).
> ... without having to add a separate 'private but actually public API'.
Personally, I'd say this is exactly the right way to model this, but even if you disagree: it sounds like this simplifies things mainly for the library/extension authors, and not the library users, because if the extension author forward-declares the implementation details they depend on, there is no additional file to manage for the users either.
Boost or C++ stdlib headers are different than STB-style single-file-libraries though in that the implementation code is inline and needs to be parsed each time the header is included.
The original C++ templates used to be entirely contained in the headers. I assume that is no longer the case, but it has been a long time, since I wrote C++.
When I was writing template SDKs, the headers were pretty much the entirety of the library.
Single header libraries are hugely more ergonomic and easy to use. Just get the file, #include it and you're done! Most C libraries on GitHub prefer this mode of distribution now
>> Single header libraries are hugely more ergonomic and easy to use. Just get the file, #include it and you're done! Most C libraries on GitHub prefer this mode of distribution now
I find that odd. How is that significantly better than dropping 2 files into a project and #including the header? A good build system should just compile all the C or C++ files in a given place, so nothing needs to be changed other than dropping the files in and #include where called from.
The difference will be painfully clear once you try to walk a junior developer through installing and linking new files to a large project in Visual Studio, vs "copy this .h file here and include it".
Whether or not a "good build system" should handle it, the fact that single-file libraries are much preferred these days should demonstrate most people don't have such a build system
So much of the C/C++ ecosystem revolves around knowing your build tools that, for most intents and purposes, it should honestly be considered an integral part of the languages. If I ever teach an introductory C/C++ course, I would dedicate at least 1/4 of my time to explaining:
* What a translation unit is, and how compiling a translation unit to an object file works
* What a linker is, and how the linker combines object files into a library/executable
* What make/autotools/cmake are, and how they work
* What FHS is, and how it standardizes the lib/bin/include paths that C/C++ build tools read from/install to
And so on. Any C/C++ course that goes beyond a “Hello world” program without explaining these concepts in detail does its students a disservice.
Yeah, in our class we had to figure out this mostly on our own, so after it I'm still at the level where I barely manage to make make work, I'll have to look into those other ones, thanks !
but also ask "why are the tables of content prefixing the contents of all my books?"
its taken ages, but with this model, c lib authoring has finally taken something that was a core strength of pascal: single-file modularity.
though in theory there's no difference between theory and practice, in practice, there is. and this kind
of packaging makes a lot of sense for a lib like this.
1) Include it wherever it's used. The convention is to use the preprocessor[1] so it only appears once in the final binary
2) Most developers just want to compile to a single binary. Any developer who for some reason needs separately compiled objects should be able to quickly achieve that from a single-file library
Maybe you've been living under the same rock as me. I was under a similar impression untill I decided to learn cmake last week.
I was blown away by its simplicity and power.
You can download almost any C/C++ library from GitHub then add two lines to your cmake file. It will then compile and link with your project.
Blown away.
Cmake can generate project files for Visual Studio, makefiles, and countless other formats. Better yet, you can open a cmake folder directly in Visual Studio. No need to generate a project :)
This comes as no surprise to anybody, I'm sure, but cmake is great.
It was tricky to find good information about it though. It has been around forever, but the nicer features were added recently it seems.
>I can almost picture the meeting of the Moving Picture Experts Group where some random suit demanded there to be a way to indicate a video stream is copyrighted. And thus, the copyright bit flag made its way into the standard and successfully STOPPED MOVIE PIRACY BEFORE IT EVEN BEGAN.
I rather wonder if things like this are used to encode a proof of intent.
If something is marked as copyrighted, it may be trivial to remove the mark, but at least you had to remove the mark, and that's evidence of intent rather than ignorance.
I'm not arguing in favour of it, I'm hypothesizing why it might be added.
Your toolchain should set the bit last thing before distribution, I'd expect.
If you're talking about a toolchain on the consumption side after distribution, well, consumers shouldn't be modifying content, is what I'd expect the position to be. No derivative works and all that.
I was wondering the same with the COPYRIGHT note at the top of all files in a code repo.
Clearly someone that have the code can easily remove the COPYRIGHT header but then it will demostrate they had actively red it and decided to remove it.
Plus if you add the copyright header in many places it might be forgotten in some.
He might be referring to the hundreds of pages (and very complicated implementations, usually of encoders) video formats have.
People think of technology as a straight line moving forward. But it's perhaps better to imagine like species in nature. It's just everything getting bigger. The smallest ant or bacteria evolves to better adapt to its niche, as the largest elephant or whale will develop adaptations (sometimes getting physically larger, depending on the environmental changes). The rule is that many scales have a role or niche. I think technology is similar.
What I like about this approach is that it requires zero differential calculus. People forgot that Radix2 DCTs come from a century's worth of advanced math in the S domain. This approach is applied-computer-science based, I can get my head around that a lot better than a Laplace/Z transform.
But what shocks me is how did absolutely no-one apply such a naive RLE in the 30 years of internet image formats?
Is this a case of "man reinvents wheel again because why do research" or is this exceptional?
RLE on runs of deltas is in very many compression schemes; it's a common technique (probably so common that many authors don't deem it worth mentioning). Lossless video codecs in particular (huffyuv, lagarith, utcodec, etc.) have had this going back 20 years at least.
we applied rle encoding for time-series and triac control systems 43 years ago after getting some guidance from a mainframe guy - but since RLE is practical so that we even use it to give direction to people on the street, its probably so old that its even found its way into the way our genes are encoded. :D
Just to add to this list, even MacPaint used RLE on a per-scan line basis. I recently wrote about decoding MacPaint files[0]. So, replying to the gp post, yes it is in a sense reinventing the wheel. But sometimes the wheel needs to get reinvented because you have a new vehicle that could use a different type. And I would say the original poster felt he needed part of the modern wheel without the tire, so he had to go back to earlier wheel designs in a modern context. Okay, I've stretched the analogy too far!
This is pretty neat. A lot like the filtering done in PNG, just without slapping zlib on the result. As far as SIMD goes, I agree with the author and don't see much potential, as instructions are variable-length and most instructions encode deltas. It's probably quite close to optimal by just letting the CPU figure it out on the micro-level.
If each line were encoded independently they could be en- and decoded in parallel (once you add a skip instruction to tell where the next line starts, this does preclude streaming of intra-line output though). The hit to compression ratio should be small as long as images are wide enough for the color buffer reset to not matter.
I suspect SIMD would help with the encoding. The lookup table is small enough to fit into 8 AVX2 registers, so instead of hashing, you could use direct lookup, which would improve compression ratio further (a little bit).
SIMD registers aren’t indexable (at least not on AMD64), the register needs to be known to the compiler.
Lanes within each register aren’t indexable either. The insert and extract instructions are encoding lane index in the code. There’re workarounds for this one, like abusing vpshufb or vpermd, but with that amount of overhead I doubt SIMD will deliver any profit at all.
There are some clever tricks that can be pulled with the latest instructions sets like AVX-512. The registers are huge and the instructions available are so varied that there are clever ways to use them in "off label" ways to implement lookup tables and bit-level parsers.
Funny meta comment: when I read "offering a 20x-50x speedup in compression and 3x-4x speedup in decompression" I caught myself reacting with disappointment to the "only" 3x-4x speed up. This is funny because 3x improvement is enormous; it's just small compared to 30x. There's a lesson somewhere in there about sharing stats together to achieve an emotional effect.
One thing I did recognize after my last trip into the rabbit hole - JPEG can be the fastest format by orders of magnitude if you are using an appropriate encoder. The project mentions 20x-50x speedups over PNG which are commendable, but once you throw LibJpegTurbo into the mix (it does use SIMD), you will find a substantially different equation on your hands. I can do 1080p 4:4:4 JPEG encodes in ~3ms on my workstation today.
I am not saying you should always use jpeg (some people like to keep all their original pixels around), but if you want to go really really fast you should consider it. The latency is so low with this approach that I have been looking at the feasibility of building a streaming gaming platform around it. Current status of that effort is somewhere between "holy shit it actually works" and "maybe?"
I am in awe with how the post neatly interleaves the why and the how. Having recently implemented L4 decompressor (itself a rather reasonable and "lightweight" standard), I like the QOI even better. Hoping to see the video decoder author mentions as possibility!
This code is nice for RGB, but what about YUV420 format? There should be even more efficient way to store image in YUV420 (takes half bytes than RGB 888), and most images (JPEGs, direct cameras output in Android etc) are already in YUV420.
I wonder if auther has tried YUV420 already and failed for any reason ...
This is pretty neat! The compression rates and encode/decode rates are impressive for such a simple rule set.
> SIMD acceleration for QOI would also be cool but (from my very limited knowledge about some SIMD instructions on ARM), the format doesn't seem to be well suited for it. Maybe someone with a bit more experience can shed some light?
I don’t know about SIMD encoding, but for decoding at least, the core problem is to make some unit of the image (pixels, scanlines, blocks, etc) independently addressable (readable). The current format is complicated due to pixels of different sizes; there’s no way to know where data for pixel 1000 starts without reading all preceding 999 pixels. You could build a prefix-sum array of pixel indices, but that will fully undermine your compression.
One question might be how well does QOI work on independent scan lines or blocks? Is the compression still pretty good if the look-back window is limited in size and restarts every once in a while?
To make a GPU capable format, the very first thing you would probably need to do is separate the tag bits from all the other data, so a thread could identify the pixel type by direct lookup into the tag buffer. It then needs to know where to go to find the remaining data, so you’d probably need at least one byte of data that could be used to reliably locate the rest of the data. I don’t see an easy way to make this happen for separate pixels, but it might not be bad if the image is encoded in blocks or scanlines.
Yes, totally. Depends on your use case, but there certainly could be good reasons to keep images in compressed form even GPU RAM. It’d be ideal if decode is both random-access and predictable amounts of work per pixel. This format checks the predictable work box, but would need a little design to make it random access.
I wonder if the author tried making pixel diffs capable of using lookback. They'd be one byte longer but would possibly happen a lot more often than full pixel values. It's also reminiscent of the delta blocks from MPEG. If anything I would trade the 5-bit run for delta-from-lookup on a whim (the cases where the ratio between short runs vs. exact lookback is extreme seems like it might only happen for pinstripe patterns). I should probably implement the change and test it before posting...
The hard part here is figuring out which pixel to diff to. You would almost certainly have to look at all 64 pixels which would be a lot slower. That said, you can probably get noticably better compression from it.
I think O(log(M)) where M is the number of remembered pixels. Index them by their (R,G,B,A) quad and do a range lookup sequentially by pixel, since any valid pixels would be within the same range as earlier potential matches.
Why not separate the format for RGB vs RGBA based on a header? Since images will never have both RGB and RGBA pixels, you would be able to get an extra few percent encoding by using different (and conflicting) tags for the two types of images. For example you could have QOI_COLOR_RGB which would use a 5 byte tag and QOI_DIFF24_RBG could store 7 bit differences for 2 colors and 6 bit differences for the other color. For RGBA, you could do something similar for the two tags that are RGB specific.
Or even based on a #define if one didn't want to check a bit flag every time you need to encode a full pixel. Would not be difficult to have two versions of the library -- one for RGB, and one for RGBA.
Very cool.
Typo: "I barely understand how Huffman Coding and DTC works"
I guess you mean DCT? (discrete cosine transform)
One other thought:
To make it so that compression and decompression can be multithreaded, you might want to 'reset' the stream every N rows. (i.e. break any RLE runs, start from a colour literal). This would allow a bunch of threads to start at different places in the image, in parallel. There would be some small cost to compression ratio but might be worth it.
Before you start rolling this into a video codec, please consult the sources of UT Codec, which has been state of the art in this space for many years. Or, at least, use UT Codec as a direct basis for comparison, to see if you are beating it in terms of compression/decompression speed.
Modern lossless video codecs don't care that much about saving space, since you're burning gigabytes per minute anyway; the key is that the compression and decompression are as transparent as possible, to reduce the bandwidth to/from the storage medium. A good lossless codec can be used to scrub through and edit on a video editor's timeline, so decomp performance is what's most important.
Also, any such lossless video codec is going to need more than 8 bits per component; most real-world footage coming off of phones and cameras is 10-bit Rec.2020. If it is too difficult to position QOI for real-world sources, you can certainly keep it 8-bit and market it as an animation codec or similar; just keep it in mind.
Even better might be breaking it into tiles, so you get some vertical locality happening as well as horizontal.
It would be interesting to know which strategy is used for each pixel. Have you tried making maps of that with four different colours? Particularly interesting would be how much the cache is used and also how often it replaces a colour that it could have used later. Maybe there's a better colour hash. BTW you might want to change "(really just r^g^b^a)" to "(really just (r^g^b^a)%64)".
I really like the trick of caching previously-seen pixels by value rather than position. Very nifty!
I was thinking this would combine well with progressive rendering (i.e. store pixels in mipmap-style order) so the cache is warmed up with spread of pixels across the image rather than just scanline order. That doesn’t make it parallelizable in the way tiling does, though, hmm.
Another tweak that would probably help is having the file specify a rotation (or even a full mapping table) for each component of the hash, so a clever encoder can pick values that minimise collisions. (A fast encoder can just use all-zeroes to get the same behaviour as before.)
00xxxxxx - copy (x+1)-th last EXPLICITLY ENCODED pixel (i.e. ignoring repeats)
010xxxxx - repeat the last pixel x+1 times
011xxxxx xxxxxxxx - repeat the last pixel x+33 times
10rrggbb - copy the last pixel and adjust RGB by (r-1, g-1, b-1)
110rrrrr ggggbbbb - copy the last pixel and adjust RGB by (r-15, g-7, b-7)
1110rrrr rgggggbb bbbaaaaa
- copy the last pixel and adjust RGBA by (r-15, g-15, b-15, a-15)
1111RGBA [rrrrrrrr] [gggggggg] [bbbbbbbb] [aaaaaaaa]
- copy the last pixel and replace RGBA if each bit flag is set
So it is essentially the PNG filter limited by Sub, but offers better delta coding and a larger history window. My guess is that it might not work well if the image has a strong vertical gradient (which would need the vertical context), but nevertheless it's pretty impressive that this simple coding is not as inefficient at all.
You might be able to do better compression by traversing the pixels in Hilbert [1] order or Z [2] order, to take into account vertical neighbours as well as horizontal. It might cost time or space though, as you couldn't stream the pixels through it anymore - you'd need them all in memory.
You could still stream the pixels, you'd just have to stream them in Z order. This may seem pedantic, but this applies to any mismatch between the order in which you store pixels and the order in which the format stores pixels.
E.g. some file formats may be row-major, others column-major, some block-based (like JPEG) or a fancy interleaving scheme (like Adam7). Some might store the channels interleaved, others separate the channels. If any of these choices doesn't match the desired output format, it breaks streaming.
The nice thing is if M >= B^2 (i.e., total memory is large enough to fit a square region of the image, where each row/column of the square fits a full block/page of memory), you can transform from row/column order to Hilbert/Z-order without needing to do more I/Os.
So you can't do such a conversion in a streaming fashion, but there is no need to load all data in memory either.
Yeah, those images explain it pretty well. There is one slight difference, though.
Because the Hilbert/Z-order curves are defined recursively, algorithms for converting between the curve and row/column order are "cache-oblivious", in that they don't need to take an explicit block size. You write it once, and it performs well on any system regardless the CPU cache size and/or page size.
I wonder if the pixel data were transformed to/from a different order, before and after the compression/decompression, if that would speed things up without introducing too much slowdown of its own?
Iteration order through arrays has a big impact on performance due to cache effects. I'd guess that you'd lose a lot of performance by a complicated iteration scheme.
So I implemented this change and tested it out. Turns out, in my simple test suite, this actually changes the size of images. Not drastically. Often just a 5-10 kb difference (on a 500-600kb file), but that's still more than I expected for changing r-15 to r-7.
Suggests the DIFF16 delta-color mode is responsible for quite a bit of the savings. Maybe it would be worth experimenting the exact encoding.
One idea would be to start a predicted color (calculate the delta of the previous two pixels, apply that, then specify a delta to that). Another would be to encode the delta in YUV or some other color space, and then experiment with the best balance of bits between those channels.
Perhaps it would be better to steal bits from RUN16 instead, I somewhat doubt it's usefulness.
I see it as a variant of LZ specialised to images, so its performance should not be too surprising. Running an uncompressed bitmap through a general-purpose compression algorithm tends to yield similar results to PNG.
This is so neat. Reminds me the recent LZ4 post who manually hand tweaking the encoding one could still create a decent compression boosts after all these decades.
Is it just me, or is the compression algorithm not really less than the one in PNG? I will grant the author that if you don't need features like support for color spaces, different bit depths or interlacing you can skip the entire container format. But for reference this is the core part of png:
For each scanline write one byte for the chosen filter method, then $width pixels. There are five filter types. In type 0, write the pixels unmodified. In type 1, write the difference to the previous pixel. In type 2, write the difference to the above pixel. In type 3, write the difference to the average of the above and left pixel. In type 4, write the difference to the Paeth predictor (a simple function calculated from the above, left and left above pixel). Then compress everything with deflate.
Obviously by modern standards that isn't performant, not least because deflate sucks by modern standards. But it's simple, can be implemented in a couple lines of C (if you pull in deflate as dependency), and if you don't do exhaustive searches for the best compression it can certainly run in O(n)
The 64-pixel lookback makes it a bit similar to LZ-style compression like Deflate, but the latter is not O(n) because it can recognize multi-pixel sequences. QOI is just a slightly beefed up run-length encoding.
Are there compression algorithms that take longer than O(n)? My impression is that even two-pass encoding is O(n) with a large constant factor in front of it, but I’ve never actually thought this much about it.
Some LZ variants such as LZ77 and LZW are O(n), but LZH, for example, is O(n*logn) because of Huffman encoding. I agree that O(n) is not revolutionary, but the simplicity of this algorithm makes it faster to execute.
Did you try fuzzing your implementation (e.g. with AFL++ or libfuzzer)? Codecs and especially decoders written in C that handle untrusted binary data are quite worthwhile targets for fuzzing.
I immediately thought of a use-case for (a modified version of) this: raw compression in cameras.
Currently Sony has two options. Uncompressed raw that is huge, or lossy compressed raw that is half the size. They probably chose those options because throughput when shooting quickly matters a lot, so something like PNG would slow down shooting too much.
I imagine a blazingly fast halfway decent compression algorithm would be great. It might even speedup shooting by needing to write fewer bytes. But in general people taking star pictures will love having compression without it being lossy.
For reference an uncompressed raw file for 44MP is about 90MB. That starts filling up drive space rather fast.
I don't think this method fits camera raws particularly well. The real world is noisy, so it becomes very unlikely that you would ever hit the two most compressible methods of QOI, (1) pixel value repeat or (2) index into one of the previous 64 pixels. QOI works really well for 8-bit screenshots, with lots of pixel-values repetitions. No such luck in noisy 14-bit real-world images.
Also, this format was designed to be as simple as possible, and is byte-aligned, only handles 8-bit RGBA. You would need a different design for 12/14-bit RGB or RGBG (Bayer).
Lossless avoids all those issues around human perception. Also, if you're storing game assets, some of what you're storing as images is not really imagery. It may be normals or height fields, which lossy image compression messes up.
The code is interesting, in that it iterates over the output array, not the input. This helps prevent write buffer overflows. It has read buffer overflows, though. You can craft a compressed file which, when decompressed, will contain info from elsewhere in memory.
It checks for running out of input but, at line 460, will read three bytes beyond the end of the buffer for suitably constructed input. This is technically wrong, but hard to exploit.
Amusingly, if you run out of input too soon, the last pixel is replicated to fill the buffer. So you don't get random memory contents in the output, which would be more exploitable.
I still don't see it. Note that there is 4 bytes of padding at the end of the image data to simplify the bounds check in the decoder. Those 4 bytes are subtracted from the chunks_len that the pixel start bound check compares against. So you could craft an image where the last pixel runs into that padding (which the encoder won't produce since it always pads with the full 4 bytes) but not one where the pixel data is read from outside the image buffer beyond the padding.
So it looks like the algorithm diffs neighbouring pixels, assume that the difference is likely to be small, and encodes the difference in 1, 2, 3 or 4 bytes. It does this without complex things like huffman trees and therefore got a major improvement in performance while approaching the compression ratio of zlib. That's interesting.
Super cool work! I was also mucking around with codecs last week. I got some surprisingly good results from delta encoding each channel separately and then zstandard compression. Dirt simple, crazy fast.
One trap to be aware of when profiling image codecs is not knowing the provenance of the test images. Many images will have gone through one or more quantization steps. This can lead to impressive compression ratios, but if you compare with the results on raw, unquantized imagery, it's less of a slam dunk.
That said, PNG is a really low bar to clear, both in terms of speed and compression ratio. Even really image-naive compression algorithms tend to be within a factor of 2 in resulting compressed size. You tend to get diminishing returns. 10% vs 20% is twice as efficient, but starting with a 10MB file, 1 vs 2 MB file sizes isn't a huge delta. (yes I know there are domains where this matters, don't @ me).
> Super cool work! I was also mucking around with codecs last week. I got some surprisingly good results from delta encoding each channel separately and then zstandard compression. Dirt simple, crazy fast.
My understanding is that this is one of the techniques that png uses (though not zstd) for doing it's xompression too. Along with I think some different strides down the image and some other stuff but I don't fully understand everything it tries. That's what optipng and friends play with for parameters to find the best settings for decomposing the image for compression.
If you look at what jpeg and similar codecs do they nearly take a DC offset out of the image because that difference then greatly reduces the range of values you have to encode which means that you need fewer bits to do so. Combine that with range or arithmatic coding and you can get decent efficency for very little work. Then with lzw, zstd, etc. You can get lots of other patterns taken out and compressed. Lossy codecs try to take out the stuff we won't see with our eyes so that the set of values to be encoded need fewer bits and it'll also make more patterns appear that can be exploited too
Yeah, my technique was equivalent to filter mode 0 (the only mode), filter type 1 (sub pixel to the left). literally array.ravel().diff(prepend=0) in numpy.
I think part of the reason png is so slow is that it empirically tests to find the best one.
> Compression is further improved by choosing filter types adaptively on a line-by-line basis.
I'd be curious to unpack a png and see the statistics of how much each kind is used.
This is a great project, but personally I feel that there are lots of uses for uncompressed images (ie. random access, ready to render straight away), and lots of uses for well compressed lossless, but little use for 'slightly compressed' images.
The normal argument for 'slightly compressed' images is that they can be decompressed with very few CPU cycles, but the reality is that with modern platforms lossless image en/decoding is done in hardware and therefore pretty much 'free', as long as you pick lossless h264, lossless webp or lossless hevc. All of those things will also give much smaller file sizes.
In the few places where hardware decode isn't a thing (eg. the memory-constrained 8 bit microcontroller decoding the boot screen for your IoT toaster), there usually isn't a need for losslessness.
> The basic ideas for video compression in MPEG are ingenious, even more so for 1993, but the resulting file format is an abomination.
can confirm.
Although the worst part is the documentation is in engineering english, so its quite hard to understand. MPEG2 is actually not as bad as you'd imagine. MPEG4 is.
Interesting I have the opposite view. From intuition I would think there is an unbounded set of simple compression algorithms. You can probably make much more effective simple compression algorithms by making basic assumptions about the type of image.
This is patently so. Taken to absurd proportions, you can compress a specific rendition of the Mona Lisa with just one bit. 1 means Mona, and 0 is undefined behaviour.
Taking this a step further: 0 means that all subsequent bits contain an arbitrary PNG. Now your algorithm encodes any image, and still does Mona Lisa in one bit.
Well, this is a combination of simple approaches which have all been used before, though put together in a nice way. And it's not benchmarked against modern formats like lossless webp or jpeg-xl.
I am not familiar with image encodings, but isn’t the idea of complexity relative? For example getting rid of Hoffman encoding and byte aligning everything may be less complex for computers, but when making energy and area efficient hardware, we may not care that much about some of these things?
By the way, this image format can match PNG in terms of size if combined with another form of lossless compression, so if we allow for that extra complexity, something like QOI + Zstandard could possibly compete with PNG in terms of both size and speed.
I like the small size of the decoder state - not much more than 256 bytes. I haven't found a way to decode GIF with less than about 16k of mutable state. PNG is similar though you can use the decoded image if it's available.
Just came here to say, good job. I was doing my own run-length encoding thing using the TGA format, but this is nicer. It's good enough that I am able to run a little screencast thing using it.
Very much this -- it will unfortunately have a horizontal bias if done naively, but I've been exploring the space of doing lossy preprocessing to improve image compression, but the layered heuristics in png make this difficult. This format is simple enough that we have a number of approximation heuristics -- find the closest color in the last 64, use a smaller delta, or preserve one or two channel colors in the next pixel.
Notably, pixel similarity along a particular order. If I understood correctly something like a vertical rainbow would compress significantly different than the same picture rotated.
No, the encoder checks if the color at the hashed value really matches before storing the QOI_INDEX. There's probably better ways to hash it, but this just seemed "good enough".
There are a lot of better-than-JPEG and better-than-PNG solutions out there.
Speed: If the benchmarks are correct, then this is exceptional, especially considering that the file size is only slightly larger than PNG.
I can think of a couple of ways they could reduce the file size by probably around 10%-20% without sacrificing speed, but this is good enough to get attention.
The biggest speed loss for PNG comes from zlib.
PNG without zlib is very fast -- probably comparable to QOI.
If QOI use bz2 or even zlib on top of the current encoding scheme, then it would be slower, but I bet it would also be smaller than PNG.
The biggest issue isn't making a better/faster picture format.
Rather, the biggest issues are adoption, metadata, and variable color support.
Until web browsers and smartphones natively support the format, it's only good for a proof-of-concept or for niche applications. (Don't get me wrong -- online games could benefit from something like this.)
Wide-spread consumer adoption will also need support for metadata. EXIF, IPTC, XMP, ICC Profiles, etc.
This is easy enough to add. I hope the author choose something simple, like a tag-length-data. The tag just identifies it as a meta block. The data should begin with a text string and "\n" that defines the type of data, followed by the binary data. The "length" includes the size of the data + string + 1 for "\n". Also, be aware that some metadata is larger than 65535 bytes, so the length should support large data blocks.
The algorithm as currently defined only supports 8-bits per channel and 3 or 4 channels (RGB or RGBA).
For widespread adoption, it should support:
- 8-bit Grayscale (1 byte per pixel)
- 16-bit Grayscale (2 bytes per pixel)
- 8-bit Grayscale + Alpha (2 byte per pixel)
- 16-bit Grayscale + Alpha (4 bytes per pixel)
- 8-bit and 16-bit RGB (24 and 48 bytes per pixel)
- 8-bit and 16-bit RGBA (32 and 64 bytes per pixel)
- 8-bit and 16-bit CMYK (for the printing industry)
- 8-bit YUV (for cameras; most also support 16-bit YUV, but it's rarely ever seen)
I don't think the algorithm will change for these, but the file format will need a header that defines the color space and color depth.
The source code is also problematic. For example, the .h (header) file contains functions. Not function definitions, but actual functions. E.g.: https://github.com/phoboslab/qoi/blob/master/qoi.h
All functions (qoi_encode, qoi_decode, etc.) are completely included in this header file. It should be in a .c file (not .h) and compiled into a library (libqoi). Although C does permit you to put functions in header files, it is REALLY REALLY REALLY bad form and strongly discouraged. (This is a really bad programming practice. When I was in school, doing this sort of thing would be an immediate homework failure even if the code works.)
I came all the back from my Thanksgiving slumber just to say; really?
I love this library, and have made a C++ friendly version of the same.
What you get for a few hundred lines of code far outweighs any of the shortcomings it might have. It's a great starting point. If someone wants to make a full on format, they'll probably be better off just using the new JPEG XL, rather than trying to shape this thing.
It's a good exploration of what can be done with run-length encoding.
I'm wondering how scalable would this be for hyperspectral images, with 25 channels for example. I'm guessing it's just repeating the processing for RGB channels but for 25?
Very much the kind of expert group design-by-committee type of requirement that this simple compression scheme was designed not to handle.
Since this scheme works primarily on exact cross-channel pixel matches, no. No it won’t work well for 25 channel images.
Which is a good thing. Most people are not trying to encode 25 channel hyperspectral data and if they are they can use their own format designed well for that purpose (or a committee-derived format that handles it adequately).
Or they can split the 25 channels across 7 4 channel images and encode them using this.
I appreciate the premise to develop this, and the science that comes with it.
I cannot tell if the author is writing in jest or serious when he is rude to the historical work that was done before him, yet relies on. It comes across as hubris with no floor to hold him up.
Today's genius is often questioned and found to be a fool of tomorrow, and a bit of grace goes a long way.
Have you seen codecs? I've recently been exploring this space and there is not one corner of this universe that isn't a lurking Lovecraftian horror.
Un-compressed formats like BMP are sane I guess but most of those are wrapped in crufty, sparsely documented container formats. Ogg is decent but even it takes quite the deep dive to even begin wrangling it.
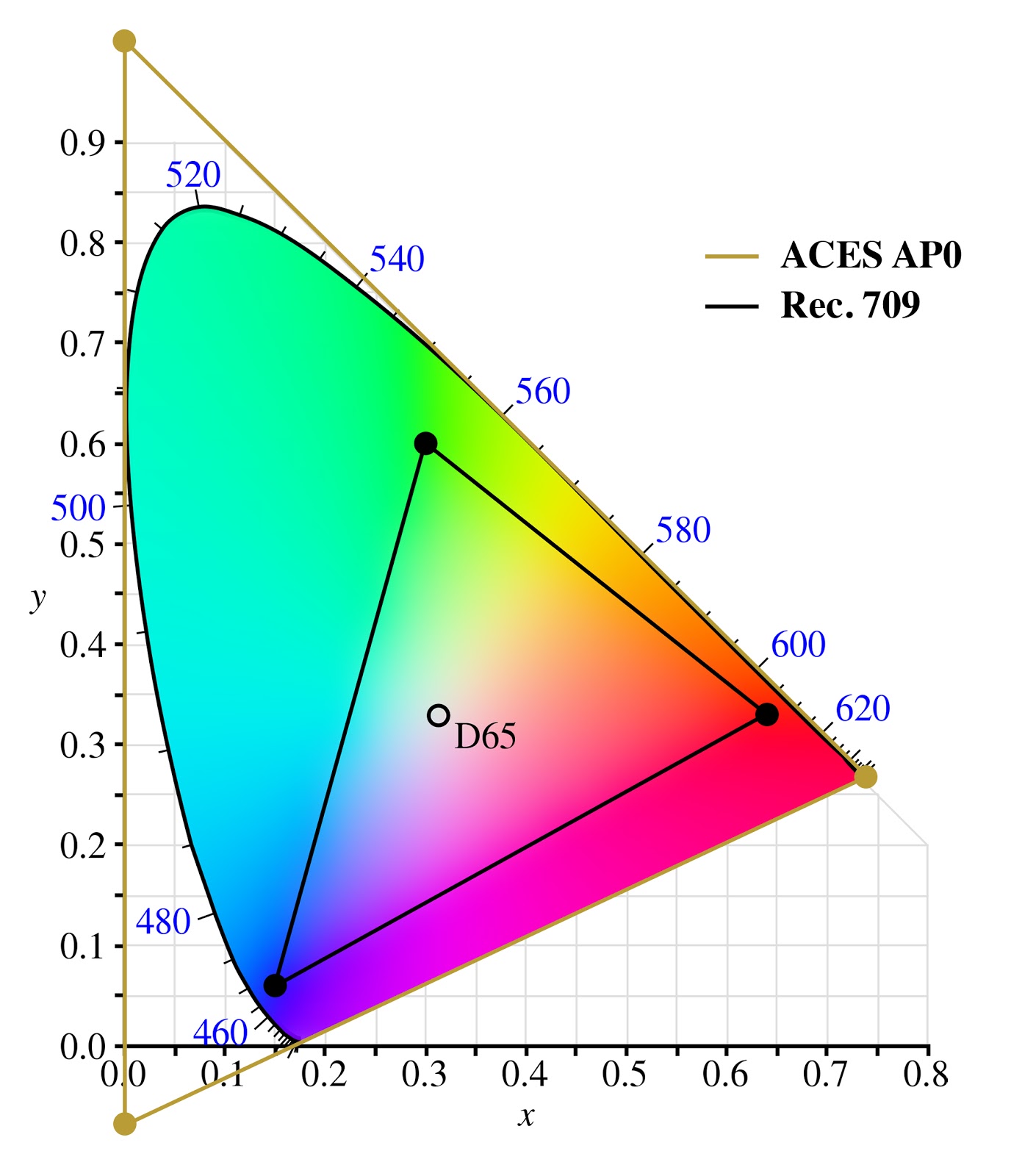{kind=link}
{kind=link}
Regarding the comments about complexity of existing formats - I agree, with the exception of PNG. In terms of complexity, QOI is very similar to PNG filtering phases, i.e. when you strip primary compression phase (Huffman coding) from PNG.
Also, I admire how the author combined a lot of common and cool tricks into QOI:
- Block tags form a sort of a prefix code, making it easy to differentiate block types with differing sizes
- Look-back array is used (common trick from LZW family)
- Delta-coding is used when storing pixel diffs
- In the end, if nothing else works, full pixel value is written
Also, the fact that everything is byte aligned is very appreciated.
This is a breath of fresh air and really impressive how good performance (both processing and size reduction) this gets with so little (very readable!) C.