Agreed, Jart's work is jaw-droppingly incredible, on the order of Fabrice Bellard's achievements.
However, I don't see "I wish I was born like this" -- their works encourages me to think and do lots of crazy shit. My previous limitations were just a lack of imagination and creativity.
SectorLISP also encourages the "do anything" viewpoint. The original version was published even though way larger than a sector. Other people contributed, sometimes only by publishing a related project (SectorFORTH). By having an idea and publishing something Justine created something unique.
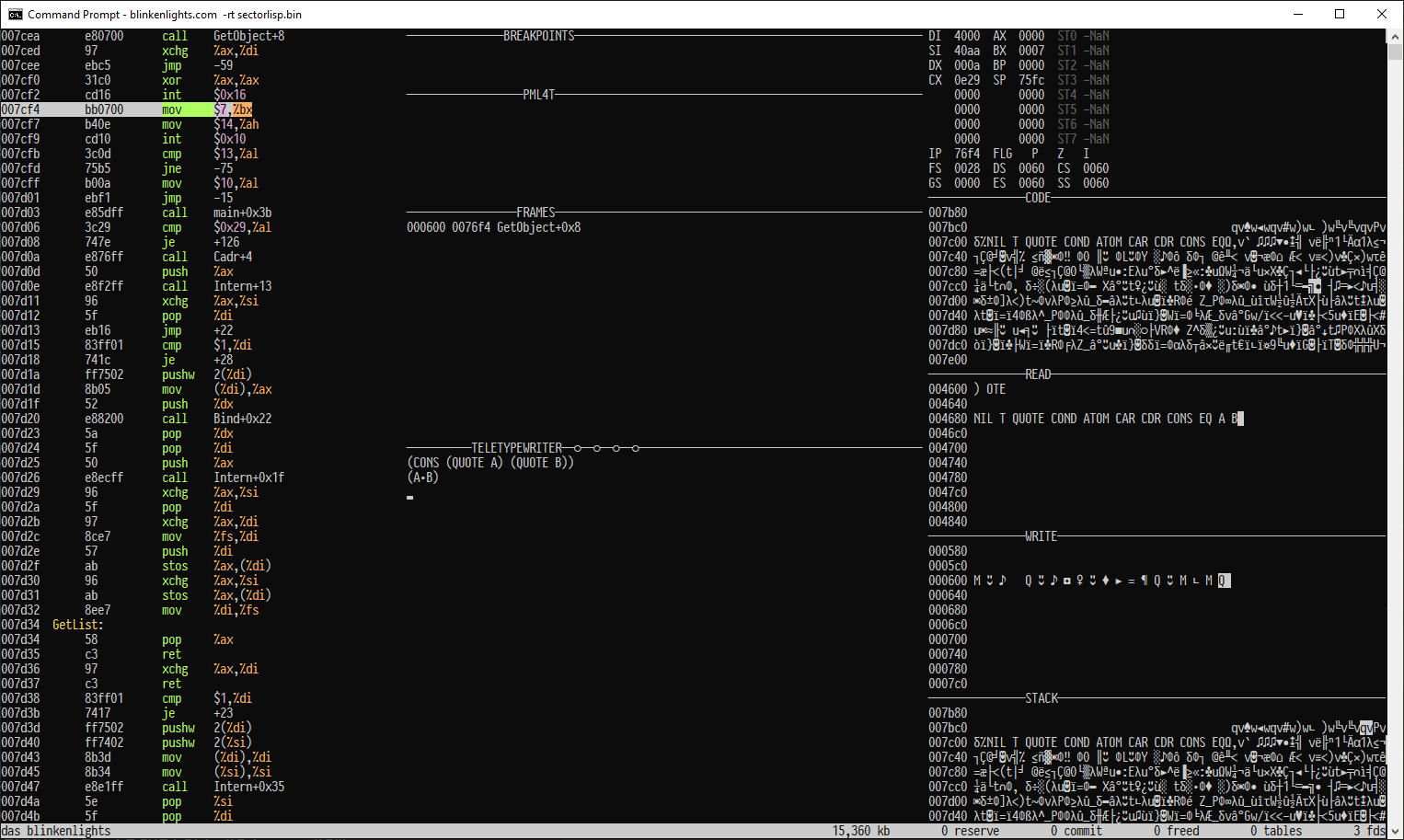
Lastly the above page shows the "run program and watch its memory in realtime" technique, which is incredible in itself. The tool is called Blinkenlights
https://justine.lol/blinkenlights/
It's a nice story about how sometimes the best way to ultimately succeed is to not be afraid to admit when something was tried and failed. By publishing SectorLISP in an unfinished state, I attracted a lot of smart people to the problem. Now that it's complete we can look back and say we did it.
In your defense, Justine's been at this for a long time! Give it time and effort, and you too can do amazing technical things. Potential isn't a concrete thing, it's a set point you can move around.
Throw yourself at the computer, and the computer will do interesting things with you, too.
If it's not working, go at it from a different angle. Sometimes it's helpful to go back in time to come across things. I'd argue that 90% of cool tech phenomenon arises from studying the past to make something cooler in the future rather than any force of sheer will.
A lot of Justine's projects seem to fit this mold (if I remember right she came across the idea for Cosmopolitan after finding that a legacy UNIX feature let you avoid specifying your shell; SectorLISP, McCarthy's metacircular, etcetera).
She even cites someone whose entire deal is doing precisely that: Nils M. Holm.
Yes, Justine's amazing. I have also been following and reading Nils M. Holm's books. I program in J/APL, and I picked up Nils' book on Klong, but I have not fully worked through it yet. It gives me a perspective on J/APL. His Lisp stuff is great.
I also wish to thank everyone here for the kind words. (Justine here btw.) Also Nils, awesome book! Glad I had the opportunity to cite it in the blog post.
Thinking about it, but writing a book is a large effort, I am not getting any younger and, to be honest, it is a bad idea from an economic point of view. My bestsellers, if you can call them that, sell about 30 copies per year.
> Sometimes it's helpful to go back in time to come across things.
Yeah, I remember her posting about the original Unix source code. I've never read it but I probably should. I bet there's plenty to be learned.
Sometimes I come across papers from the 70s and 80s too and they blow me away. It's amazing how much our predecessors achieved. Sometimes it feels like we're trying to rediscover or reinvent old technology.
If that were true then modern authors would just be guys trying to reinvent Shakespeare. As programmers, the programs we write can be art as much as it can serve a business utility. Some things progress but some things never change too, and each generation finds a way to express those things in a new and beautiful way. While learning to become a better programmer, I've found it helpful to read and be inspired by things like the UNIX source code, or texts written by guys like Vannevar Bush or John McCarthy, just as fiction authors might find inspiration reading the classics.
Why is this quoting the top-level lambda expression arguments? Unless I'm mistaken that's not how JMC did it. For example, to define a binding the cited resource http://www.paulgraham.com/rootsoflisp.html uses
(defun null (x) (eq x '()))
Replacing the defun with an env binding, I believe the value translates to:
(lambda (x) (eq x '()))
I don't think this should be quoted? Even though lambda isn't typically assumed in the "seven primitives," it _is_ required by the runtime. Are your function calls implicitly dropping quotes when evaluating arguments?
Author here. The quotes are indeed needed. Emacs does the same thing. For example:
((lambda (x)
(message "%S" x))
(1))
;; fails: no such function `1'
((lambda (x)
(message "%S" x))
(quote (1)))
;; prints (1)
The original evaluator is defined so that if the first item of a list, is a list whose first item is LAMBDA, then what it does is it calls Evlis() and Pairlis() which is sort of like a glorified version of Python's zip() function, to attach all the subsequent list items to the parameter name list.
This is the "venus fly trap" that the blog post mentions. The process of evaluation causes the expression the clamp in on itself where the args get digested into an association list which can be referenced and then the payload is evaluated. This was all non-obvious to me, even after using LISP casually for years, since we normally don't write code that way.
Now it's possible to add extra code to the evaluator so that if a naked lambda is encountered, i.e. it sees (LAMBDA ...) rather than ((LAMBDA ...) ...), it just lets it pass through, so you don't need the quotes. We did that originally, but deemed it non-essential and was removed, since that would have made it much harder to hit the 512-byte goal.
By Emacs do you mean Elisp? Your session there is not surprising to me. I don't have emacs handy but what does this do?
((lambda (f)
(f))
(lambda() 42))
You might need to throw a 'funcall in there or something, but my hypothesis is that this will work (return 42) without needing the top-level argument to be quoted. 'lambda is a deep special case, basically.
I understand that functions always zip through their arguments, evaluating each one. But when you quote the args in the call, I tend to expect the arguments to not be evaluated within 'evlis.
I'm surprised that quoting args makes the interpreter smaller! That's pretty interesting. But I think this interpreter will have some behavior that is surprising to anyone used to all extant lisps for examples like this:
((lambda (sym)
(cons sym 3))
(quote a))
Here there's no binding for 'a. I expect this to return (a . 3) in JMC's original Lisp.
The lambdas are quoted because they’re lambdas, not because they’re arguments.
In a more fully-featured Lisp, the code (LAMBDA () 42) would evaluate to a special function data type with no direct representation in terms of cons cells. That’s a luxury this implementation can’t afford, so its data representation of a function is the same as its code representation: a cons cell whose car is the atom LAMBDA. With this design, the code (LAMBDA () 42) would be self-evaluating: it would evaluate to the same thing as the code (QUOTE (LAMBDA () 42)). But since the latter syntax works, there’s no need to waste bytes supporting the former syntax.
In the absence of that special support, the default meaning of the code (LAMBDA () 42) is to call a function named LAMBDA, just like the code (FOO () 42) calls a function named FOO.
I see. Kinda. The 'lambda in the first line isn't quoted. And the eval itself seems identical to JMC. So this is just the substrate level and only when evaluating args? Does that seem right?
The only difference is that, since it's the root-level program, the binding of the name PROGRAM can't have happened yet. So it's simply inlined into the expression. The Apply() part of the evaluator has a special case for recognizing this, which causes evaluation of the first argument to terminate:
int Apply(int fn, int x, int a) {
int t1, si, ax;
if (ISATOM(fn)) {
switch (fn) {
case ATOM_CAR:
return Car(Car(x));
case ATOM_CDR:
return Cdr(Car(x));
case ATOM_ATOM:
return ISATOM(Car(x)) ? ATOM_T : NIL;
case ATOM_CONS:
return Cons(Car(x), Car(Cdr(x)));
case ATOM_EQ:
return Car(x) == Car(Cdr(x)) ? ATOM_T : NIL;
default:
// recurse to turn (FUNC ARG1 ARG2) into ((LAMBDA ...) ARG1 ARG2)
return Apply(Eval(fn, a), x, a);
}
}
// evaluate ((LAMBDA ...) ARG1 ARG2)
if (Car(fn) == ATOM_LAMBDA) {
t1 = Cdr(fn);
si = Pairlis(Car(t1), x, a);
ax = Car(Cdr(t1));
return Eval(ax, si);
}
return UNDEFINED;
}
The Eval() function which calls Apply() has already evaluated all the list items except for the first one, which is left to Apply() to figure out. The reason why things are this way is because, in order to save space, the REPL loop doesn't maintain a persistent set of global variables. Due to the NIL here, each expression is its own hermetic job:
void Repl(void) {
for (;;) {
Print(Eval(Read(), NIL));
}
}
If you changed that NIL to be an alist that's populated by things like defun / setq / etc. in the global scope, then the usability of the language improves dramatically. We didn't do it due to the singular focus on size. But at the same time that simply means we left fun opportunities for improvement to anyone wishing to hack on the codebase and make it their own.
> Why is this quoting the top-level lambda expression arguments?
I suspect mostly because the implementation stumbled into the dynamic binding/lexical binding/FEXPR traps that hit all the early Lisps.
> Here it becomes clear that, in its most bare essential form, beneath the macros and abstractions, LISP actually has an unpleasant nature where name bindings (or assignments) look like a venus fly trap.
Ayup.
A lot of these problems were addressed by the late John Shutt in his thesis about vau calculus in the Kernel programming language:
The "magic" is that the "$vau" operative closes over the environment when it is defined so that it can execute later in that environment--this is the "static/lexical environment". However, when you actually execute the "$vau" operative, you also pass in the "execution/dynamic" environment so that the code that the "$vau" operative runs can choose to do what it wants with the arguments--do nothing, evaluate them in the lexical environment, or evaluate them in the dynamic environment.
It's a powerful concept, but difficult to compile so got kind of relegated from the Lisp/Scheme languages.
For something which seems to implement it properly, see the "Oh" UNIX shell:
I would mumble that the fact that "list" is defined as "cons pairs with a final nil()" is also a pain in the ass. I understand why it was originally done this way, but it makes the idea of a "sequence" abstraction so very much more painful. It's one of the reasons why Clojure dropped it.
It's such a shame, but "Kernel" and "Oh" sort of drives home the fact that good ideas also need good marketing to propagate. "Oh!" is also a poster child for "videos suck for searchability and discoverability--post a transcript and your slides."
It's particularly bad with "Oh" because he has some truly nifty hacks. The pipeline that is reconfiguring itself as a filter while it's filtering is stunning. The "Transmit the code in one place and execute it in another" is also clever.
The thing that dragged me to Kernel was that I needed a small language to be able to debug embedded systems on the fly. So, the interpreter couldn't be hamstrung and I never had a compile step available. I needed both small code and small data.
Kernel, the idea, fits the bill. Kernel, the implementations, for some reason all really obscure the point for reasons I'm not particularly clear on.
Maybe once I've got it all clear in my head, I'll try to do an implementation in Rust. That should help keep things clean since you can't rely on "metacircular" tricks to implement things.
I'd love to chat more about it. Email address in my profile. I spent a few years getting inspired by Kernel when I built my fexpr-based Lisp: http://akkartik.name/post/wart So I'd be happy to answer questions as you have them. Perhaps we can pore over Shutt's dissertation together.
Not really on topic but I found myself looking around this website and this is easily the most interesting personal site I've seen on HN, and then from reading all the angry posts by the right people Justine also seems like the most interesting personality I've seen on here.
I also agree with you. My specialties are machine learning and knowledge graphs, very different than what Justine works on, yet I find digging into her posts fascinating.
Justine here. I used to work on TensorBoard and I contributed a few hundred thousand lines of changes to TensorFlow. These are my hobby projects so we might not be as dissimilar as you think :-)
Intel 8086 and 8088 did not have invalid instruction exceptions.
The opcodes that were not documented were either redundant, doing exactly the same thing as other documented opcodes, or they crashed the system.
Later, in 1982, 80186 and 80286 introduced invalid opcode exceptions, so starting with the IBM PC/AT any program intended for later CPUs should abort with an error message.
Most IBM PC/XT were made with Intel 8088, so the behavior of an 80386 program is unpredictable.
Some PC/XT clones were made with 80186 or 80188, or, more frequently, with NEC V20 processors. All these had invalid opcode exceptions, so they should behave like a PC/AT.
It's not too negative because to be honest it's something I felt guilty about. It looks we actually have enough room left to fix that, since we're not currently using %bp. We even have room to add the necessary push/pop for %bp to work around a bug in the original IBM PC BIOS implementation. If we make that change, then I've just confirmed with xed -r -isa-set -i sectorlisp.o that's it's pure i8086 and should work. One of us should pull out an old IBM PC and record a video of sectorlisp running on the original hardware. Anyone want to volunteer? I have one but it's difficult for me to use since I only know how to type dvorak.
Assuming you mean static code size, my Mu project currently supports an interpreted Lisp (macros, fewer parens, infix) implemented in a compiled memory-safe low-level language without _any_ C in 450KB. The "runtime library" (mostly in the safe low-level language) requires 120KB. Without unit tests, the binary sizes drop down to 200KB and 30KB respectively, which gives you some sense of the space devoted to tests in each case.
As the tests hint, Mu doesn't do anything to try to reduce code size. It's small just by focusing on the essentials. What's left is written for ease of comprehension.
(An example of "essentials": Mu still cannot free memory. I run my programs in Qemu with 2GB which seems to suffice.)
Author here. I assume you're referring to https://github.com/akkartik/mu/blob/main/shell/evaluate.mu? It's hard for me to tell, since there's 819k lines of code in Mu according to find . -type f | grep -v '\.git' | xargs wc -l. Does it have lambda and support metacircular evaluation? If not, then why do you think it's LISP-like? If you do nothing to reduce code size, then why do you call it Mu? (I assume by "Mu" you're referring to what UNICODE calls the MICRO SIGN.) 30kb is two orders of a magnitude larger. I don't see how it's relevant to SectorLISP.
Sorry to tramp over your thread! Mu isn't too related to SectorLISP, I was just responding to the side-discussion about what we can build in under 1MB.
To answer your question, evaluate.mu does support lambda (I call it `fn`). My estimates of size were based on `ls -l a.bin` after `./translate shell/*.mu`.
It that case it'd be really cool if you implemented John McCarthy's metacircular evaluator in Mu LISP syntax to demonstrate it's a LISP. Sort of like how when John McCarthy shared the idea for LISP one of the first things he had to do was show that it's able to do the same things as a Turing machine.
(I haven't done this so far because I find metacircularity to not be very interesting. It was interesting when JMC proved it could be done. Mu's whole reason for existence is linear rather than circular bootstrapping. We can disagree over whether I get to call it a Lisp or not, but if it has the full power of macros I'm happy.)
And Justine, if you want to join our ever continuing argument about bootstrapping processes and trust in programming language toolchains, Kartik is the right person to talk to :p
major points for having a thorough test suite, it has saved my a** on my own projects countless times, and I still encounter projects too often IMHO that have barely any test suite if any at all
Keep in mind that IBM PC/XT had only 640 kB, but there were compilers and interpreters for any language, which were available for it.
Moreover, before IBM PC, a CP/M computer with Zilog Z80 or Intel 8080 had usually only 32 kB or 48 kB, but you could use without problems Basic interpreters, Pascal, Fortran, Cobol and PL/M compilers and many others.
However, in order to fit in 32 kB, the compilers themselves were typically written using a macro-assembler, and not in a high-level language. The C language became popular for such tasks somewhat later.
And that's the maximum (without bank switching schemes like EMS). The first version had only 64 KB. There were even plans for a 16 KB version with no disk drive but I don't think it was ever released.
I love Red and want to use it more. Sadly my professional life keeps giving me hardware that I can't run it on, so Red is getting marginalized. I wish I had more skill and time to help them out with the 32 to 64-bit transition. [1]
1MB is really a lot if you know what you're doing, what language you actually can't fit into 1MB of ram due to inherent specifics of language itself, not because interpreter/compiler doesn't optimize for such cases?
Most then existing HLLs were very usable in 640Kb. If you go down to 8-bits, while translators for many of these did exist the utility was rapidly diminishing. You'd essentially have system's native version of BASIC + assembler for anything practical. The rest were more of parlor tricks.
This was back when 1 MB was considered and amazing amount of memory. It took two years to write this, about 50K lines of high level code and another 10K or so of assembly. Today you would approach such a project in a completely different way, you'd use much more time to make it look pretty and just that part would probably be much larger than the whole package that I wrote.
The funny thing is that even so many years later the original software is still in use in some places and there is a whole company centered around that core that has been re-written a couple of times to keep it up to date and to expand its functionality.
I highly doubt the present day version would fit in something that small. What's interesting to me is that that old stuff tended to be super productive to work with, zero distractions, just some clearly defined task in a clearly defined environment, if it worked it was bullet proof. No hackers, SaaS, a million connectivity options and no eye candy. Just that one job to be done and done as good as the hardware would allow you to.
But that's exactly my point. I think we forgot to aim at super productive, zero distraction, lightweight. And it would be of high educative value to see this sort of work again. Both on the small scale details and the pragmatic value.
The sad part to me is that most web apps reenact the same functions but in a css-transition-capable DOM. But functionally I'm not sure you get more.
Was still spooky downloading and executing the same blinkenlights binary on Windows and Linux (WSL). Unfortunately it doesn't actually work in either environment:
Error: your CPUID command does not support command 0x80000006 (AMD-style L2 cache information).
Author here. What are you executing? It works fine on AMD Ryzen for me. That error message doesn't appear in the blinkenlights.com binary. It also doesn't perform that CPUID check. The only place I can find that error message online is for a fizzbuzz codegolf. Perhaps you're confusing sectorlisp with a another project? Also, Blinkenlights should work fine in the Windows 10 Command Prompt. So WSL isn't required but it does run on that too. https://justine.lol/sectorlisp/spooky.png
Oh, silly me. I hadn't noticed you need the `-t` flag to open the TUI and assumed that since the TUI didn't open that the error was from blinkenlights.
Glad I could help. Hope you enjoy Das Blinkenlights. Press '?' for help. Useful shortcuts for controlling execution are 'c', 'C', Ctrl-C, Ctrl-T, and Alt-T. Memory panels can be scrolled with the mouse wheel. You can also zoom in or zoom out the memory display with ctrl mouse wheel, although that might not be available in CMD.EXE and you might need to use something like KiTTY, XTerm, or PuTTY.
{kind=link}
I once reached out to them personally to tell them I hope I can be like them when I grow up ;^)
On a serious note, this is one of the coolest things I've ever seen.
The person mentioned that helped them go from 700 -> 500 bytes, the said "Assembly Heisenberg" appears to be entirely obscure on GH too.
Seems like the right set of eyes just happened to find their way to the project at the right time:
https://github.com/agreppin
I wish I was born like this.