I can't help but think about what happened with graphics APIs - the older ones (DX9, OpenGL) held your hand more, and the new ones are super bare metal and not written for the faint of heart. I think most would agree this is better though; for an application developer you can simply use a much higher level library built on top, and for the library/engine developer you have a lot more power and control. The old APIs were in an awkward middle ground of not being particularly easy to use, but also not being nearly low level enough. Nobody was happy.
I think modern OS stacks are in a similar boat, at least Windows and macOS. True low level control is kind of a pain, but the OS libraries are not particularly pleasant or high level enough either. So largely things like Electron or Qt are acting as the defacto OS anyway to varying degrees of success but undeniable levels of resource waste. I wonder if modern languages and tooling and such are advanced enough that the OS should become more primitive and minimal. In a way it feels like we're moving there anyway with web tech becoming the defacto user space and toolkit. That's fine, but god if it wasnt all built on 50 layer of cruft our machines would be screaming fast.
Smalltalk, if you get a chance to use it, really does act like its own OS in so many ways. It's great as a programmers OS really, although it doesn't really hit the right notes for average use. Still though, if someone had the urge to build it I could easily see a smalltalk based userland built on like a linux kernel (with no gnu user space) being a totally viable thing.
>I think modern OS stacks are in a similar boat, at least Windows and macOS.
I come from a background as a EEE mainly writing embedded code before somehow stumbling into frontend code (in win32, Cocoa and Qt) at my old job.
From my experience, OS-Level APIs definitely have more in common with Electron or Qt than they do "bare metal". To make the top left pixel red on a bare metal system or RTOS, you simply write `framebuffer[0] = 0x00ff0000`.
For win32 or Cocoa, you need to create a window, alter its flags to ensure it's borderless, change its size and posistion to 1x1 and [0,0] (or [0, screen_height] on the Mac), strip away the drop shadow, respond to regular paint events and pray like hell that nothing else draws over the top of it.
>True low level control is kind of a pain
It depends on what you're trying to achieve. If you're trying to get something highly responsive that looks exactly like the UI spec, most libraries tend to make this job harder when the abstractions leak and you're forced to rely on bizarre hacks that make no sense and feel genuinely demoralising to implement.
Dear ImGui, which exposes far more of the low-level internals than any other API, is an absolute joy to build GUIs in and significantly easier than something which "holds your hand" at every step.
Making the top left pixel red just isn't something you should be doing in a GUI environment anyway, it doesn't make any sense. For something like that you should probably be dropping to a full-screen mode like most graphics heavy games anyway, in which case it's pretty easy on modern OSes.
The desktop GUI is just one subsystem in a modern OS, and you don't have to use it if you don't want to. If you do use it then there are tradeoffs, of course, but that's always true of anything you use.
One of the versions had the high scores saved in ini file (3.1? 95?). My dad was amazed I solved large one in 15s. Then he found it. Then I learned about the read-only attribute.
Dear ImGui does not support Arabic (right-to-left, glyph shaping) and will not support Arabic (https://github.com/ocornut/imgui/issues/1343). I don't think it supports accessibility either.
As much as I struggle with Qt's APIs (aging janky Widgets, half-baked QML on the desktop, the item models are an impenetrable byzantine enterprisey API that's simultaneously too open-ended, not flexible enough since it imposes its add/remove/move schema on your model, and too buggy), building a GUI from the ground up is not going to give you internationalization or accessibility, and Qt is.
Vanilla ImGui doesn't, but I both wrapped my head around and then rewrote the text renderer in all of 2 days as a junior dev.
This version could support arbitrarily many UTF-8 codepoints with kerning and all and had a negligible performance hit on the machines I tested on. I never upstreamed it (left the company before the product that was using it shipped, actually), but it wouldn't be too hard to reproduce.
That's what I love about exposed, lower-level frameworks like Dear ImGui.
We didn't aim for accessibility, but I'm sure that would have also been semi-trivial for a dedicated dev who understands what's required.
The other major thing missing in relation to that is input method support.
The problem with those type of APIs and accessibility is that implementing screen reader support basically means making it retained mode in some capacity, because accessibility APIs expect you to export a tree of objects and push state updates.
Looks like theirs is far more advanced than mine (mine would just generate a texture per string and cache it, the main problem it solved was being able to display non-ASCII filenames). I don't think there's much I could contribute to them at all.
>accessibility APIs expect you to export a tree of objects and push state updates
Is this an inherent limitation with the tech itself, or just an arbitrary API limitation?
This is the way these platform APIs are designed, you could theoretically make a screen reader that doesn't need that and just asks the app to recompute its state every time, but they don't currently work that way.
IMO, Dear ImGui is great for its original purpose (debugging GUIs, simple demos), but once you start adding complexity, custom layouts and custom widgets on top of it the state tracking gets to be just as bad as retained mode if not worse. Unless there was some best practice that I missed, one has to take great pains to avoid re-running the layout multiple times per frame, whereas a retained mode GUI would be able to handle that easily.
Maybe it's just a personal experience thing? I came across both ways of thinking as a junior dev, so to me retained mode was just a footgun rich environment.
I could imagine if you had decades of experience using retained-mode, though, then you'd find that way of thinking more natural.
This affects all GUIs, if you have a lot of elements then you have to be careful not to propagate complex updates through the whole tree because it kills your performance. There are various tools to deal with this, one of them is making it retained mode, but I would say basically all of those tools come with more footguns in that the GUI can easily end up in an inconsistent state. That's what you trade for performance.
I've heard that argument before, yet for almost all apps I've used in real life the opposite is true.
Game UIs are (from what I understand) written almost exclusively ImGui-style, with every single widget being fed updated state data every single frame as part of the game loop.
Yet, for whatever reason, even crazy-complex UIs like SupCom's seem to have no issue rendering in realtime with an entire 3D game running in the background, while simply resizing the window I'm typing into right now (a single textedit on a static HTML page) creates visible lag and chews up full CPU on a 2015 Macbook.
That's not to say retained-mode GUIs can't be performant (embedded systems rely on retained-mode to have reasonable performance), but on a modern system it seems like the loss in performance caused by inefficiently synchronising state in retained-mode GUIs is several orders of magnitude higher than the losses caused by pushing a couple of hundred textures every frame in an ImGui context.
The thing is those are likely to be simple GUIs. Those are a great use case for immediate mode. But try it with something that has a lot of:
- Wrapping text labels
- Widgets that are similar to CSS flexbox where the size of elements depends on other elements
- List/tree widgets or text editor widgets with large datasets in them
And then you will notice performance tanks. Think of trying to build a text editor that way, if you opened a 5MB text file, you would have to rescan the whole 5MB and compute reflow for it every time.
Game UIs do not generally involve user interaction based on the position of a pointer within the 2D screen geometry. They generally have a very limited event/input system that only takes effect via an overlay. Objects do not come and go from the "model" as a matter of course. They certainly do a LOT of drawing, and they do it very fast, but the challenges of UI design (particularly toolkit design) don't really reside in "how do we draw this stuff really fast".
I do often reflect on how fast game UIs draw, and compare that to the headaches we have in the UI of a digital audio workstation. It generally seems almost inconceivable how we could be so slow in comparison. But then I think about all the ways the user has to interact with the actual UI (not the backend data model), and it starts to seem like a different sort of programming model entirely.
I play games very infrequently, but my anecdata is the opposite: games usually have laggy UI with an inconsistent reaction to input events, noticeable latency, frequent breakage and generally worse user experience (and of course mostly without the ability to resize anything, to compare with browser), even when compared to browsers and Electron apps.
I love the immediate mode style of developing, but ImGUI specifically, at least without third party patches and extensions, has very awkward and limited layout (for example, I'm still waiting for this to get merged[1], which would make it easier), its styling support is relatively minimal (but it can be made look pretty nice) and its accessibility support is non-existent. I also find the API slightly clunky, although its not bad once you get used to it.
Overall, I really like Dear ImGUI and I love how easy it is to expose data to a UI through it. Its much more pleasant to use than a traditional retained mode widgets API. But Dear ImGUI isn't a good general purpose UI (nor was it designed to be one), although I could see the immediate mode API work well for one. I started making a complex editor for a toy engine in it and while it worked ok, the reasons above made me cut it back to just some basic in-engine stuff and the rest is exposed over an optional embedded web server module and a react app as the editor. Its only a toy, but you would use the in-engine ImGUI editor to see the scene rendered in-engine, move objects around etc, but you would use the react app to edit object properties, add assets and behaviours and whatnot. It made it much easier to create rich editors for things like behavior trees, node graphs, etc. Although since its just a toy, I didn't implement a lot of this stuff yet and haven't had time lately to get back to it.
Isn't this obvious? I mean if you need that kind of control of the screen then you shouldn't be working inside a WM by definition, and the Toolkits are built for building interfaces in the context of WMs. Right? I definitely don't want your random application to be able to draw on arbitrary parts of the screen and then prevent anyone else from drawing over it. Your use-case might sound simple at first glance, but it's truly odd if you think about how I interact with applications, and how I expect to be able to manage them.
Of course. I'm not saying that using Win32 or Cocoa are wrong (at least for a Desktop OS where you don't want to hand over full control to an app), just that they're closer on the spectrum to Qt than bare metal.
Arguably win32 GUI or Cocoa are not "OS level" APIs; yes some aspects of them are invoked through syscall type interfaces (esp win32) but not consistently and the operating system itself is entirely usable without them. Especially Cocoa. You can boot a Mac into a BSD shell without ever running Finder and the GUI.
Writing into a framebuffer is arguably as much of an abstraction these days as many of these toolkits. In the modern world of GPUs and display controllers a framebuffer itself is already N levels away from the "physical" display hardware. We're not in VGA land anymore. Some aspects of the OS or the OS's interaction with the display driver may present something like a linear framebuffer to you, but underneath that is a world of GPU textures and buffers and display controller abstractions.
When I think of OS-level APIs I think of ioctl, mmap, file descriptors and sockets. I guess that's my Linux bias showing?
Well, that's kind of what I'm driving at with things like the win32 api being a bit too high level and still kind of sucking. An example would be the GDI (the way you draw simple graphics). Like, it's in the worst of both worlds in that it's both slow and annoying to use. Or you can use DirectX and draw things fast, but you need to know a lot more. I think my point is mainly that OS's might be better off just giving you things like DirectX (and mmap and ioctl, etc.) and leaving off things like the GDI.
I know right now Microsoft keeps making like 50000 new UI frameworks and part of me is like, just knock it the fuck off, give me some style guidelines and some super-efficient very low level no-frills API's and let me just build apps off a library like Qt that abstracts it.
But most of the time you don't want to make individual pixels red. You want to blit bitmaps and fill rectangles, preferably without pegging the CPU. Here the simple memory-mapped framebuffer is less helpful, especially if you have specialized hardware to do such work.
Of course this does not apply if all you have is a screen connected via SPI to an MCU's GPIO pins. But you won't expect much graphical sophistication from such a device anyway.
> To make the top left pixel red on a bare metal system or RTOS, you simply write `framebuffer[0] = 0x00ff0000`.
Really? In my brief experience it was more like sending a bunch of commands over SPI/I2C/UART to some LCD module. Which isn't thaaaat different from how an OS driver communicates with a GPU, only the commands are far, far more complex, so using an OS-level API avoids having to do it by hand.
The OS is all about resource sharing and allow a minimum common level of interoperability.
Smalltalk can provide a storage abstraction, but to interoperate with other things it needs to be able to save data in a way that can be loaded back into your Java program.
OSes can provide you with the desired abstraction level.
You could stop at the block layer, which many DBs can take advantage of, but that won't help your Java and Smalltalk program work together easily. A filesystem is a common abstraction which should provided by someone.
Your example about the graphics stack is no different, the problem is that various components of the system are not "shared" in the same way all the time. The actual low-level abstraction of the GPU being provided to you by the kernel has more complexity today than what it had years ago in order to allow virtualization and compartmentalization of graphics memory. This wasn't needed some years ago, as it was assumed X11 was the only program to ever going to access the framebuffer, and would allow any single program using GL to trash the entire GPU.
What has been simplified is the user-level facing code, so that you can more precisely control allocation of the resources. Akin to the page-level memory allocation support we always had. This was done to allow /some/ programs (3d engines) to push the hardware to the limits (I'm relatively sad the GL1.x is "deprecated" - I still consider it to be an excellent API for prototyping and what would be 90%+ of applications).
Consider audio instead. OSS always provided pretty much all the hardware features, but allow no resource sharing. Every single evolution on that front has been an increase in complexity to allow for resource sharing. And it's interesting because the effort went in and out of the kernel a couple of times. Describing the evolution of OSS/ALSA in linux/freebsd would be too long, however we now have very fat daemons sitting in front of the HW just for resource sharing.
> Consider audio instead. OSS always provided pretty much all the hardware features, but allow no resource sharing. Every single evolution on that front has been an increase in complexity to allow for resource sharing.
This is not true. Early evolution of ALSA included lots of work on handling high channel count, memory-mapped devices (and their opposite, a few devices around in about 2000 that require active CPU involvement in data transfer). At some point, more evolution was required to deal with asynchronous interfaces like the USB ones that are now ubiquitous. The Intel HDA "specification" created a huge amount of work to model the topologically indistinct hardware mixers that it allowed. It remains the case that ALSA provides no facilities for resource sharing that are used by more than a handful of obstinate folk, so there has been essentially no evolution within ALSA itself toward that goal (see next para).
> And it's interesting because the effort went in and out of the kernel a couple of times.
Once OSS was dropped, the only resource sharing left on the kernel side in ALSA was the dmix layer. That continues to exist today, but has never worked reliably, which is part of the reason why PulseAudio came into existence.
> Describing the evolution of OSS/ALSA in linux/freebsd would be too long, however we now have very fat daemons sitting in front of the HW just for resource sharing.
I object to JACK being called "a very fat daemon". It's lean and mean and fairly clean (even the version I didn't write). Perhaps you mean PulseAudio, but that does much, much more than just "resource sharing".
As a side-note, Apple did move resource sharing out of the kernel. At some point that was all kernel-side, and at some point, coreaudiod showed up as a user-space daemon that was eventually clearly doing the same thing.
> Consider audio instead. OSS always provided pretty much all the hardware features, but allow no resource sharing. Every single evolution on that front has been an increase in complexity to allow for resource sharing.
None of the API changes were required for resource sharing though so that complexity could (and should) have been contained to the implementation and those applications that actually need new features.
Which is actually the case. In fact, audio is the best examples where everything can plug into almost everything. padsp (if I'm not mistaken - not at the prompt right now) does just that.
padsp is a hack that intercepts the open() calls to /dev/dsp - if things were done better opening /dev/dsp would just work without any wrapper, even with statically linked applications.
Nah, Android, macOS and Windows are doing just fine, it is the classical UNIX desktop that cannot get their act together.
The existing issues aren't technical, rather political, like the WinRT crusade that ended up bombing and now we have plenty of GUI toolkits to chose from on Windows.
Swift, Java, Kotlin and the .NET languages are more than high level enough.
MS .NET burned me hard with WPF. After finally looking into it, it more or less was cancelled for greener pastures.
I don't think the newer Windows UI-Frameworks are loved that much and UWP is not really convincing for desktop applications. Just too much hassle for too little gain and the threat of vendor lock-in.
“I don't think the newer Windows UI-Frameworks are loved that much and UWP is not really convincing for desktop applications. Just too much hassle for too little gain and the threat of vendor lock-in.”
I used to be a desktop dev but after the mess with Winforms, WinRT, WPF, Silverlight, UWP and WinUI I would never bet again on an MS GUI framework. Most likely it will be abandoned soon and put into maintenance mode.
I still don’t understand why they constantly crank out new frameworks that do basically the same instead of evolving an existing one like WPF. The cost of enveloping, testing and documenting these frameworks must be enormous.
I briefly looked into UWP when it was being promoted with such fanfare, and the only thing I could see were the gross incompatibilities with WPF, basically requiring you to maintain two guis if you wanted to use the app store and support two versions of Windows, let alone Xamarin. Then they basically dumped the app store model they were going to use and started allowing anything on there. It's https://xkcd.com/927/ all over again, except in this case it's all just Microsoft!
I looked at UWP when it came out. The only thing I found was that it was different but I didn’t see any improvements over WPF. I still don’t understand why they wouldn’t make it compatible with WPF.
Years and years ago I was offered a job as an MS tech evangelist for the purpose of pushing Mozilla to use "new" MS technologies coming in what would eventually be Vista. I had a decent repuation in the Mozilla community, and I've always been a good communicator. The problem was some of the things they wanted me to push I knew would never get out the door.
There were three big issues although I can only remember two, which were WPF and WinFS. I said flat out WinFS isn't going to make the cut, the third feature wouldn't, and even if WPF did make it into the final build, Mozilla doesn't have the resources or desire to move Mozilla to WPF, especially since mozilla is a cross platform app. "Yes, we know, but utilizing WPF will make it easier to develop on Windows!" I pointed out while that's good for MS, it provides no benefit to Mozilla's non-windows users, and Mozilla would never do it. And WinFS isn't working at all, so why would they spend even a moment trying to figure out how the new FS would benefit an application?
I think the third leg was Palladium. "It'll make online banking so secure!" I remember commenting that with all the flack it was getting, it'll have no buy in from anyone else, and flop.
I don't think compulsive "tell it how it is" people are good for evangelist roles. :D
Could you expand on this more? I don't know a lot about GUI programming, but I'd be interested in learning what the current failings are within the desktop space.
That's true for "Linux", but "Linux" on its own is not a desktop OS. If you target KDE then Qt is the ubiquitous standard with decent performance and a predictable look, same goes for GNOME with GTK. Both of them I would say are less "bloated" than win32 or cocoa at this point. And I don't have any comment on whether it's "ugly" or not :)
If you think that Qt is more bloated than Cocoa I don't know what to say. That objc runtime is so heavy and slow, good luck making it run on microcontrollers
Not sure what you’re talking about. ObjC runtime is fairly small. The basics of what you need for ObjC is just objc_msgSend, which is basically a fancy hash lookup written in assembly language. If you want ObjC on a microcontroller, you’d want to port this function to your target architecture. There are a few other components you “need” but objc_msgSend is the key one.
You’d probably also want some form of malloc(), but that’s completely optional. There’s nothing in Objective C that says you have to allocate memory dynamically, or that you have to do it with malloc.
ObjC runtime has grown somewhat to include more features, but you don’t need all those runtime features if you want to run your code on a microcontroller. Just like you don’t need glibc if you want to run C. There is more than one runtime for Objective C you can choose, just like there is more than one runtime for C.
It's probably exactly that runtime...desk devs have forgot that embedded is tiny, megs not gigs of memory, so not one but 2-3 orders of magnitude smaller.
You can have all the 'simple' calls you like but if you need to malloc half a gig of ram just to get started...that is heavy and bloated.
Also you say 'architecture' but unless you are talking a battery hungry cellphone you are probably talking 16 or 32 bit proc not 64, which means potentially massive increase in the size of code to be generated since you lose certain instruction sets. I don't know realistically what Obj C uses in the osx cpu architecture but I'm almost certain it's not going to be as simple as just retargeting your compiler...
Not saying it can't be done but take even the new arm laptops from Apple - that's a significant hardware investment on top of a bunch of software tricks, not just a casual retargetting that can be portably moved to other low power systems.
> I don't know realistically what Obj C uses in the osx cpu architecture but I'm almost certain it's not going to be as simple as just retargeting your compiler...
Objective C is in mainline GCC. You retarget your compiler and port the runtime. As far as I know, any target with GCC support can run Objective C, given a runtime. The important parts of the runtime require kilobytes, not megabytes, of space.
Remember that Objective C was originally a very thin layer on top of C. You take all the [method calls] and replace them with calls to objc_msgSend(). The overhead is fairly small— your object instances need the “isa” pointer, which is basically just a pointer to a vtable. The objc_msgSend() function reads the vtable and forwards method calls to the correct implementation.
My experience is that Objective C binaries typically have a much smaller footprint than C++ binaries. That’s obviously not some kind of rule, but it reflects idiomatic usage of Objective C. In C++ you'd use a std::vector<T> which is a templated class, which gets instantiated for every different T you use in your program. In Objective C, you’d use NSArray, which is monomorphic.
This all should be completely unsurprising—since Objective C first appeared in the 1980s, it’s no surprise that it doesn’t need much memory.
> GCC doesn't do modern Objective-C, only what they got from NeXT days.
It's definitely a lot more than the NeXT days. GCC got fast enumeration, exceptions, garbage collection (if you really want it), synthesized properties, etc. These are the "Objective C 2.0" features which got released in 2007, back before Apple was shipping Clang.
GCC doesn't have ARC, array / dictionary literals, or other new features. But it's definitely a lot more than Objective C from the NeXT days. These are "modern" Objective C. They're also basically just sugar for the appropriate calls to +[NSArray arrayWithObjects:...] or -[retain] / -[release] etc.
Debating whether some language feature can exist on an mcu is somewhat unrelated - the point was about code size bloat not whether you can fake one instruction set with another...
You can fake e.g. multiply with a for loop and an add instruction (1 or 2 cycles) but that will run orders of magnitude slower than a 2 or 3 clock cycle multiply instruction...
So the point about osx arch is not really addressed, if you have runtime that cannot be easily ported or osx cpu arch which produces prohibitive instruction sets it doesn't matter if gcc can target an old version of objective C, it is, as stated, not that simple.
I don't understand the technical reasons behind it, but for whatever reason doing something like resizing a Window for any non-trivial GUI seems to cause the repaints to drop down to 15-20Hz in Qt and spike the CPU usage massively. The same issue doesn't occur with Win32 or Cocoa.
You probably don't have graphics drivers installed...
IIRC the fancier toolkits (Qt, GTK) do widget accell with either mandatory blitting and/or 3d (OpenGL/DirectX) (Other frameworks like WPF and Cocoa are notorious for this too).
There are, or used to be, frameworks that were not gpu dependent.
I've never hear nor seen these massive drops you claim to, so either you are running 20 year old hardware or your graphics aren't on, or you have some other hardware issue...
That's interesting, I have the exact opposite experience, I used to have a MBP dual booted with ArchLinux, and resizing windows was incredibly much smoother on Linux with either Dolphin, Nautilus or Thunar, than with Finder on the Mac which looked like it only drawed 1/5th of the frames compared to linux.
I do understand the technical reasons behind it, and it has nothing to do with bloat. It mostly has to do with mapping a cross-platform (i.e. generic) window abstraction onto a specific OS-provided drawing/event/windowing API.
I built my own cross-platform windowing/event API from scratch at my last job, based on top of win32 on Windows, Cocoa on Mac and Qt on Linux. The only platform where there was any noticeable performance drops at all was Linux, because it relied on Qt.
When I said "I don't understand the technical reasons behind it", I didn't mean "I don't understand how to abstract OS-native APIs". I meant "I don't understand how a team of intelligent people managed to fuck things up this badly".
There are some reports of bad things happening with inefficient QPainter usage, and some bugs related to text drawing especially after qt5, after a cursory look...would be better to provide specific examples. I do rather suspect something machine or even program specific, though.
If you actually look at the commits, it's mostly fixing the build and tweaking it to work on modern platforms. My personal opinion after trying it, I would not suggest use of Motif or CDE for anything besides nostalgia, it has some serious usability issues. But if you enjoy it, more power to you.
Who cares about CDE, the classical UNIX desktop, as in the way that BSDs and GNU/Linux keep pushing for the old days with their fragmented stacks.
macOS, although a UNIX, follows the same ideolagy as NeXTSTEP, where UNIX compatibility was a means to bring software into the platform, and that was about it, GUI software was to be fully taken advantage of Objective-C Frameworks.
Yes. "CDE" itself stands for "Common Desktop Environment". (Wikipedia says it was "part of the part of the UNIX 98 Workstation Product Standard", and if you remember the 1990's like I do, it was, indeed, supposed to be the "standard" desktop for Unixes.)
>True low level control is kind of a pain, but the OS libraries are not particularly pleasant or high level enough either
Wait. In that case, library developers or OSS projects can fill the gap. What am I missing here? QT comes to mind. A high level library for GUI programming. Also, the modern .NET stack.
I always thought the popularity of Electron is because GUI programming is insanely easy on it, and if you have apps that are heavily data dependent, you go with it because the alternatives (Native apps, WPF or Winform apps) do not provide any value addition.
Electron is popular because it makes cross-platform desktop apps easier, or because developers have existing JavaScript code that they want to share between a desktop app and a web app.
I would say that if you just wanted to spit out a Windows application, and you already knew the technologies, WPF or Winforms would probably be better (despite the fact that WinUI is the new hot stuff).
> So largely things like Electron or Qt are acting as the defacto OS anyway to varying degrees of success
That's the natural (and arguable optimal) state of things: lower levels and higher levels.
High-level developers use high-level things, low-level developers use low-level things.
Every once in awhile someone gets the bright idea to combine all the layers into one, but finds out that in the real world that just isn't practical.
But we get developers pulling apart and adding layers over and over, driven by a love for "simplicity." Moving forward, or in circles? Hard to say, but probably forward.
I would love more collaboration between operating systems. There should be more layers with standard interfaces.
For example BIOS used to be a driver layer back in the day, providing simple API to underlying OS. This concept should be expanded. I don't see no reason for every OS to rewrite those drivers again and again. There should be some standard for common device APIs, like disks, keyboards, mouses, GPU and so on. I should be able to buy an Nvidia GPU, download and install UEFI driver and it should provide Vulkan API for any underlying operating system, Windows, Linux, OpenBSD, ReactOS.
Another example is file systems. All major operating systems are very similar when it comes to file systems, at least from the user PoV. Yes, there are Windows ACLs, Linux permissions, but it should be possible to abstract those away enough. So Windows could install its latest Windows 11 NTFS driver into UEFI and Linux should be able to just use it to access NTFS safely, without any gigantic efforts to reverse-engineer and reimplement everything from scratch.
At one point I thought about virtualization being an answer to those demands. These days you can write completely virtualized operating system which needs to implement virtblk, virtfs, virtio-* drivers and run it on any host operating system with perfect driver support from manufacturer. GPU is not there, but I don't think that it's impossible to implement. Of course running a full-blown ad-ridden Windows 11 just as a hypervisor seems like not the most elegant solution.
Unification will not play nicely with new progressive features like BTRFS, though. That's something to think about as well.
“BIOS” is really just a bunch of drivers in ROM chips somewhere.
Thing is, most devices you actually don’t need special drivers because they are so standardized. Mice and keyboards are USB HID. There are a handful of ways you typically interact with storage, like using SCSI. Surprisingly, a lot of storage devices are actually SCSI, in some form or another.
One of the big problems is that drivers are going to closely interact with other operating system services, like memory allocators or the scheduler. The interface has gotten a lot more complicated over the years. And the semantics that operating systems present to the user are sometimes different in significant ways. Back in the BIOS days, what you could do through the BIOS was rapidly falling behind what you could do with a proper driver.
To pick on the filesystem example, there are some fairly major differences between Windows and Linux/macOS/BSD filesystems APIs from the developer perspective. Windows has mandatory locks and files are identified by name. On Linux/macOS/BSD, there's more of a separation between a file and its name—files do not even need to have names at all, and locks are advisory. For this and other reasons, there are some boundaries between files you use in WSL and files you use in Windows.
I’m just very skeptical here that you could introduce another layer between devices and the OS, that would be thinner and more direct than using a hypervisor, more flexible than just using a standard protocol (like USB HID) which your OS already supports, and work with multiple operating systems.
Standard protocols between hardware and operating system drivers are the way to go, then you get to implement drivers for each hardware class (mouse, disk, keyboard etc) once and use all new hardware, instead of having the hardware vendor need to write new proprietary blobs for every new piece of hardware and every OS.
For example I read on LWN that hardware vendors are starting to look at Linux virtio for hardware agnostic protocols.
Oh no, I prefer BIOS/UEFI firmware to be as lean as possible, like, "boot my OS and get out of the way as quickly as possible" (because all software has bugs, larger software has more bugs, and fixing/updating firmware is a gross PITA, I mean inability to roll back and risk of bricking the hardware e.g. due to power loss). At least in Linux I can apply kernel patches individually, and in Windows I can replace a file here and there, but firmware is a monolith, so it is a "hit or miss" kind of thing. More complexity in firmware rapidly shifts this wholistic thing to "permanent miss" state.
In an ideal world, we'd essentially have a number of software vendors that provide devices that conform to certain standards (we are mostly there in regards to peripherals like mice and keyboards, but not really in regards to Wi-Fi dongles/cards and other more complex devices).
Then, we'd have reference implementations for every single one of those, that would give examples of how to access this standardized functionality, possibly with abstractions over those. So on one end you'd have something like a wi-fi-networking-huawei library and on the other you'd have wi-fi-networking-generic library that could interface with the former and access its common functionality. Of course, as for how this could be written, and what the situation would be in regards to the C standard library or any other primitives for other sufficiently low level languages, i have no idea.
Then, you'd have a kernel module or a microkernel, that would contain the code to interface with the hardware and add all of the controls and permission management functionality, as other bits to integrate this solution with the OS. If one would go with the GNU Hurd approach, then integrating that within OS distros would suddenly get even more simple, except that Hurd seemed to fail at the actual implementation stage.
And finally, you'd have the OSes, which could implement code to interface with these modules, microkernels or add any number of necessary shims inbetween to get everything working together and provide the higher level OS functionality that's needed to use these devices within the OS context.
Of course, i'm probably oversimplifying some things, skipping a few steps here and there, but i'd chalk that up to the current approaches to using hardware in software being overcomplicated beyond need or belief, rather than me mostly being a business software developer, as opposed to systems software developer or hardware engineer. In short, there are abstractions in place already, i'm just not sure those are the right ones, but rather what was historically needed to get things working. So where's the big rewrite and learning from our past mistakes?
To me, it just feels like what we need is a set of meaningful abstractions and standardization, and not just in regards to making sure that there are security mechanisms in place for booting so the devices on which Windows runs can be limited to create more e-waste (snark) and motivate consumerism, but also to actually be able to use Wi-Fi in all hardware in 2021 in both Windows and Linux distros (not snark, literally had to compile custom drivers for my no name netbook).
Let's start off with defining what an Operating System really is because depending on where you draw that line the outcome will be substantially different. Ignoring mainframes and other large installations for the moment, strictly from a 'personal computer' point of view:
If you see the operating system as the task-schedular + IPC clearinghouse then the system is simple, well defined and it can be expected to perform in a deterministic and verifiably correct way (assuming working hardware).
If you define the operating system as 'everything and the kitchen sink' including media players, browsers and so on then there is no way to make any guarantees and determinism is going to be impossible to achieve.
Personally I prefer the leaner-and-meaner operating systems that have a larger ring of userland software built on top of them to create as small as possible a core on which the actual end-user applications are run.
Those systems tend to find good middle ground between reliability, speed and security because the amount of surface area exposed is going to be the minimum at every level.
Something like Windows is on one end of that scale, something like MacOS is somewhere in the middle. Linux can be stripped (or more accurately: it could be stripped) to something a lot slimmer than the default distros, and something like IRIX (no longer used in production as far as I know) was roughly where MacOS sat (custom hardware, custom OS tied closely to that hardware).
An ideal OS that limits itself to scheduling and IPC is currently not on the market for desktop usage, and the arrival of the mobile device market has blurred many of the lines that we thought were drawn pretty clearly in the past.
The 'lets move everything into the kernel' philosophy is as far as I'm concerned fatally broken and likely things will have to get a lot worse before they will finally get better, and it would not surprise me if everything that we do today will be discarded once that happens.
Where do you rate the part of the OS that makes 100,000 types, brands, and models of devices all look about the same to our apps? I always saw hardware compatibility and abstraction as the greatest value proposition, not only for the user but for the PC industry as a whole.
"an operating system is a collection of things that don’t fit inside a language; there shouldn’t be one"
I've wondered the same thing about databases. Just like an OS, a database has to manage data on disk and figure out when to cache it. The files & folders metaphor is arguably a relic of pre-computer times--instead of searching through folders, it is easier to search and sort based on particular attributes, something that databases are well-suited to. I think it'd be interesting to start with a database and try to build an OS around it, see how far you could go.
But humans generally like to organise things hierarchically and I would think database are not well suited for this purpose.
That is, unless there exists some kind of tree structured database that I don't know about ...
Many years ago Microsoft tried to implement some kind of database oriented file system (it was a big dream of Bill Gates IIRC and probably meant for Longhorn), but this project never became part of an official Windows release AFAIK. It'd be interesting to know why Microsoft abandoned this initiative.
> It'd be interesting to know why Microsoft abandoned this initiative.
There were technical issues. They simply never managed to get the system performant enough to be use as a FS replacement. There also were tons of issues with the concept itself, like proper tooling for visualising the stored objects to the user and a compatibility layer for legacy software.
It seems as if parts of it was merged into MS SQL server products [0].
Yeah, it was based on Jet, so if I had to guess they're probably just talking about including some perf improvements in the core database engine that they made profiling the WinFS use case.
> That is, unless there exists some kind of tree structured database that I don't know about ...
Believe it or not, hierarchical databases were actually quite popular once upon a time, mostly in IBM mainframe land as I understand it. Today the Windows registry is a hierarchical database in common use.
And Codd's invention of RDBMS killed those very successfully... until we reinvented them , first with XML, second with NoSQL, and rediscovered, again, why the relational databases were such a huge success and adopted with such enthusiasm.
This is why, when people start asking for categories or hierarchies, you implement it as tags without telling them, if it's at all possible to do so.
Then when they decide they actually need tags, you either get to be a hero, or to goof off for a couple weeks, depending on your situation :-)
Nesting works the same way. "OK we said we needed N levels but actually we need arbitrary levels of nesting, and also we don't realize it but what we're asking for can introduce cycles to the structure". Every. Damn. Time.
It's a tyranny of hierarchical data-structures and ontologies. Always breaks down. Use relational models, graphs, tags, sets, uuids/global identifiers etc. Trees are an optimization strategy/snapshot and almost never a model for the real world.
This is basically the problem of organizing knowledge and setting up rules to easily interface with it through computational systems. There was an interesting article that discussed the topic some time ago, but can't find it right now.
Neither hierarchical organization nor tags nor databases work. You need a mix of everything, and you need to make it nice enough for the user to be able to select the best option at the right time. Think about how you think and access memories. There are a ton of ways you do it, not only hierarchically or "table-based".
This could also be likened to the problem of categorization that meta-rationalists like to talk about so much. Basically, that (at least in human terms) no categorization works under all possible contexts.
We are not gods, so it should be obvious that there's no possible organization of knowledge that makes it all perfectly available. It can't be frictionless, instantaneous and complete at the same time. Then, it should be obvious that if we want to make access to information as effective as possible, multiple methods need to be combined.
In fact, a lot of the technology that has been most "revolutionary", has been technology that improved the way we access certain types of information. Graphical interfaces, databases, spreadsheets, hyperlinks, google search, etc. We have also used calendars, lists, schedules, diagrams, button panels, etc., long before computers were a reality.
There are still a few steps left. As we attempt to tackle even more and more complex systems, we are pushed to look for new ways to manage all that.
Sorry, didn't see your reply earlier. Don't have much time to explain, but for context, you probably want to read "a first lesson in meta-rationality" [0]. It doesn't talk much about categorization directly, but it broadly discusses the limits of rationalism, and starts to explore the "solutions" / alternative perspectives (that the author decided to label as "meta-rationalism"). The categorization problem is one of the points where you can see the "limits" of rationalism. It's never discussed to much or too explicitly in these terms, though. I advice you to read the whole thing attentively, and when you are done, go back to review the section on nebulosity, and specially this quote:
>> One has to be able to “bend” concepts, when it is appropriate. Nothing should be absolutely rigid. On the other hand, things shouldn’t be so wishy-washy that nothing has any meaning at all, either. The trick is knowing when and how to slip one concept into another.
And reflect again at this point about what you have read:
>> The point of these examples is that what counts as an “object” depends on the context.
...while thinking explicitly about the categorization problem. In computer science and AI, in particular, this problem might appear even more clearly, specially in symbolic AI. If you try to create a symbolic AI system, or if you are an experienced programmer and have a solid grasp of the limitations of abstraction, it all floats around this main issue of nebulosity / categorization / methodology in rationalism. You might also be reminded of the aphorism "all models are wrong".
Hope this gives you a starting point to keep exploring more deeply if you want to.
I can imagine a hybrid file system where a hierarchical structure is used for several levels, before bottoming out in a directory of databases. Ideally this would be accessible/searchable by DB index from all levels of the directory hierarchy. I'm sure something like this has been implemented of which I am ignorant.
The Be operating system (BeOS) uses BFS as its native file
system. BFS is a modern 64-bit journaled file system. BFS
also supports extended file attributes (name/value pairs)
and can index the extended attributes, which allows it to
offer a query interface for locating files in addition to
the normal name-based hierarchical interface. The
attribute, indexing, and query features of BFS set it apart
from other file systems and make it an interesting example
to discuss.
So yes it has been done. Personally I like the AS400 idea most - an object store where you don't even have to really "think" about the difference between memory and storage - you just have objects that you can cause to "persist" when you "commit" them and anything they are linked to by pointers will also be persisted.
Also, prior to BFS, in the earlier beta builds of BeOS, the file system was much more database like, but it ended up having performance issues (IIRC), so in a later version, they replaced it with BFS.
Apparently the earlier builds used an actual database alongside the filesystem but it was hard to keep them consistent with each other so they altered it.
I've had some experience with running applications without an operating system. First and foremost I like the simplicity. Instead of having state distributed between the kernel and the application all the state is in your application. No longer having this dance where an application and the kernel interacts there is only one place where state is kept.
This can lead to some spectacular results for things like TCP. Having the ability to serialize a TCP connection and sending it over the network means you're able to transfer a TCP connection from one host to another, even with SSL on top.
Now, this can be done with a POSIX kernel as well, as long as you move the networking from the kernel into the application. But if you're doing this you're eroding away the benefits of the kernel, basically turning your OS into a bootloader. Same thing with scheduling.
Another benefit is that, at least on compiled languages, code that isn't used isn't there. So the linker can strip away everything that is never called.
This still feels like utopia. The average development environment is pretty complex and ripping out and replacing all the layers below your language runtime is too much effort.
I see the paper uses the term "postmodern" multiple times and references a paper "Notes on Postmodern Programming" which begins with a Manifesto. What does this term mean in this context? I don't like what I smell.
Postmodern in terms of programming refers to that body of thought that posits a replacement of the rigid classist structures with a new functional hermeneutics based not simply on truth or falseness but on an interpretation of access defined as a trajectory of internal and external states across the pattern. Most new PDM (post modern development) is actuated in a bias free programming language called "Chomsky" which is a rigid left recursive grammar untainted by Boolean logic.
I know you're joking, but just to clarify for others: Nothing about Chomsky's work is postmodern. On the contrary, Chomsky is a well-known and fierce critic of postmodernism, both in his political work and in linguistics. He's been openly criticizing "postmodern" thinkers and authors for decades. See for instance [1]. Moreover, his approach in linguistics has frequently been criticized as being too "scientistic" because he re-oriented linguistics towards the natural sciences. After all, he's the one who brought formal, recursive grammar formalisms and grammar hierarchies to the field.
As far as this paper goes, the main idea is pluralism. Much software lore leans quite heavily on grand narratives about how things "should be done". The "postmodern" view is a reaction against that: in favour of multiple, coexisting, smaller stories. These do not have to be mutually consistent.
Of course there are lots of other overlaps between software and postmodernism in other culture, and that was the wider observation of the Noble & Biddle essay... true that it is a bit oblique. You might enjoy this a bit better: https://www.se-radio.net/2006/11/episode-38-interview-james-... -- it's now slightly dated, e.g. how "programming by Google / StackOverflow" was a much newer idea then than it is now.
Continuing on your analogy, I would argue we have less diversity due to the all-encompassing three major OSes.
Similarly to how you don’t really get competitors to eucaryotes and prokaryotes, the initial investment (device drivers) to create an OS (organism) that is actually usable is so high that one basically can’t overcome it when others are available.
(Only read the abstract). I’m learning Emacs and it’s making me think that we missed on the correct abstraction level of the operating system. There are programs that are OS-like (Emacs, browsers, Electron, anything that takes plug-ins). Maybe operating systems could have been lower level, and we could have developed more/better options on the pseudoOS level on top. This seems somewhat inline with the Smalltalk vision.
Yes, there is a very blurry line between operating systems, programming languages, and we can include databases as well. Some operating systems as you point out are PLs. Some PLs are implemented as databases. They’re all just really complex accounting systems by nature. Look at the implementation of a lot of OSes, PLs and DBs they are really just made up of tables keeping track of relationships all the way down.
I would be soooo happy if OSes were just absorbed by databases. The file system is just a heirarchal key value store: genius! Let's make it untyped so you have to parse everything manually just to interpret it: not so great.
Yes I'm saying the Unix file system is a worse mongodb. Please at least give me a postgres or something.
Do apps add their own types in that system? Otherwise, I have a hard time imagining a set of base data types that could usefully represent things like OpenOffice documents, geo-referenced geometrical feature databases, and the thousands of other field-specific binary formats that are in use. Storing all these things as data blobs just puts us back in the "untyped filesystem" situation.
Maybe I've completely misunderstood your proposition, though.
If a file emitted by some third party program is intended to conform to some type, yes it would be great if that type was expressed in the filesystem. Maybe that would look like a reference to a 'schema description' file that has a specific format that is bundled with the app.
Now, that doesn't stop MyProprietaryApp from declaring that the type MyProprietaryFile consists of a big bucket of bytes which it then interprets how it likes, but that's inevitable and not worth worrying about.
The point is to enable defining directory and file schemas for my OS and applications that I can control so that interaction and discovery within these systems isn't so baroque.
It's not about relations, it's about schemas and types. My complaint is that none of the schemas and types are communicated by the OS in an explicit, uniform, programmatic way.
Everything in 'special' mounted filesystems like procfs, sys, cgroupsv2, etc as a start. These all use implicit schemas of particularly named files with particular contents that you have to learn about out-of-band to just to do anything.
Requirement 1: Everything has an inspectable schema.
All the configuration files with their own home-grown format that you can only validate by restarting the program that relies on it and hoping that it doesn't crash your system is for the birds.
Requirement 2: Files that must have a particular format must also have a well-defined Type that can be validated to be correct in a uniform way outside the program that uses it.
> Let's make it untyped so you have to parse everything manually just to interpret it
Isn't that exactly how traditional FS work anyway? Even using MIME types only gives you an optional, non-binding hint. In the end you need to parse and interpret the content "manually" (well, usually using libraries).
None that immediately spring to my mind. There are operating systems that incorporate programming languages as their default user interface (like UNIX that drops into a Borne shell and LISP machines) and there are computers that have programming languages baked into their firmware (like the 70s and 80s micro computers did with BASIC). But in neither instance is the language itself the operating system.
The micro computer instance is definitely nuanced though. Some do argue that Microsoft BASIC et al were an operating system. Some don't. I'm in the latter category because I think "BIOS" more closely describes the function of the software on those old micro computers.
For a Lisp Machine the operating system was written in the language itself, this included a network stack and the filesystem interface for local disks.
IBM never had a plan for a mainframe operating system that made sense -- given the idea that the "360" was supposed to encompass the whole circle of applications.
What happened was some academics figured out it was possible to make virtual machines on the 370 and that you could run a few different operating systems at the same time. If you were doing software dev on the 370, for instance, you would start up a VM running VM/CMS which was a single-user OS a lot like CP/M or MS-DOS, work there, possibly using services offered by another OS in another VM by some kind of message passing.
This turned out to be the "master plan" in the long term, since they could have a few different mainframe OS, even some applications that run on "bare metal", but have it all run on one machine or one cluster of machines and be managed under the same pane of glass.
The reason it worked out was that each virtual machine was given a set of capabilities, and the hypervisor restricted access for that machine to only those resources.
Eventually, this lesson will spread. I think about 5 more years of chaos until people finally catch on.
Also there are many x86 and other systems where people use VMWare or something like that for "server consolidation" without going all the way out to the cloud.
The difference today though is that the guest operating system today is a "full-service" operating system such as Linux or Windows. In many of these cases the partitioning of the service could be accomplished through user id's, processes, sessions, containers, and similar facilities offered by the guest OS.
I've been playing with Unikernels for Go server deployment - so far so good. I'm not sure if this counts as "no OS" - as I understand it (and I'm not sure I do) the Unikernel core provides the calls that the Go runtime is expecting.
But the central idea that the server system can only run one program makes a lot of sense to me. Obviously it won't work for a desktop, but then the whole idea that desktops and servers run the same OS doesn't make much sense to me.
I've been expecting the unikernel approach to catch on more too - although not the "no OS" it can be pretty stripped down compared to a regular OS. Now that unikernels are starting to gain more traction in the DOD I expect this will continue.
I've worked with Unikernels for a couple of years. They are great, but they are very, very pure and this can be limiting.
Say I have an web API written in Go. For some reason I need to do some openssl stuff before I start up my main program. In a container I can just wrap my program in a little shell script which generates/signs a cert before starting the API.
Such a simple task. It is gonna be a lot harder with a Go Unikernel as I could have to bake this functionality into the application itself.
This Swiss Army knife that is Unix often has it's uses.
I get that, but I rarely need to do stuff like this - I generally use the awesome ACME library to handle certs. But yes, if I did need to do that then a Unikernel wouldn't be useful.
But the reduction in attack surface of not having all those Swiss Army blades hanging about - and not having to configure them just right so I don't accidentally damage stuff - is a real benefit.
You can have best of both worlds with container OSes like Bottlerocket.
In any case, in you have a web API written in Java then you can connect advanced monitoring tools like JDK Flight Recorder and directly affect the system via JMX beans.
So it is more a matter of tooling maturity than anything else.
OSes do have shared abstractions such as file systems and process input and output. I think the trick is to make the common abstractions richer in a way that enough people agree on and are willing to adopt. Most of the shared OS features are basically grandfathered in. So a big part of this is that this stuff is not really a rational choice usually. It's just the way it's always been.
So upgrading the capabilities and creating new common abstractions in an OS is not that hard. But almost impossible to get the majority to go along with it.
Browsers demonstrate an additive way of getting a lot of that. In that we now have essentially two highly compatible widely deployed VMs -- Firefox and Chrome. Which can be programmed in a number of languages that compile to JavaScript or web assembly and share a rich API.
If you have one job to do, and it doesn't involve other computers, you don't need an OS. MS-DOS or equivalent program loader/file system API will work just fine. Windows, MacOS, and Linux work fine in a stand alone environment (unless an APT {advanced persistent threat, like the NSA} is after you)
On the other hand, if you're even thinking about touching the internet, or any other computer, you need to have every single task limited ahead of time to a specified set of resources, like mainframes do. Doing anything less is foolish, and I certainly wouldn't build a civilization on such folly.
Yes, in an era of mobile code, persistent internet, you need an operating system that doesn't give any default permissions to any executing task, ever. It must also safely and securely multiplex access to the hardware resources, all of the hardware resources, in all of the subsystems in the SoC, etc.
There are no Operating Systems, as of yet. I weep for the future.
If you have more than one program, they need shared data and access procedures, like the “user” and “the hardware”. Who manages them: The OS?
Maybe you want to share a bit more like some common higher level functionality. That becomes part of the OS, de jure (resident kernel) or at least de facto (loadable kernel modules).
As soon as two or more separate applications share some common body of code that helps them deal with The Computer, you have an operating system. It doesn't matter whether that common body is a table of software traps that dispatch machine language routines, or whether it is Smalltalk objects.
Some game on a MS-DOS floppy disk that boots itself from the boot sector and uses BIOS calls has an operating system.
The set of requirements which describe the host environment (the "virtual machine" in the classic sense) that forms the backdrop against with an application is developed is the operating system.
The only way you don't have an operating system is when the application itself does everything it needs with regard to the outside world by itself poking at I/O registers, and handling every interrupt and so on. Anything independently organized for that purpose, given something resembling an API, is an operating system.
There is, or used to be, a sensible version of "there should not be an operating system" I first heard some decades ago. Namely this: "there should not have be an operating system with a hardware-protected user/kernel boundary". The idea is that there doesn't have to be kernel which the hardware conceals using privilege levels and fences. The idea is supported by the notion that all security can be handled at the software level. The system, as such, is somehow verified to be correct. The only way to execute code is via compiling it via the system's trusted compiler, which generates only safe instruction sequences. Those sequences can call functions in the system, and those functions sandbox what can be done. All notion of trust and privilege is software-level without any privileged instructions having to fall down a trap into a privileged kernel which meticulously validates arguments.
(All that rhetoric needs to be somehow adjusted for 2021, which finds us jaded by knowledge of side channel attacks, cache attacks and whatnot.)
Maybe this is a hot take, but it seems like browsers have essentially become what the operating system should have been, and it's the reason that everyone crams things into web apps / Electron instead of building native applications.
Browsers have a set of APIs that are decided on by a standards committee, and you have to implement those standards if you want your browser to be compliant. As an application developer, all I need to do is check a page to see how widely a standard has been adopted and then use it - I can be sure that my code can ship to (nearly) every device and behave uniformly, with minimal tweaking.
If the operating system had gone that route, we wouldn't have had to build more layers on top of it to abstract away the differences.
There is a HTML-bundle alternative to PDF in my utopia. User agents can render documents optimized for any screen instead of hardcoded two column A4 pages. Nouns and verbs are highlighted.
Unix generally has the correct basis for the design.
I agree that a filesystem as we know it in unix-like systems is a set of objects (directories) and files.
Would it not be preferable to retain this simple interface and instead conceive of interaction between programs and threads not as a stream of distinct objects in memory, but rather as a data tree within each program's control which can be exposed as input or output for other programs to map against and write into / consume?
I think the problem with the unix model is that there isn't a rich enough array of types -- everything is just a stream of bytes and the closest thing you have to lists and records are strings with spaces and newlines. It was revolutionary in the 70s but compared to what you can do with something like powershell (which has its own issues) it's just not a rich or easy to use model anymore.
"The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point. Frequently the messages have meaning; that is they refer to or are correlated according to some system with certain physical or conceptual entities. These semantic aspects of communication are irrelevant to the engineering problem."
- Claude Shannon, A Mathematical Theory of Communication
Everything is inherently a stream of bytes. You can use programs that interpret them as typed data or newline or null-delimited arrays all you like.
Thing is, without a build in (good) way to do e.g. array types, every program will roll their own. That is lots of duplicate work, and makes having programs interact a manual process of integrating 2 unspecified ad-hoc standards.
Programming languages create idioms and standard ways to do things. We judge those for their clarity and quality. On that front UNIXs "you get a stream if bytes, do what you want" leads to a fragmented world of low quality idioms. And hence gets judged poorly.
Except that there are standard ways of doing arrays. Newline terminated is the most common, null-terminated is used for data that could have unusual characters in it, and most of the standard utilities support both.
The problem with not doing this is that the operating system is imposing some arbitrary standard on data that may not have even come from the same system.
If the data you get is JSON, there are utilities for parsing JSON. If it's XML, there are utilities for parsing XML. It could be a PDF and you want to convert each page to a TIFF and then tar them into an archive. The file came over the internet; it doesn't care about your system's encoding defaults.
Well, in light of the topic of the original article, I'd just compare working with byte streams to working with a smalltalk style object, and see which one is more pleasant. (You could still do a byte stream in smalltalk land, you'd just have to be explicit, it wouldn't be the default)
Standard formats like JSON, XML, and PDF are arbitrary encoding defaults, but on a slightly higher level.
If I send your system something obscure like an SDIF audio file you're not going to have the tools to do anything with it unless you can find and install an SDIF library.
What if the OS could do this automatically because a typed schema and standard API was built into the SDIF (or any) standard and installable in the same way code dependencies are?
> If I send your system something obscure like an SDIF audio file you're not going to have the tools to do anything with it unless you can find and install an SDIF library.
Which is the point. So then you find and install an SDIF library. The OS can't reasonably predict and support every possible file format that anyone will ever come up with in the past or future, so the answer is to be flexible and use different utilities for different formats.
> What if the OS could do this automatically because a typed schema and standard API was built into the SDIF (or any) standard and installable in the same way code dependencies are?
The problem with this is that what you can do with a file depends on the format. You can split a PDF into pages; you can't split an SDIF into pages. An SDIF might have channels; a PDF doesn't have channels. You could call each frame in a video a "page" and try to compare them with a PDF, but the video "page" is going to be a pure individual image whereas a PDF page might have text or multiple individual embedded images.
Everything is so specific to the format that you're going to want format-specific utilities to operate on it that take into account the characteristics of the format.
At best you'll sometimes have multiple formats that are largely "the same" interface-wise like PNG and JPEG and then you would want to use the same interfaces to access both, but that's what already happens. You use e.g. ImageMagick when dealing with both PNGs and JPEGs because it supports both. But it doesn't support SDIF because you need a completely different interface when dealing with audio.
And file formats already have magic strings in them that identify what kind of file they are, which is about the extent of the information the OS could provide you about the file without assuming anything about what's inside it. The schema is already implied by the header magic.
There are indeed standard ways, but they are _bad_, they are badly specified, but mostly they are just bad but easy ideas.
Not to say that anyone who wrote a bash tool that uses newlines or nulls as sentinels is bad programmer. But to say that UNIX IPC offering nothing better than newlines or nulls as idomatic is a big downside of UNIX.
Nothing is inherently a stream of bytes. If all you have is a stream of bytes without a context, you have absolutely no idea what it's supposed to be and no clue how to do anything useful with it.
The whole point of OP is that it should be easy - or at least possible - to access contextual meta-information. Because this makes it easier to to build tools that work with meaning automatically instead of relying on unreliable, partial, and/or broken manual context handling based on unstated or implied assumptions.
You can certainly have a decent idea of what information is there by just looking at the bytes and reverse engineer the protocol. This is how unix pipelines are composed as a matter of fact.
Now, of course it would it be better if each program formally described the schema of its output and the system provided tooling to act on this information, but being able to string together uncooperative programs via their common denominator (i.e stream of bytes), is powerful and the unix way.
Simplicity is a good baseline. In Unix systems, off the cuff scripting works really well for live human interaction.
Complexity, particularly NOT-self-documenting complexity, becomes a nightmare.
Imagine instead that each program controls a special area under /proc/(pid)/ which behave like tmpfs to that program: named interfaces are subdirectories, messages are files.
Reflection of supported interfaces becomes easy. It integrates with existing software, and it's self documenting for both software and users.
Complexity can be opt-in rather than the only way to operate.
> Imagine instead that each program controls a special area under /proc/(pid)/ which behave like tmpfs to that program: named interfaces are subdirectories, messages are files.
This is basically how Plan 9 works (or so I’ve heard).
> Imagine instead that each program controls a special area under /proc/(pid)/ which behave like tmpfs to that program: named interfaces are subdirectories, messages are files.
That's API. Users will depend on it. So now you either have to freeze your code or break users flows.
Even in the 70's it wasn't that great, Powershell "novelty" was a standard way of working across Interlisp-D, Smalltalk, XDE/Mesa and Mesa/Cedar at Xerox.
Having tried many techniques for program-to-program interfacing, I must say that text still is the lingua franca, and I think it's the best "non-standard" to set.
>Unix generally has the correct basis for the design.
I can't disagree with this more, Unix is broken in so many ways and its designs continuously cause me pain. I would not describe a modern Linux or BSD as "simple", maybe the core of it is, but to actually build a modern OS there are so many layers on top of it. And when you do that, the crumminess of the foundation really starts to stand out.
I enjoyed Benno Rice's talk, "What UNIX Cost Us". I think he provides some examples of where the simple interface breaks down when compared to other systems (i.e. Windows, macOS) take on it.
I do NOT want to go back to the times when we had to write and ship individual drivers for each graphics card, sound card and peripheral we wanted to support in our software.
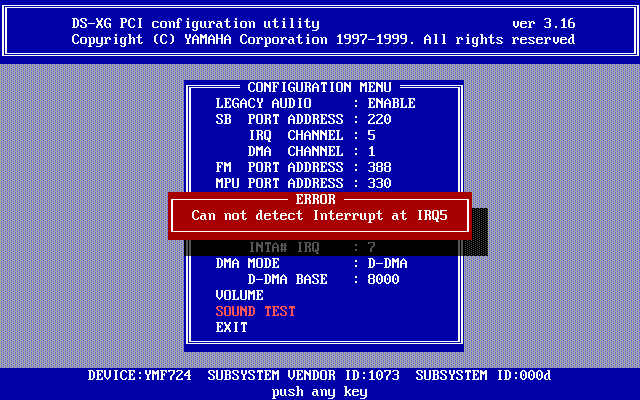
Could you imagine having to select the physical port, IRQ and DMA channel of your sound device for each app that wants to output sound? Because that's what had to be done in DOS and screens like this https://flaterco.com/kb/audio/PCI/DS-XG_IRQ_error.png
were commonplace. Good enough if you had well-defined devices like SoundBlaster(Pro) or GUS that you could auto-detect without crashing the PC, but a living nightmare with clones that didn't quite behave the same way.
So unless you only plan to support a single set of well-defined hardware, device drivers are a must.
> I do NOT want to go back to the times when we had to write and ship individual drivers for each graphics card, sound card and peripheral we wanted to support in our software.
This 1000x - I remember this time and it was quite painful
>Could you imagine having to select the physical port, IRQ and DMA channel of your sound device for each app that wants to output sound? Because that's what had to be done in DOS and screens like this https://flaterco.com/kb/audio/PCI/DS-XG_IRQ_error.png were commonplace. Good enough if you had well-defined devices like SoundBlaster(Pro) or GUS that you could auto-detect without crashing the PC, but a living nightmare with clones that didn't quite behave the same way.
I also remember the application working one second, unrelated hardware change (1), and back to the drawing board all over again
In the (post)modern world, every device should have its driver built-in (along with a CPU to run it on). The communication protocol (the command language) should be standardized for each given class of devices. The protocol should support the ability to upload custom “shaders,” whenever this makes sense, to tweak or extend the default behavior.
> In the (post)modern world, every device should have its driver built-in (along with a CPU to run it on). The communication protocol (the command language) should be standardized for each given class of devices.
We are currently in this world. NVMe, USB, etc. NVMe for example is "just" DMA'd ringbuffers of requests and responses.
One challenge is that vendors tend to want to have "special features" that go beyond the standard command set. SCSI and SMART are examples of that pain.
> The protocol should support the ability to upload custom “shaders,” whenever this makes sense, to tweak or extend the default behavior.
This part is crazy complex and not very likely to happen. "Shaders" in the context of GPUs can work because it's a very large & expensive component and very vendor-specific already. That approach won't work for a chip that costs $2, with the additional burden of needing to have the same programming interface for competing vendors.
{kind=link}
I think modern OS stacks are in a similar boat, at least Windows and macOS. True low level control is kind of a pain, but the OS libraries are not particularly pleasant or high level enough either. So largely things like Electron or Qt are acting as the defacto OS anyway to varying degrees of success but undeniable levels of resource waste. I wonder if modern languages and tooling and such are advanced enough that the OS should become more primitive and minimal. In a way it feels like we're moving there anyway with web tech becoming the defacto user space and toolkit. That's fine, but god if it wasnt all built on 50 layer of cruft our machines would be screaming fast.
Smalltalk, if you get a chance to use it, really does act like its own OS in so many ways. It's great as a programmers OS really, although it doesn't really hit the right notes for average use. Still though, if someone had the urge to build it I could easily see a smalltalk based userland built on like a linux kernel (with no gnu user space) being a totally viable thing.