As the article points out, this guy is the Z in LZ- which also forms the compression portion of the Deflate algorithm (zip/gzip). A huge portion of the lossless compression algorithms of today are generationally based on Ziv's work.
...and LZ is such a simple algorithm - replacing repeated occurrences of a sequence with a shorter backreference - that I'm surprised it wasn't discovered sooner. Huffman wrote about his algorithm in the early 50s, but LZ only showed up in the late 70s.
The important contribution is not in the simple algorithm (which I suspect others have come up with before, and I know others have independently come up with after):
Rather, it was what Lempel and Ziv proved about both of their simple algorithms -- The one published in 1977, usually referred to as LZ77 which is the basis of all <length,distance> variants, and the one published in 1978, usually referred to as LZ78 which is the basis of LZW, and other <word,char> variants.
They proved that for a very large class of sources (those described by markov models, context trees, among many others), these algorithms asymptotically give the best possible compression. In fact, some applications (also proved correct by Ziv) use the compressed datastream statistics to estimate source entropy, because it's much easier to implement than any direct measurement.
Both Ziv and Lempel did a lot of other things; However, Lempel did more in the area of switching systems and his other contributions are numerous and interesting, but were less profound in any specific field -- Whereas Ziv's contribution to Information Theory through the last 60 years or so has been much more profound.
The pointwise otimality of the LZ algorithm - the fact that it beats every other information-lossless finite-state compressor like Huffman encoding asymptotically on /every/
string, is an ingenious theorem. For versions of the algorithm (LZ77 in particular), it was open till the late 1990s when Paul Shields settled it.
The algorithm is easy, but the analysis of its effectiveness is not at all easy.
I think repeated sequences in data only became relevant when there was large image data. I mean, like Shannon was concerned about language transmitted.
Not at all. Shannon's work is incredibly profound, and deals with distortion of analog signals, channel capacity under different constraints, and many other things. He was very much aware and discussing repeated sequences in the 1952 class in which Huffman constructed his code and proved it is optimal. (According to lore, Shannon said "hey, Fano and I have this Shannon-Fano code, which we know is close but not optimal. Improve on it and you can skip the final")
Shannon's original paper, "A mathematical theory of communication" is very readable (especially discrete sources and channels; you need some calculus for the continuous sources and channel stuff), and yet touches on many things and has many insights. At least as late as 2000, one very-well-published prof at the uni I was attending told me that whenever he wants to break out to a new direction, he rereads it 5-10 times and realizes another thing that Shannon considered trivial and that was yet unexplored.
Also, there's basically no repeated sequences in large image data. JPEG, H264 and all their friends are all about compressible approximations that are still close enough, and which rarely if ever have repeated data.
The first compression algorithm I implemented (on and IBM PC/AT in the mid '80s) was LZW. It's my favorite type of algorithm - elegant but hard to get your head wrapped around. Once you "get it" it seems so obvious.
LZW is just a (nontrivial and very effective) trick to improve on the early behavior of LZ78; they are both asymptotically optimal.
LZ78 is incredibly simple, elegant AND easy to get your your head around. I had implemented it once in 2 lines of Python. some 25 years ago. If I can shake the rust maybe I'll be able to rederive it.
Nearly all break through inventions seem obvious in hindsight. I guess putting the pieces together and connecting the dots looking forward is what’s incredibly hard. The search space can still be immense.
The LZ algorithms are like magic. LZ78 factorization can be written in 5 line of python, and then can be used in a mysteriously effective distance metric. The power of math and "useless" Kolmogorov complexity!
Back when I attended faculty, I had a project assigned to me titled "Lempel-Ziv compression of binary strings" or something like that. It was one of the most fun projects I worked on.
I understand there is a tradition in papers to put the primary author first but in the end, it is the letter Z almost became synonymous with compression.
.Z, .zip, .7z, .gz, .xz, .bz2. Of course, many use LZ77 or LZMA, LZ stands for Lempel–Ziv, but only the Z remained in the format.
To be pendantic: Nobody today uses LZ77. LZ77 is quite primitive and not very efficient. However, nearly everyone today uses an algorithm that is descended from LZ77, so "LZ77" is just a sort of shorthand for "any algorithm descended from LZ77". LZMA and Zip's deflate are both examples of LZ77 descendants.
(To be even more pedantic, all modern algorithms are descendants of LZSS, which was one of the first improvements on LZ77.)
Out of the ones you listed, only .Z and .bz2 are not LZ77-LZSS descendants.
.Z is an implementation of LZW, which is a descendant of LZ78, which is a significantly different (but still related) algorithm to LZ77. It never really caught on beyond a few implementations of LZW, though.
.bz2 is the only one completely unrelated to Ziv's work. It uses the Burrows-Wheeler transform, instead.
I've been trying to figure out where the first z comes from. At least I tend to think "z" is for compression because of ZIP, but it predates that.
.Z was used for compress(1), probably because pack(1) used .z, but where did that come from?
My best theory is that it's from Steve Zucker who wrote pack(1) at RAND. There were other versions of pack(1) too, but if his was the first, it seems possible that he choose the z extension for Zucker.
It uses the Burrows-Wheeler transform and Huffman coding. It is one of the few lossless compressions algorithms that do not actually build on the work of Ziv.
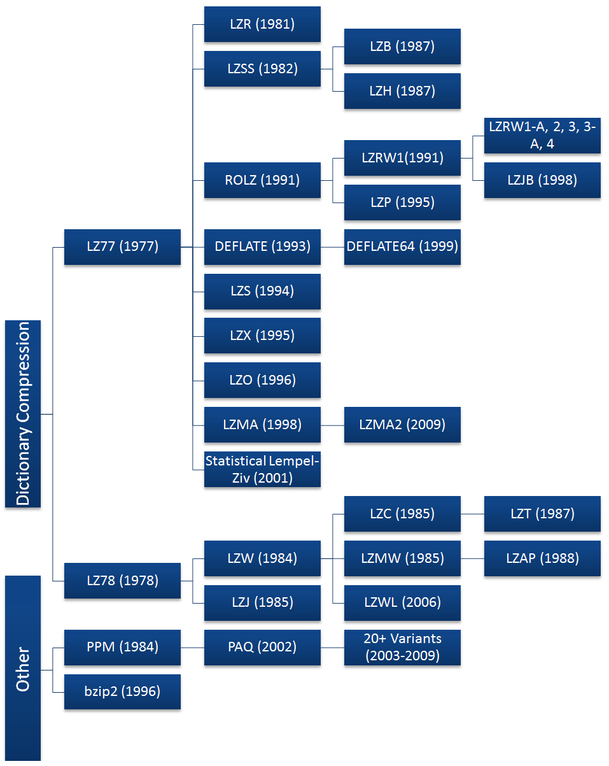
Well deserved. Just in case you were not aware of the variants of LZ[iv] for dictionary based (or sliding window based) lossless compression -> https://tinyurl.com/y3h76c4j
{kind=link}
This is extremely well deserved.