Everything else is basically irrelevant because as Clang has aged it's both slowed down and reached parity in both compile and execution speed. Phoronix even have GCC faster than Clang at building the Linux Kernel, even in an (according to a comment) biased sample where GCC wasn't built with lto enabled. GCC also (last time I tried) does better debug info.
LLVM is much easier to hack on, though, although some parts are more similar than you might expect.
> Clang has aged it's both slowed down and reached parity in both compile and execution speed
A serious question: Is it correct to say that any compiler with state-of-the-art optimization cannot be fast, and clang's previous performance advantages were actually due to the lack of various optimization techniques and other features? And is there any investigation and research on the tradeoff of compiler speed/complexity vs. execution performance? Many minimalist purists claim that modern compilers are evil and it's possible to write a small and fast compiler. Yes, but at what cost? And is the cost too large to be justified, or is it that computers are acutally fast enough?
Sure, there are some language features that can make optimizations pathological complex, but for the most part if compilation speed isn't continuously tracked and strictly enforced against new changes, you inevitably regress into a slower compiler.
For instance, the Go community is highly sensitive to compilation speed. Although the Go compiler is SSA-based like LLVM, it's very selective about the optimizations applied. The Go compiler tracks and benchmarks each phase of the compiler release-to-release to identify major regressions.
Priorities exactly. And these priorities are not only down to the compiler implementation, but also the language design. I'd argue that Rust being much slower to compile than Go has reasons from both sides, and hence will probably never be as fast as Go to compile.
It would be weird if that was not the case, as Go and all its bells and whistles are open source. I found this after a quick search (clicking around will send you to the source code): https://godoc.org/golang.org/x/tools/cmd/compilebench
edit: Ooh, that's nice, I did not know about that, thanks for sharing (especially useful as I'm transitioning to Rust after 10yrs of Go).
> and clang's previous performance advantages were actually due to the lack of various optimization techniques and other features?
Not lack of optimization techniques; LLVM is relatively fast compared to Clang for builds of the Linux kernel. Is it all of the compiler diagnostics and semantic analysis, or just unoptimized code? WIP to find out.
(I literally just went over a perf record of a linux kernel build with a teammate that's going to look into this more; I organized the LLVM miniconf at plumbers which is the video linked in the phoronix article in the grand parent post; my summer intern did the initial profiling work).
For a compilation to object file from source code, the vast majority of time for most translation units when building
the Linux kernel is spent in the front end of the pipeline, not the middle, or backend.
It's possible, although it's worth saying that compilers are still relatively dumb when it comes to actually using their arsenal of optimizations - you can have too much of a good thing, it's quite difficult to have a usable performance/compilation-speed tradeoff.
This isn't a particularly scientific test, but if you compare the assembly for the generated factorial function, the compilers being asked for absolutely breakneck speed correctly identify parallelism in the code, but fail to recognize that the loop overflows almost immediately - it is defined behaviour, so without human intervention it can't guess where we want performance. So the end result is a pretty enormous SIMD-galore function which is not much faster or even slower than the very simple optimize-for-size output.
You may be thinking, well it's faster sometimes, that's good - that is often a good thing, however, code density is very important. The SIMD-gone-mad version is several times bigger than the simple loop. Modern x86 CPU's have a roughly 1-4k μop cache, that might be a whole load of it gone right there. It's a significant dent in the instruction cache too.
If you look down the software stack, we use programs like compilers to invariants in our data and algorithms, act on it, and then promptly throw it away - when moore's law ends this is where we can find a lot of performance, I reckon. In this case we can bully the compiler into assuming the code overflowing won't happen, or highly unlikely, which lets it schedule the code more effectively for our use-case but this requires relatively intimate knowledge of a given compiler and the microarchitecture one is using - it's not really good enough.
I think with SIMD we have a language problem - the for construct is not what we often want to use, but a map. Also lack of distinction of pure and impure functions on most C based languages, basically disallow a lot of opportunities for proper simd.
Maybe that depends on what "state of the art" means? It sounds like it might mean https://en.wikipedia.org/wiki/Superoptimization, but that's so slow-to-compile that I don't think any production compiler does anything like it. It might be that what "state of the art" really means in practice is "the slowest-to-compile level of optimization that regular folks are willing to put up with on a day-to-day basis." In which case, it cannot be fast kind of by definition :)
No, not superoptimization. When I say "state-of-the-art", I meant "up-to-date techniques currently practiced in the industry", not theoretically optimal. For example, "state-of-the-art" cryptography is TLS v1.3, AES-GCM, or the Signal protocol, while a theoretically optimal one might be an "one-time pad" (or superoptimization in your example).
In other words, "We all know standard compilers are slow. Does it mean that for a compiler to reach ICC/GCC/clang's -O2 performance in benchmarks require inherently expensive optimizations? Or is it simply that ICC/GCC/clang's optimizes are poorly implemented in terms of compile performance?"
When I asked this question, I make the distinction between "currently used optimization techniques and algorithms vs their implementations in GCC/clang". How large is the gap? If the gap is small, it means the algorithms as currently used for optimizations are inherently expensive (i.e. a "good" compiler "must" be slow). if the gap is large, it means a much faster implementation is theoretically possible (i.e. a "good" compiler "can" be fast).
LLVM does indeed use known suboptimal algorithms for increased speed. Its register allocator is an example: a "perfect" register allocator is NP complete, and LLVM uses a relatively simple greedy algorithm instead.
I don’t understand why a fast debug build mode and a really slow, but super-optimizing (not necessarilly in the meaning you mentioned in your link) compiler is not more used (I think zig does that). It would be the best of both words, really fast write-compile-test phase, and a production ready, fast binary on release. (i know that -O0-3 is similar, but on the whole it is not as popular as it could)
It's a combination of factors, optimization certainly takes a lot of time, but it's not the only significant factor. The modular multi-pass architechture also takes a toll. If you look at fast c compilers like TCC, you can see that they get their speed primarily from doing fewer passes over the source code. In the case of TCC it only does a single pass, which severely limits the types of optimizations it can do, but if you compare the performance of TCC to that of gcc or clang with optimizations disabled (-O0), TCC is significantly faster. So you can see that the architechture used to make large extensible optimizing compilers like GCC also inherently removes some of their speed.
I believe it is theoretically possible to write many of the optimizations that larger compilers have in fewer passes, but that comes at the cost of complexity and difficulty in debugging different combinations.
The architectural problem can sort of be resolved by holding one's nose and maintaining a parallel (fast) algorithm, the problem is that this is expensive and bug prone. The algorithms that lead to optimal behaviour often don't easily have a sliding scale of performance vs. quality. If TCC had to support VLIW it would be a lot more complicated and slower
It is a trade off. However, you can control those trade offs via the optimization switches. You can compare either builds with no optimization vs full optimization.
It's more complicated than that. You can see what passes are run by clang with the flags -mllvm -debug-pass=Arguments. It's certainly true that -O0 involves fewer passes than -O1 which involves fewer passes than -O2. But the speed limit is defined by the architecture. A compiler that was engineered for compilation speed with a goal of -O1 tier code quality would have a very different architecture from day 1 (e.g. unified IR, fewer passes, integrated register allocation and code generation). There's been attempts at "punching through the layers" over the years with things like fastisel, but there are limits.
That said, all the major compilers can deliver adequate compilation speed on the order of 50-100 kloc/sec for well-structured C code bases. Speed is much more of a serious concern if you're working on large C++ code bases. Or if you're using LLVM as a backend from a language like Julia which does the moral equivalent of C++ template instantiation at runtime and feeds it to LLVM.
The Utrecht Haskell Compiler[1] tried to break through the barrier by using attribute grammars[2] and attempts WHO. This also has the benefit of being more modular. However, Overall GHC still feels faster, I am unsure whether this is due to more costly optimisations or something else.
Looks more like reliability vs speed. Small & fast compilers skimp out on various safety checks and edge cases. Yeah it might mean segfaults and crashes in weird archs and situations, but it's fast on perfect machines.
Rust’s cargo check appears to be quite fast, and afaik offers no less safety checks than a complete build. Of course, I’ve never verified, but there’s a clear and substantial allocation of time spent compiling rust, after all the safety checks.
Windows used BSD network stack because of license. Apple moved away from Bash because of license, etc.
Linux was the inexplicable exception that would allow us all to have true free software, but companies were quick to insert tainted mode so that cheap modem manufacturers dont' have to open source their lazy backdoors and google can ship android phones with not a single open sourced device driver.
Linux is practically the Bernie Sanders of open source.
I deeply believe that if Windows NT had a proper POSIX support, instead the half heart attempts Microsoft was doing, around 1996 no one would have bothered to install Linux.
I had access to Windows NT and ended up getting my first distribution via the Linux Unleashed book, because I needed something at home to save the trips to campus to work on our DG/UX timesharing environment.
If the POSIX subsystem was up to it, I wouldn't need to look elsewhere.
Another what-if scenario is what if Sun, or some of the other Unix vendors at the time [1], had aggressively sold 386 Unix OS'es for clone PC's at a modest price. Aiming for the mass market rather than the low volume high margin workstation business. The world could have looked very different then, Linux might never have seen the light of day, and maybe even killing off Microsoft's ambitions in the OS space beyond DOS and windows 3.x.
[1] Just picking on Sun because they had the Sun386I back in 1988 and the 386 port of SunOS to go with it.
The original NT POSIX subsystem feels like it was there to check a requirements box. Microsoft Interix (originally Softway OpenNT) was really nice, though. I remember playing around w/ it in 2000-2001 and being amazed and what would compile and run.
You’re comparing GCC and clang 12 years later. In a world where Apple didn’t put out clang I think the GCC project would look extremely different. Competition is good because it causes projects to analyze why they are popular and what things they’re doing that might not be wins.
> Everything else is basically irrelevant because as Clang has aged it's both slowed down and reached parity in both compile and execution speed. Phoronix even have GCC faster than Clang at building the Linux Kernel, even in an (according to a comment) biased sample where GCC wasn't built with lto enabled. GCC also (last time I tried) does better debug info.
It's entirely possible that the only reason GCC & Clang are so close is that both projects focused on places where the other project beat them & so have converged. Certainly the LTO work that's been going on is an obvious example where the two projects have learned & pushed each other. GCC's original LTO implementation was basically unusable. Then Clang released ThinLTO & GCC scrambled to add WHOPR (& by my reading of the blog posts the engineer(s) on it have done some amazing work to pull ahead of the Clang team at times).
> Phoronix even have GCC faster than Clang at building the Linux Kernel, even in an (according to a comment) biased sample where GCC wasn't built with lto enabled.
I don't see that this tells us anything negative about Clang. How is it a bad thing for the compiler to give you the option of a very slow build using additional optimisations? If you don't want that, then don't use that feature.
That's not what's going on though. Clang's not slow because LLVM is using additional optimizatons, it's slow because Clang is spending a ton of time in the frontend mostly lexing and keeping track of source locations for macro tokens.
(I literally just looked at a perf record of a whole build of the linux kernel with Clang; and know more about the subject than...anyone).
The performance is basically neck and neck (GCC can be measured to be faster at a few SPEC benchmarks, but they can be contrived and the kernel is often hyper-optimized so the difference may not be down to the optimizer).
GCC in this case gives you equal or as-near-as-makes-no-difference up or down performance in less compilation.
Some rigs are now posting 17s Kernel build times, reasons to be cheerful
Not exactly correct. Rather, RMS resisted attempts to make the compiler more modular based on such arguments, but the initial design wasn't deliberately non-modular. The steering committee had to spend years persuading him not to block improvements that increased modularity, like plugins, and eventually found ways to persuade him.
rms deliberately making GCC (and by extension, Emacs) less useful to "prevent misuse". The entire thread is ... ugh.
The funniest part is that it doesn't even matter, because now everyone and their mother has switched to llvm/clang for these kind of things, just as people in that thread predicted.
I know RMS is often abrasive, but that it is a whole new level of bad faith from him on display there. Plenty of "just asking questions" from one of the other participants as well.
Here's another example of RMS on the subject where he told someone he wouldn't accept their code and that they should take it off of the internet and not talk about it:
I don’t see what is so bad faith about his post. His response and his intent are not malicious.
On principle he is against proprietary software and he wants to make sure it remains as difficult as possible for proprietary software to exploit GCC for their own means.
He doesn’t seem to be rejecting the code or suggests its deletion because he wants to do unnecessary harm to the author here. His intentions seem rational and consistent with his past remarks.
As an aside and for comparison, proprietary software companies are just as defensive or more with other companies using their IP without compensation. The compensation RMS wants here is code reciprocity.
His intent might not be malicious, but accusing the other person of doing something to undermine free software that's so bad it should be "cancelled" is not very nice.
He certainly isn't advocating for code being free here, it's literally the opposite.
rms' entire problem is that he fails to understand there is more than one way to advocate user freedom.
My viewpoint, which is also the viewpoint of pretty much everyone in that thread, is that the best way is to write the best possible software possible. Same goals, just different methods. But there isn't even a discussion about that here, it's just a hard shutdown of these type of arguments from rms.
Is it any surprise that almost any project rms has any technical influence on has been in decline?
As quick as the search may be, it isn’t good to search out sources for someone else’s claim because what you find may not be what they are citing and you may assume they are making a point they are not.
- and let's include 2 other compilers that aren't really even in the game so it looks like we did due diligence as opposed to just writing a rejection of GCC.
They are asking for suggestions, perhaps these 2 other compilers were suggested?
By the way you should be aware there is 100% no requirement for Apple to defend their choice for a compiler. They can choose whatever they want for any reason or no reason at all. If they don’t choose your favorite compiler it’s not some kind of evil conspiracy.
They made a choice and published a document describing their thought process and you can take it or leave it.
>> By the way you should be aware there is 100% no requirement for Apple to defend their choice for a compiler.
Of course they don't need to. But they did - or rather this is a justification, not specifically a defense. I was just adding on to the previous posters suggested reasoning, which is hinting at something more like a cover story for using non-GPL compiler. Of course they are free to do that too, but no need to publish silly comparisons to justify, rationalize, or defend it.
But since both of these were targeting MS-DOS/Windows only It wasn't until 2011 and two owners later that C++Builder was really a cross-platform compiler.
This is a cool repository! fairly old, as others have noted.
There's a directory [1] containing some "historical notes" written by the creators of llvm: Chris Lattner and Vikram Adve. One of them is the original clang readme [2].
> GCC does not require a C++ compiler to build it
> GCC front-ends are very mature and already support C++. clang's support for C++ is nowhere near what GCC supports.
These things were true when Apple first went with Clang, and this document must date from that time.
GCC is now implemented in C++, and Clang’s C++ support is excellent. The only issue I have with my c++17 code in Clang is I can’t yet rely on recursive template parameter pack deduction.
Maybe in libstdc++, but what else would you use there.
I wanted to know what register allocation algorithms GCC implements, but I can't even find it. It's all files with cryptic names and hundreds in one directory. You can find _even less_ documentation, talks and blog posts about GCC internals :(
> Clang does not implicitly simplify code as it parses it like GCC does. Doing so causes many problems for source analysis tools: as one simple example, if you write "x-x" in your source code, the GCC AST will contain "0", with no mention of 'x'. This is extremely bad for a refactoring tool that wants to rename 'x'.
Can someone explain this Clang “pro”? If a refactoring tool wants to rename “x”, it does it to the source, not the AST, no? And if “x-x” is turned into 0 by the parser, why does it matter? Assuming “x” isn’t volatile, “x-x” is indeed 0!
> If a refactoring tool wants to rename “x”, it does it to the source, not the AST, no?
A textual find and replace isn't sufficient because multiple variables might be named ‘x’ and you wouldn't want to rename all of them, just the one you're interested in. The only way to know which occurrences of ‘x’ are your ‘x’ is by parsing the source into an AST and then performing analysis on it. Once you know the file locations, then the source itself can be modified. So to summarize, yes you are correct that the source is modified, but an AST + analysis is needed to find the correct locations.
A refatoring tool might want to offer semantic renaming. If 'x' occurs in many places textually in the source, the only way to be sure that a rename operation only acts on the same variable, (rather than just the same string) is to (at least partially) parse the source, act on the resulting AST, and use source information in the AST to apply the change to the source.
So, to avoid maintaining a separate parser, it would be nice to grab an AST from the compiler - but that AST has to match 1-1 with the source to be useful for refactoring.
Can't you resolve this by doing a bit of extra work in scopes that have e.g. 'x' in source but not in the corresponding AST? I wasn't sure if generated ASTs were 1-1 matched with source top-level scopes, but apparently they are:
It's a bit more work than cases where AST matches source level expectations, but can't you just walk that sub-tree and figure out that '0' was 'x - x'?
Having an AST that maps (nearly?) 1:1 to the source code is important for debug info and doing proper error messages, so doing this at the AST and writing it back out is going to be much easier to test (prove, even).
The "source"-level rewriting tool is going to build some kind of code and data structure that... parses and performs semantic analysis of the code.
Also, if x-x gets turned into zero by the parser just scrap the project and bring out the firing squad.
No, normally refactoring is applied on the AST, which is then matched back to the source. The source is raw text, you can't refactor raw text directly - you need the AST to do any kind of meaningful refactoring (you often need more than the AST to do interesting refactoring).
That makes sense. But if gcc doesn’t expose the AST (like clang does), why does it matter what its parser does? This “comparison” even says such:
> GCC is built as a monolithic static compiler, which makes it extremely difficult to use as an API and integrate into other tools.
Obviously, if gcc exposed the AST with an API, changing "x - x" into 0 would be bad for refactoring, but they don’t (at least when this was written a decade ago).
It is relevant to why Apple made the clang switch back when that happened, though (at least, inasmuch as there were any reasons other than "GCC is GPL and doesn't work well as a library and we want to integrate it more closely with Xcode").
Can't talk about superiority of one compared to the other without viewing the landscape of the develop, it needs to run fast, be easy to debug, compile fast. There are trade offs for all. Most serious devs likey run several ide and build chains, ea h offering its own value. For example if you want clean template debugging clang lldb is pretty nice
Slight offtopic: anyone else annoyed by the darwins crappy support for static linking and general extreme lack of documentation? E.g lack of -Bstatic option and similar?
the problem is that macos's kernel API isn't stable at all (like, even across minor macOS versions, and I have heard rumors that different mac hardware may get different kernels... though not sure about that one). So you can't statically link libc / libSystem unless you want your app to only work on one machine.
Yeah I’m actually fine with that part. Even application level libs are still mostly dynamically linked and you can’t for example take a .dylib and link it statically (not with standard tooling at least)
... what do you mean then ? static linking your own dependencies does not require anything specific. I ship an app that statically links qt, ffmpeg, llvm, and a few other massive libs without issues.
Although it should perhaps be noted, they aren't packaged as they are in Linux, right? Apps generally ship their own copies of libraries inside of the app bundle, and it's perfectly common to have multiple copies of a library as a result. I'm sure I have at least ten versions of the Sparkle framework for instance!
This conveniently avoids most of the downsides of dynamic linking, except I don't think you get any of the upsides, either—which is to say I'm not sure what the point is. I kind of like it because, since I don't mind breaking code signatures, I can replace the frameworks in third party apps with updated copies. But I'm pretty sure that's not Apple's intended use!
You can reboot the system to take care of the reload. That's vastly simpler than updating all dependent programs, especially since updating dependent programs would likely come with other changes that you may not be ready for.
And yes, this is mostly useful for taking bug fixes, which most mature libraries release without API changes.
I disagree about “vastly simpler”. Only when you disregard all the complexity that managing shared libraries bring. Presumably all dependent packages will ship their own updates at some point and will be rebuilt anyway. And yes in a very specific case of having to emergency ship critical fix shared library is slightly advantageous but at what cost?
If by "reload" you mean "drop in an updated shared library and let the runtime loader do its job", I suppose so.
Yes, it only applies if you don't make any API (and ABI) changes, but that's what major, minor, patch versioning is for, and stable projects can go a long way on minor and patch versions...
The individual app developers have to update their apps to use newer OpenSSL. I don't see this as a problem because the app's developers generally need to test their software with updated OpenSSL anyway, in order to make sure everything still works.
Interestingly, I've seen some internal Apple stuff get sent upstream to LLVM.
One example is ILP32 support for AArch64, which is apparently used in the Apple Watch. It looks like all of Apple's modern SoCs are 64 bit only, and in order to reclaim some memory on constrained devices, they're using ILP32 and a 32 bit address space, with 64 bit registers and such. https://lists.llvm.org/pipermail/llvm-dev/2019-January/12978...
It's honestly not that surprising, keeping the difference between their fork and upstream minimal makes it easier for them, so for things that they don't consider to be their 'secret sauce' it's easier to have the community involved in maintaining it (and everybody ends up winning).
Yes, but that is Apple's choice rather than a licensing requirement. Apple upstreams a ton of stuff, AArch64, GlobalISel, .... But they do this by choice.
They get upstreamed for the most part, just very slowly. There's a lot of pointer authentication stuff shipping in their toolchains currently that isn't upstream.
not really...Apple upstream most of their AArch64 backend implementation, just like PlayStation upstream most of their (PS4) toolchain code. The rationale behind this is that maintaining a separated downstream actually has a (surprisingly) high cost.
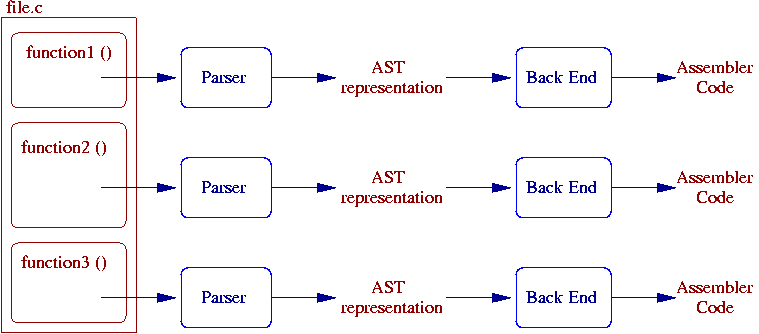{kind=link}
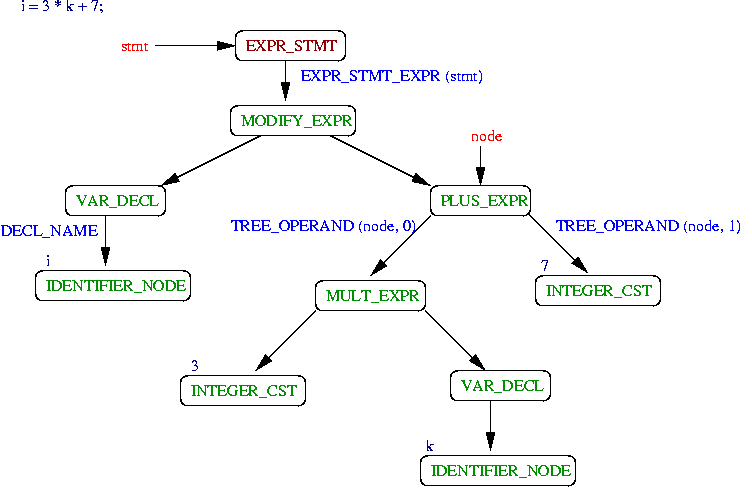{kind=link}
- Not designed to be difficult to extend
Everything else is basically irrelevant because as Clang has aged it's both slowed down and reached parity in both compile and execution speed. Phoronix even have GCC faster than Clang at building the Linux Kernel, even in an (according to a comment) biased sample where GCC wasn't built with lto enabled. GCC also (last time I tried) does better debug info.
LLVM is much easier to hack on, though, although some parts are more similar than you might expect.
https://www.phoronix.com/scan.php?page=news_item&px=GCC-Fast...
You should try and fettle with both to see what works best for your project.