I once read a quote that was something like "You are only an expert in a given technology when you know when not to use it". Unfortunately I forgot the exact quote and the author. (If anyone knows please let me know).
This is such a nice quote that speaks a lot about what it means to be an experienced (senior) software engineer. Our field is such a dynamic one! New tools and techniques appear all the time.
It's easy to fall into the trap of thinking that newer tools are better. I think this is because in some areas of tech this is almost always true (e.g. hardware). But in software, new tools are techniques are rarely fully better, instead they just provide a different set of trade offs. Progress doesn't follow a linear pattern, it's more like a jagged line slowly trending upwards.
We think we are experienced because we know how to use new tools, but in reality we are only more experienced when we understand the trade offs and learn when the tools are really useful and when they are not.
A senior engineer knows when not to use micro services, when not to use SQL, when not to use static typing, when not to use React, when not to use Kubernetes, etc.
Junior engineers don't know these trade offs, they end up using sophisticated hammers for their screws. It doesn't mean that those hammers are bad or useless, they were just misused.
Progress doesn't follow a linear pattern, it's more like a jagged line slowly trending upwards.
Recently (as in the past few years), it feels more like it's not trending upwards anymore, just jumping around an equilibrium point and maybe even slowly declining.
Junior engineers don't know these trade offs, they end up using sophisticated hammers for their screws.
They also end up making hammer factory factory factory factories.
"Why the hell are people so impressed by boring architectures that often amount to nothing more than a new format on the wire for RPC, or a new virtual machine? These things might be good architectures, they will certainly benefit the developers that use them, but they are not, I repeat, not, a good substitute for the messiah riding his white ass into Jerusalem, or world peace."
"Remember that the architecture people are solving problems that they think they can solve, not problems which are useful to solve. Soap + WSDL may be the Hot New Thing, but it doesn’t really let you do anything you couldn’t do before using other technologies — if you had a reason to. All that Distributed Services Nirvana the architecture astronauts are blathering about was promised to us in the past, if we used DCOM, or JavaBeans, or OSF DCE, or CORBA."
Note: that kind of "selling points" was "promised to us in the past" even then.
Also, not even distributed anything is necessary for architecture astronauts, one can "architect" any task:
The oldest form of "architecture astronauts" food I personally had to fight against was Grady Booch's "Object Oriented Analysis and Design With Applications" from 1991/1994. It resulted in many enterprises wasting immense amount of time even in the nineties.
You are making a lot of ageist remarks. There are plenty of Senior engineers making wrong decisions. For example the istio project moved from microservices to monolith - https://blog.christianposta.com/microservices/istio-as-an-ex... and none of those engineers are "junior engineers" by any means.
"You are only an expert in a given technology when you know when not to use it"
This is such a great quote. I would also love to know the origin.
I'll also bite on the when not to use static typing bit. Not using static typing is a bit of a misnomer because you can use a statically typed language and just use `String` (or `Bytes`, `Object`, `Value` or whatever the equivalent is in your language). The question is more of whether to use one of these catch-all structures or to use a more structured domain-specific type. And the answer here is when you don't need all of the structure, don't want to force the whole thing to validate, etc. For example, maybe you have JSON getting read into some complex customer data structure. If you only need a single field out of the structure, and haven't already parsed it into the customer data structure for some other reason, it might be best to just reach in and grab the field you need. You can think about it kind of as the principle of least context but in a data parsing scenario.
FWIW, there's a very old Russian joke that goes like "a novice doesn't know how to do it, a pro knows how to do it, and an expert knows how to avoid doing it".
I'd kinda prefer it then, too. If it's short and I'm just scripting stuff up it's probably mostly calls to existing code (libraries) so almost all the static typing would do is tell me when I'm screwing up and give me hints for valid arguments with types and names, with little or no added overhead. It'd be very nice.
Consuming types in that context is nice, defining them is what's generally a PITA / extra boilerplate / overhead.
To take a concrete example that could go both ways: Say you want to parse a JSON blob for some task. On the one end, you could access it through dynamic typing, or tools like jq, that don't need a schema for the entire data format. At the other extreme, you could make typescript definitions defining a schema for the entire format.
The more the same data gets (re)used, the more worthwhile taking the time to define a full schema is. But to download and add type definitions (often out of date and in need of further tweaking) for every once-off API request? Way more effort than it's worth.
Most static type systems do not force you to say what’s the entire shape of the data, just what the shape of the data you need is.
In fact its a good practice to do in general. So that when processing the json blob you tell what only your processing requires.
What you get is that if for example you do your validation, but then by chance you touch more data that you’ve checked for, the types will tell you you are dangerous waters, and you can go update the validations.
This is especially useful if you’re not the original author or if you’ve written it several months back and don’t remember the details.
Static types are really cool that way, and can be treated as just a faster to write and faster to run and always up to date unit test.
For me it's where I'm developing a task to do stream processing and classify the data by an arbitrary subset of the data and don't want to model the entire structure to avoid losing/changing the original
data structure.
I'm sure there's better ways to do this, but that's an example I'll throw in.
My heuristic is that if anyone else will ever read the code, it should be statically typed (or be written in a language like shell where the language is essentially limited to one type).
Most people disagree, but then they end up writing giant python monoliths with layers of implementation inheritance, dependency injection and functional programming paradigms.
In the end, they try to port it to pretty much any other language, but at that point it’s too late.
In my experience, microservices grew to prominence not because of their technical merit, but because it allowed engineering "leadership" to not have to make decisions. Every developer or group of developers could create their own fiefdoms and management didn't have to worry about fostering consensus or team efforts, all that had to be agreed on was service contracts.
We end up with way too many developers on a given product, an explosion of systems that are only the least bit architected, but thankfully the vp of engineering didn't have to worry themselves with actually understanding anything about the technology and could do the bare minimum of people management.
Individual minor wins, collectively massive loss.
* there are reasons for microservices at big scales, if everyone is still fitting in the same room/auditorium for an all-hands I would seriously doubt that they're needed.
And the worse it that it just gets rebooted every couple of years.
Anyone doing distributed computing long enough has been at this via SUN RPC, CORBA, DCOM, XML RPC, SOAP, REST, gRPC, <place your favourite on year XYZW>.
<pedant>ONC-RPC and DCE/RPC and MSRPC and JRMI are dupes</pedant> ;)
That said, I recently ended up looking at the code so far and thinking "I should have used CORBA". And nothing so far managed to dissuade that thought...
> However, your codebase has now to deal with network and multiple processes.
Here's the thing I see repeatedly called out as a negative, but it's a positive!
Processes and networks are amazing abstractions. They force you to not share memory on a single system, they encourage you to focus on how you communicate, they give you scale and failure isolation, for force you to handle the fact that a called subroutine might fail because it's across a network.
> f your codebase has failed to achieve modularity with tools such as functions and packages, it will not magically succeed by adding network layers and binary boundaries inside it
Functions allow shared state, they don't isolate errors. Processes over networks do. That's a massive difference.
If you read up on the fundamental papers regarding software reliability this is something that's brought up ad nauseum.
> (this might be the reason why the video game industry is still safe from this whole microservice trend).
Performance is more complex than this. For a video game system latency might be the dominating criteria. For a data processing service it might be throughput, or the ability to scale up and down. For many, microservices have the performance characteristics that they need, because many tasks are not latency sensitive, or the latency sensitive part can be handled separately.
> would argue that by having to anticipate the traffic for each microservice specifically, we will face more problem because one part of the app can't compensate for another one.
I would argue that if you're manually scaling things then you're doing it wrong. Your whole system should grow and shrink has needed.
> They force you to not share memory on a single system, they encourage you to focus on how you communicate, they give you scale and failure isolation, for force you to handle the fact that a called subroutine might fail because it's across a network.
The problem: distributed systems are hard to get right. Better stay away from them unless you really need them, AND you have the time/resources to implement them correctly. The benefits of microservices are a bad excuse, most of the time.
Heh, I have a masters degree focused on distributed systems. My thesis was about tracing and debugging in microservice-style systems. I generally write monoliths, on purpose. The massive overheads and debugging nightmares are not worth it most of the time.
Global state still gets pushed out into backend services (redis, postgres) and I can still scale horizontally all day, but there’s no crazy chain of backend interservice HTTP requests to cause no end of chaos :)
Honestly, you're probably better off looking at https://opentracing.io/. For a bit of context, I started working on my thesis in 2009 when there weren't many commercial tools available for doing this kind of tracing; by time I was done, there were a ton of open source and commercial tools available.
> If you read up on the fundamental papers regarding software reliability this is something that's brought up ad nauseum.
I don't believe there are any papers that show that adding network hops to an application makes it more reliable. I would be extremely interested in any references you could provide.
> for force you to handle the fact that a called subroutine might fail because it's across a network.
That just adds one failure mode to the list of failure modes people ignore due to the happy-path development that languages with "unchecked exceptions as default error handling" encourage.
> Functions allow shared state, they don't isolate errors. Processes over networks do. That's a massive difference.
Except not, because "just dump that on a database/kv-store" is an all-too-common workaround chosen as an easy way out. This problem is instead tackled by things such as functionally pure languages such as Haskell and Rust's borrow checker, and only up to a certain degree at which point it's still back into the hands of the programmer's experience; though they do help a ton.
> Except not, because "just dump that on a database/kv-store" is an all-too-common workaround chosen as an easy way out.
Then maybe we should be criticizing that instead? Like, that'd still happen with Haskell or Rust (or, in my experience, Erlang, with that KV store specifically being ETS). Seems like that's the thing that needs addressed.
> That just adds one failure mode to the list of failure modes people ignore due to the happy-path development that languages with "unchecked exceptions as default error handling" encourage.
There are only two meaningful failure modes - persistent and transient. So adding another transient failure (network partition) is not extra work to handle.
> Except not, because "just dump that on a database/kv-store" is an all-too-common workaround chosen as an easy way out.
Just to be clear, microservices are not just separate binaries on a network. If you're not following the actual patterns of microservice architecture... you're just complaining about something else.
>Just to be clear, microservices are not just separate binaries on a network. If you're not following the actual patterns of microservice architecture... you're just complaining about something else
So what you're saying is that the way to avoid this problem in a microservice architecture, is to be disciplined and follow the right patterns. Then couldn't I just follow the same patterns in a modular monolith (eg: avoid shared state, make sure errors are handled properly, etc) and get the bulk of the benefits, without having to introduce network related problems into the mix?
> Then couldn't I just follow the same patterns in a modular monolith (eg: avoid shared state, make sure errors are handled properly, etc) and get the bulk of the benefits, without having to introduce network related problems into the mix?
Sure. Microservice architecture is a set of design patterns and a discipline for knowing how to structure your applications.
Many, including myself, would argue that by leveraging patterns such as separate processes as a focal point for the architecture leads to patterns that are harder to break out of and abuse, but of course anyone can do anything.
Error handling is the easiest one. With any 'service oriented' approach, where processes are separated, you can't share mutable state without setting up another service entirely (ex: a database). Microservices encourage message passing and RPC-like communication instead, and it's much easier to fall into the pit of success.
Could you do this with functions? Sure - you can just have your monolith move things to other processes on the same box. Not sure how you'd get there without a process abstraction, ultimately, but you could push things quite far with immutability, purity, and perhaps isolated heaps.
Because engineering discipline is actually hard. Not necessarily in the "here is how you do it" sense, just in the sense of getting the buy-in from engineers and engineering leadership that will make it happen.
This is like the one thing that microservices might actually be sort of good at: drawing a few very hard boundaries that do actually sort of push people in the general direction of sanity, e.g. it's easier to have basic encapsulation when the process might be on another computer...
I cannot figure out how you can see that. RPC just adds a "Remote" on top of the "Procedure Call" part, we add a failure mode but the thought process is the same.
As witnessed by many teams, spaghetti happens just as poorly in a distributed monolith as it does in a proper monolith, it just adds latency and makes it harder to debug.
The boundaries you're imagining are not drawn by the technology nor by the separate codebases, they're drawn by the programmers making the calls. And I guarantee you that the average developer with their usual OOP exposure can understand much more easily where to draw decent boundaries following some pattern like Clean/Hexagonal/Onion/Whatever Architecture as opposed to microservices, where it's far more arbitrary to determine the concerns of a microservice, specially when a usecase cuts through previously drawn boundaries.
> Functions allow shared state, they don't isolate errors. Processes over networks do. That's a massive difference.
>
> If you read up on the fundamental papers regarding software reliability this is something that's brought up ad nauseum.
I think you missed the point - just using separate processes does not guarantee you separate errors and state between services, there's lots of ways to get 'around' that. What if the two services talk to the same database/service? What if there's weird co-dependencies and odd workarounds for shared state? What if one service failing means the entire thing grinds to a halt or data is screwed up?
Now that said, yes, if you use good development practices and have a good architecture microservices can work quite well, but if you were capable of that you probably wouldn't have created a non-microservice ball of mud. And if you're currently unable to fix your existing ball of mud, attempting to make it distributed is likely going to result in you adding more distributed mud instead. In other words, the problem here isn't really a technical one, it's a process one. And using their current failing processes to make microservices is just going to make worse mud, because they haven't yet figured out how to deal with their existing mud.
If you're talking about 'over a network', sorry I left that out, but I'd argue it's largely implied. That said, if you add 'over a network' there nothing that I said changes.
My point is that microservice architecture is not just the singular pattern of "code talking over the internet", but a collection of patterns and techniques, focusing on when and where to split up code, and to focusing on the communication strategy you use.
You can 'get around' microservice architecture by not doing it. The point is that if you're familiar with it it's a lot easier to 'accidentally' be successful - or at least, that's the proposition.
> My point is that microservice architecture is not just the singular pattern of "code talking over the internet", but a collection of patterns and techniques, focusing on when and where to split up code, and to focusing on the communication strategy you use.
> You can 'get around' microservice architecture by not doing it. The point is that if you're familiar with it it's a lot easier to 'accidentally' be successful - or at least, that's the proposition.
I don't disagree with your definition (Though I think it's a hard sell to say that's the "correct" definition, when it really depends on who you ask), but the things you described aren't exactly novel programming concepts unique to or invented by microservices. I could say the same things about OOP - modularity and API design aren't new things.
With that, the idea that things like shared state are removed due a network being between the services just isn't true, it still requires design effort to achieve that goal - I would argue the same design effort as before. And if your previous design efforts and development practices (for whatever reason) did not lead to good designs, and you're not actually making an attempt to fix the existing issues along with the reasons why you were making such decisions, then you're likely just going to repeat the same mistakes but now with a network in-between.
And yes, to an extent I agree it's not "really" microservices at that point, you're just emulating something that "looks" like microservices when it's really a ball of mud. But can't you just as easily argue they weren't creating a proper "monolith" to begin with?
> the things you described aren't exactly novel programming concepts unique to or invented by microservices.
I don't think anyone has ever claimed novelty in microservice architecture. It's very clearly derivative.
Shared state is moved. You get some level of isolation simply from the fact that there are two distinct pieces of hardware operating on state. You can then move state to another piece of hardware, and share that state between services (somewhat discouraged), but this is a much more explicit and heavy lift than just calling a function with an implicitly mutable variable, or sharing a memory space, file system, etc.
> But can't you just as easily argue they weren't creating a proper "monolith" to begin with?
Maybe. You can say this about anything - there's no science to any of this. I could say functional programming leads to better code than oop, but I couldn't really prove it, and certainly you can still do crazy bad garbage coding things with FP languages. But I would argue that the patterns that make up microservice architecture can help you make bad things look bad and good things look good. It's not magic fairy dust that you can just use to make your project "better" by some metric, but no one informed would ever claim so.
> Functions allow shared state, they don't isolate errors.
So why not use Haskell (or other pure language)? It's pure, so functions don't share state. And you don't have to replace function call with network call.
You'll never achieve the level of operational stability of an air gap that you would without a strictly in process system.
Shared state is part of it. Isolation of failure is another. Your Haskell code can still blow up.
Immutability makes that way easier to recover from, but it's just one part.
Of course, microservices are much more than processes over a network, they're a discipline. And I think one can go much further than microservices as well - microservice architecture doesn't tell you how processes should communicate, it's more focused on how they're split up, and leaves the protocol to you. Good protocol design is critical.
> They force you to not share memory on a single system,
So instead people use a single SQL database between 20 microservices.
> give you scale and failure isolation,
Only if you configure and test them properly, and they actually tend to increase failure and make it harder to isolate its origin (hello distributed tracing)
> force you to handle the fact that a called subroutine might fail because it's across a network
They don't force that at all. It's good when people do handle that, but often they don't.
> I would argue that if you're manually scaling things then you're doing it wrong
And I would argue that if people are given a default choice of doing the wrong thing, they will do that wrong thing, until someone forces them not to.
Microservices allow people to make hundreds of bad decisions because nobody else can tell if they're making bad decisions unless they audit all of the code. Usually the only people auditing code are the people writing it, and usually they have no special incentive to make the best decisions, they just need to ship a feature.
If your teams are defaulting to doing the wrong thing in every case, you are having a crisis of leadership.
The problem might lie in your technical leadership (e.g. making bad design decisions and failing to learn from experience) or from product leadership (e.g. demanding impossibly short turnaround on work, leading to reliance on solutions that are purely short term focused).
Well, I'd answer that with two things 1) good leadership is probably rare, and 2) doing the wrong thing isn't always wrong.
In my experience, the best leadership comes from people who don't hyper-focus on one thing, but are constantly thinking about many different things, mostly centered around the customer experience (because that's the whole point of this thing: to make/sell/run a product, not to have perfect software craftsmanship). I find those people rare and usually not working at lower levels of a product.
In a sense, doing the wrong thing is perfectly fine if you don't need to be doing the right thing to provide a great customer experience. Of course maintainability, availability, recoverability, extensibility, etc are all necessary considerations, but even within these you can often do the wrong thing and still be fine. I have seen some truly ugly stuff in production yet the customers seemed happy. (though there were probably some chronically sleepless engineers keeping it alive, which sucks and shouldn't happen)
I don't like microservices because of how poorly they're usually implemented by default. But at the same time, even poorly implemented microservices give some great benefits (more rapid/agile work, reusability, separation of concerns, BU independence), even if you're struggling against some harmful aspects.
> Processes and networks are amazing abstractions. They force you to not share memory on a single system, they encourage you to focus on how you communicate, they give you scale and failure isolation, for force you to handle the fact that a called subroutine might fail because it's across a network.
Stop on! Its so much easier to enforce separation of concern if there is an actual physical barrier. Its just to easy to just slip bad decision through peer review.
Stop off! Drop a bunch "microservices" into the same network without any access control and you don't have a physical barrier at all! In fact, it becomes even harder to have a clue as to what's interfacing with what unless you can observe your inter process traffic.
This is a completely unrelated issue. Microservices have nothing to do with access control. If anything, they should lend themselves to more fine grained control, but again, microservice architecture says nothing about it.
Unrelated? I' beg to differ. More to the point, all systems have an access control model. It could be explicit or implicit depending on how the system is built. Regardless, it defines the barriers and boundaries between everything in the system.
The comment suggests that just by separating things in the popular sense of microservices results in a barrier to enforce separation of concerns. That's how I read it, at least, and I find that to be is misleading.
This is the crux I see around popular discourse of microservices. It's often presented without a broader context.
This is exactly the point of the original article by Monzo. Microservices don't provide any tool to deal with access control, thus you have to implement it yourself. I rather avoid that when I can.
Plenty of languages allow to write modular code, all the way back to early 80's.
The developers that aren't able to write modular code, are just going to write spaghetti network code, with the added complexity of distributed computing.
I agree 99.9% of products do not need a micro service architecture because
1. They will never see scaling to the extent that you need to isolate services
2. They don’t have zero downtime requirements
3. They don’t have enough feature velocity to warrant breaking a monolith
4. They can be maintained by a smaller team
I also agree that the way to build new software is to build a monolith and when it becomes really necessary, introduce new smaller services that take away functionality from the monolith little by little.
Microservices do have a good usecase even for smaller teams in some cases where functionality is independent of existing service. Think of something like LinkedIn front end making calls directly to multiple (micro)services in the backend- one that returns your contacts, one that shows people similar to you, one that shows who viewed your profiles, one that shows job ads etc. none of these is central to the functionality of the site and you don’t want to introduce delay by having one service compute and send all data back to the front end. You don’t want failure in one to cause the page to break etc.
Unfortunately, like many new tech, junior engineers are chasing the shiniest objects and senior engineers fail to guide junior devs or foresee these issues. Part of the problem is that there is so much tech junk out there on medium or the next cool blog platform that anyone can read, learn to regurgitate and sound like an expert that it’s hard to distinguish between junior and senior engineers anymore. So if leaders are not hands on, they might end up making decisions based on whoever sounds like an expert and results will be seen a few years later. But hey, every damn company has the same problem at this point.. so it’s “normal”.
Atleast frontend and backend needs to be decoupled in almost any development for the future. I work with several legacy apps where we use python requests just to collect data. It's a huge pain when https certificate expires, when they change something in validation header and when they deploy a new 'field'. Most CRUD applications do need a place when you can collect all the data after the backend process all the business logic without touching the frontend.
Almost the entire RPA industry revolves around the idea of supporting this legacy apps problem -- scrapping content and not worrying about them breaking.
Microservices were never about code architecture, they were an organisational pattern to enable teams to own different services. Most "microservices" don't actually look micro to those implementing them, because it's really just "a lot of services".
For my personal projects, I just have a frontend service (HTTP server) and a backend service (API server). Anything more is overkill.
I came here to make a similar point. I see two big benefits to microservices, neither of which is spoken to by the article:
1. Using small-ish (I hate the word "micro"), domain-bounded services leads engineers to think more carefully about their boundaries, abstractions, and interfaces than when you're in a monolith. It reduces the temptation to cheat there.
2. Conway's law is real. If you don't think very deliberately about your domain boundaries as you code, then you'll end up with service boundaries that reflect your org structure. This creates a lot of pain when the business needs to grow or pivot. Smaller, domain-bounded services give you more flexibility to evolve your team structure as your business grows and changes, without needing to rewrite the world.
I'm a big fan of the "Monolith First" approach described by Martin Fowler. Start with the monolith while you're small. Carve off pieces into separate services as you grow and need to divide responsibilities.
A multi service architecture works best if you think about each service as a component in a domain-driven or "Clean Architecture" model. Each service should live either in the outer ring where you interface with the outside world or the inner ring where you do business logic. Avoid the temptation to have services that span both. And dependencies should only point inward.
Carving pieces off a monolith is easier if the monolith is built along Clean Architecture lines as well, but in my experience, the full stack frameworks that people reach for when starting out (e.g Rails, Django) don't lead you down a cleanly de-couple-able path.
Agreed. Or as I've heard it said, "microservices solve a people problem, not a technical one". This is certainly how they were pushed at my current workplace -- it was all about "two-pizza teams being able to develop and deploy independently".
Out of interest, what does the "frontend service" do in your setup? For my personal projects I generally just go for a single server/service for simplicity.
My frontend services handles all user requests (HTML templates, i18n, analytics, authentication). Backend is exclusively focused on business logic, interacting with DB, cron jobs, etc... My projects grew into this naturally, and it was monolith first.
People here keep on repeating that statement, yet people actually implementing microservices keep on believing it is a solution for an architectural problem. If they majority keeps on implementing microservices for the wrong reasons then who's right? What you describe is just classic SOA. Then what are "microservices" exactly?
Kind of, and without the API contracts that allowed to make sense out of SOA, many agile-ized APIs end up looking like doing dynamic programming at scale with a network on the middle and plenty of HTTP 500 when things go wrong.
I think that pattern scales really well up to a medium-sized startup.
I stick those two (webserver/static content and API) plus a database in a docker-compose file, and put all three plus a frontend in a single repo. That feels like the sweet spot of "separate but integrated" for my work.
Take away the word micro from micro services. Its just a buzzword. Now you have just services. You can have just one service that handles email, chat, payroll, website - or you can break them up into independent services. Ask yourself: Does it make sense to have two different services to handle x and y. Just don't break something up because of some buzzword mantra.
Maybe the public website is the bottleneck in your monolith, then it might be a good idea to put it on its own server and scaling strategy so that it doesn't bog down the other parts of the system.
Agreed. I was going to add my own separate comment but noticed yours. I think the main issue is, most companies nowadays end up creating "nano" services. A normal "service" should be built and then if functionality/team gets too big, then you break it down into another 2-3 smaller services. Again, service code already should have been written in a clean, modular code style so it can be broken down easily too without rearchitecting whole stack.
But is it really true that so many companies create too small services? I admit I haven’t seen too many architectures from the inside but from my experience the problem is usually the opposite: adding more and more things to a monolith that already has serious complexity and scalability issues because it’s the convenient place and is faster to develop. Most of the times I heard about the nano services problem was from articles warning of using services and encouraging monoliths instead.
It is true for companies that recently trying to adopt this "microservices" catchphrase. Just because it is a trend and somebody sold kubernetes/cf/some-other-cloud-solution to the company, they end up overusing it and creating a new microservice for something that could just be a separate package in already existing microservice. I am definitely not encouraging monolith architecture, they are horrible to work with, but I am also not suggesting 1500+ microservices for a company like Monzo (just considering their lack of functionalities compared to other new banks, 1500+ microservices sound like nanoservices instead to me)
>If your codebase has failed to achieve modularity with tools such as functions and packages, it will not magically succeed by adding network layers and binary boundaries inside it
This is assuming you're converting an existing non-modular monolithic service to micro services. If you're starting from scratch or converting a modular monolithic service then this point is moot. It says nothing about the advantages or disadvantages of maintaining a modular code base with monoliths or microservices which is what people are actually talking about.
The issue generally isn't just creating something clean but rather it's maintaining something clean. Something that will be owned not by you but by multiple teams whose members change over the course of years.
On a side note, I've found that creating something again usually leads to messes as you try to fix all the issues in the original which just creates new issues.
This seems to always be the case when two alternatives are discussed on HN. The new and shiny is muddled with the new design, so it's hard to tease out where the improvement came from, and in most cases, the new design is possible in the old and trusted.
The difference you miss is that the former discourages bad interfaces and the latter does not. There is no "you" in most businesses. There's dozens of people who changes over time. People with deadlines and concerns of their own.
Data API over HTTP spaghetti is surely a bad way to do microservices (some accidental exclusions apply[1]). And if you'd have to do cross-service transaction or jump back and forth through the logs, tracing the event as it hops across myriad of microservices, it means that either your boundaries are wrong or you're doing something architecturally weird. It's probably a distributed monolith, with in-process function invocations replaced with network API calls - something worse than a monolith.
At my current place we have a monolith and trying to get services right by modelling them as a sort of events pipeline. This is what we're using as a foundation, and I believe it addresses a lot of raised pain points: http://docs.eventide-project.org/core-concepts/services/ (full disclosure: I'm not personally affiliated with this project at all, but a coworker of mine is).
___
[1] At one of my previous jobs, I've had success with factoring out all payment-related code into a separate service, unifying various provider APIs. Given that this wasn't a "true" service but a multiplexer/adapter in front of other APIs, it worked fine. Certainly no worse than all the third-party services out there, and I believe they're generally considered okay.
Yes, the more I develop on the Web, the more I find HTTP lacking as a panacea for process communication. It's ubiquitous because Web 1.0 operated at a human-readable level. It was 1 request makes 1 response. Now that we have 1 request makes many server-side requests makes 1 server-side response makes many client-side requests. There does not exist a solution now that solves all of the problems of this many to many communications problem on the web.
Microservices are the actor model (erlang or akka) except they require lots of devops work, being on call for x services every night, and a container management system like kubernetes to be manageable.
Actors are a simple solution to the same problems microservices solve and have existed since the 1970s. Actor implementations address the problem foundationally by making hot deployment, fault tolerance, message passing, and scaling fundamental to both the language and VM. This is the layer at which the problem should be solved but it rules out a lot of languages or tools we are used to.
So, in my opinion, microservices are a symptom of an abusive relationship with languages and tools that don't love us, grow with us or care about what we care about.
But I also think they're pretty much the same thing as EJBs which makes Kubernetes Google JBoss.
> A recent blog post by neobank Monzo explains that they have reached the crazy amount of 1500 microservices (a ratio of ~10 microservices per engineer)
That’s wild. Microservices are mostly beneficial organizationally — a small team can own a service and be able to communicate with the services of other small teams.
If anything I think a 10:1 software engineers:services is probably not far off from the ideal.
> That’s wild. Microservices are mostly beneficial organizationally — a small team can own a service and be able to communicate with the services of other small teams.
And a cross-concern fix that a dev used to be able to apply by himself in a day, now has to go through 5 teams, 5 programming languages, 5 kanban boards and 5 QA runs to reach production. I never understood the appeal of teams "owning" services.
In my dream world, every engineer can and should be allowed to intervene in as many layers/slices of the code as his mental capacity and understanding allows. Artificial - and sometimes bureaucratic - boundaries are hurtful.
To me, it's the result of mid-to-senior software engineers not being ready to let go of their little turfs as the company grows, so they build an organizational wall around their code and call it a service. It has nothing to do with computer science or good engineering. It is pure Conway's law.
In my experience, ownership of services is usually defined to ensure that in the engineering organization it's clear who will react as the first responder when there are security patches, production incidents to deal with and also when there are questions about the service's inner workings. It's especially required when the documentation of the services is sparse which is likely to happen when the change rate in the team is high.
In more mature engineering organizations, you would define a set of maintainers for the service, who will define the contribution mechanisms and guidelines, so that anyone can make changes to the code. This is further enabled by common patterns and service structures, especially when there is a template to follow. Strict assumed "ownership" creates anti-patterns where each team will define their favourite tech stack or set of libraries making it difficult for others to contribute and decreasing the possible leverage effects in the team.
Maybe it is simply a terminology issue, but what you describe, I would call it responsibility rather than ownership. Ownership implies strong exclusivity. Agree with your post otherwise.
I agree that responsibility is what we are actually looking for.
The term 'ownership' is popular in product teams [1] and in engineering career frameworks [2]. In the second example, it's defined as "The rest of that story is about owning increasingly heavy responsibilities". Even github allows defining code ownership through the CODEOWNERS files.
> In my dream world, every engineer can and should be allowed to intervene in as many layers/slices of the code as his mental capacity and understanding allows.
The problem is that a sufficiently-complex system is impossible for a single engineer to comprehend in its entirety, so each engineer will end up only understanding a subset of the overall system. Splitting a monolith into clearly-delineated services - and splitting those engineers into teams developing and maintaining those services - helps make that understanding less of a daunting task.
I agree that engineers should be able to move between these different concerns mostly freely (so long as there are indeed engineers covering all concerns), and should be encouraged to learn about those components which interest them, but that clear delineation and a clear notion of "ownership" of different components expedites the process of figuring out who can fix what (since "everyone can fix everything" is unrealistic for all but the most trivial systems), who to call first when something goes wrong, who should be reviewing PRs for a given component, etc.
> And a cross-concern fix that a dev used to be able to apply by himself in a day, now has to go through 5 teams, 5 programming languages, 5 kanban boards and 5 QA runs to reach production.
If you ever find yourself in that situation, rest assured that something went wrong way before the decision to use microservices was made.
If your systems are that tightly coupled you'll have problems regardless of architecture.
When I hear things like that all I can think is that I have a wildly different idea of what a "service" is that it can be broken down to such a small chunk of functionality.
Are there examples of the size of these individual services? What are they doing?
* two services that accept requests via telephony protocols (SS7, SIP, these are quite small) and forwards the request to:
* the business logic component (large only because of the complexity of the business logic implemented). When there's some state changes, it sends a request to:
* the replication module (say, midsized), which ensures that the state change is replicated at The Other Site to handle geographical redundancy (a requirement from our customer).
* There's one other microservice that the business logic uses and that's to send some data to Apple so they can hand it off to iOS phones (all our stuff internally uses UDP (except for the SS7 stuff)---the addition of a TLS based service was too much to add to the business logic component and this is quite small as well).
All of these modules are owned by the team I'm on, namely due to the esoteric nature of it (the telephony protocols, this is real time since it's part of the call path [1], etc.). Within our team, we can work on any component, but generally speaking, we tend to specialize on a few components (I work with the telephony interfaces and the Apple interface; my fellow office mate deals with the business logic).
If you have ten people working full-time on it, it is not a microservice, it is just a service.
I think the discussion about microservices has suffered more than anyone realises from a lack of shared understanding about what a microservice actually is.
That really depends how you count them and how you manage the entire application landscape. For audit, compliance, security, and risk management purposes you really need to know what the service is doing and what criticality level it is.
Surely, you can make the creation of services really easy - so easy that it's not even viable to define meaningful business names for the services, thus creating an unmaintainable mess. But still, having an application registry or automation that crawls the cloud resources for services can be done afterwards without significantly impacting the speed of creating new services.
While I agree with the notion of treating microservices with caution, I found the article a bit too shallow, barely supporting the claim. Especially the second "fallacy" reads like a draft and it overall ends abruptly.
Microservices have some inherent advantages, mainly that you can manage, modify and deploy one service at a time, without taking down/redeploying the rest of your application(s). This is arguably the big thing that is missing from monoliths. It's hard to only change a single API endpoint in a monolith, but easier to do a change across the entire monolith, when you have to change something about how the whole system works. The best compromise that I've come up with would be to have something that can keep your entire app in one place, but allow individual portions of it to be hot-swapped in the running application, and is built to be run in a distributed, horizontally scalable fashion, In addition, there's a lot to be said for the old way of putting business logic in stored procedures, despite the poor abstraction capabilities of SQL, relative to something like lisp, but with modern distributed databases, we can conceivably run code in stored procedures written in something like Clojure, keeping code close to the database, or rather, data close to the code, allowing hot-swapping, modification, introspection, replay of events, and all other manner of things, all while managing the whole thing like a monolith, with a single application, configuration, etc. to deploy, and a more manageable and obvious attack surface to secure.
(Some of those things like introspection and replay-of-events are in the road map, but the core aspects of hotswapping and modification of code-in-db work.)
That solves part of the problem. If you can turn it on and off with a feature flag, then you probably have some modularity. But for an internal service, or a SaaS offering, or any number of things, where, you have one application that you need to scale, do feature flags really make sense?
EDIT: The above was not fully considered. I think the original article makes a really good point about this:
>Splitting an application into microservices gives finer-grained allocation possibility; but do we actually need that ? I would argue that by having to anticipate the traffic for each microservice specifically, we will face more problem because one part of the app can't compensate for another one. With a single application, any part (let's say user registration) can use all allocated servers if needed ; but now it can only scale to a fixed smaller part of the server fleet. Welcome to the multiple points of failure architecture.
Having a monolith where each feature is deployed separately according to feature flags makes some sense in that you have one codebase, deployed modularly, like microservices, but you still leave yourself open to the "multiple points of failure arhitecture" as the author describes it. In addition, the feature flags idea doesn't really remove the deployment disadvantages of the monolith, unless you're willing to have different parts of your horizontally deployed application on different versions.
For the most part this level of microservice solves the problem of: New engineering leader comes in. New engineering Leader wants to rewrite the entire thing cause "it sucks". Business doesn't have resources to rewrite (for the nth time). New leader and business compromise to create a microservice. Rinse and repeat. Cloud/container/VM tech as really allowed this pattern to work. The art of taking over an existing codebase, keeping it going at low cost, low overhead is gone. Nobody's promo packet is fulled with sustainment work. One microservice per promotion. Etc etc.
This misses some of the main reason Microservices are nice, it’s much easier to change code that isn’t woven throughout a code base. Microservices make the boundary between units defined and forces API design on those boundaries. Yes, you can properly design these abstractions without a service boundary, but having the forcing function makes it required.
I mean, this ain't entirely unreasonable. Considering the database to be its own "service" is perfectly valid, and you can control what things a given client can do through users/roles, constraints, triggers, etc., which you absolutely should be doing anyway.
That is: the database's job ain't just to store the data, but also to control access to it, and ensure the validity of it. A lot of applications seem to only do the first part and rely on the application layer to handle access control and validation, and then the engineers developing these apps wonder why the data's a tangled mess.
For example the deployment aspect:
- monolith single deployable unit.
- microservice multiple independently deployable units.
Multiple teams on a monolith:
- you have to coordinate releases and rolebacks...
- code base grows and dependencies between modules (that have shouldn't have dependencies on each other as well, unless you have a good code review culture.)
- deployment get slower and slower over time.
- db migrations also need to coordinates over multiple teams.
These problems go away when you go microservices.
Of course you get other problems.
My point is, in the discussion microservices vs monolith you need to consider a whole bunch of dimensions to figure our what is the best fit for your org.
Still don't need microservices. What you're referring to is just SOA which has been around for a couple of decades. Microservices typically outnumber engineers or aren't too far off.
> What you're referring to is just SOA which has been around for a couple of decades
“Microservices” is just a new name for SOA that ditches the psychological association SOA had developed with the WS-* series of XML-based standards and associated enterprise bloat.
Start with a monolith for your core business logic. Rely on external services for things outside your value prop, be it persistent storage or email or something else. Keep on building and growing until the monolith is causing teams to regularly step on each other's toes. By that I mean, continue well past teams needing to coordinate or needing dedicated headcount to handle coordination to the point where coordination is impossible. When that point approaches, allow new functionality to be built in microservices and gradually break off pieces of the monolith when necessary.
Microservices aren't a panacea by any means, but like any tool, they provide certain advantages when dealing with certain use-cases.
One thing the article fails to mention are the boat loads of tooling out there to address the failings of, and complement microservices architecture, of which Kubernetes is only one.
Sure they come with their own levels of complexity, but deploying K8 today is orders of magnitude simpler than it was 4 years ago. The same will hold true for similar tooling in the general microservices/container orchestration domain, such as service mesh (it's a lot simpler to get up and running with Istio or Linkerd than it was 18 months ago), distributed tracing (Jaeger/Opentelemetry) and general observability.
I'd also point out that MS can provide benefits outside of just independent scaling and independent deployment of services, but should in theory also allow for faster velocity in adding new services, all dependent on following effective DDD when scaffolding services, they allow different teams in a large org to design, build and own their own service ecosystem with APIs as contracts between their services and upstream/downstream consumers in their own org and new team members coming onboard should in theory be able to get familiar with a tighter/leaner codebase for a microservice as opposed to wading through thousands of lines of a monoliths code to find/understand the parts relevant to their jobs.
In my experience, the benefits of microservices are primarily better delineated responsibilities and narrower scope, and secondary benefits tend to fall out from these. There are downsides, but the "harmful" effects do not reflect my experience. I fully grant more things on a network invite lower availability / higher latency, but I contend that you already need to handle these issues. Microservices do not tend to grossly exacerbate the problem (in my experience anyway).
The other callout is clean APIs over a network can just be clean APIs internally. This is true in theory but hardly in practice from what I've seen. Microservices tend to create boundaries that are more strictly enforced. The code, data and resources are inaccessible except through what is exposed through public APIs. There is real friction to exposing additional data or models from one service and then consuming it in another service, even if both services are owned by the same team (and moreso if a different team is involved). At least in my experience, spaghetti was still primarily the domain of the internal code rather than the service APIs.
There's also a number of benefits as far as non-technical management of microservices. Knowledge transfer is easier since again, the scope is narrower and the service does less. This is a great benefit as people rotate in and out of the team, and also simplifies shifting the service to another team if it becomes clear the service better aligns with another team's responsibilities.
Microservices are middleware. That's they way I treat them anyway. I build them as the glue between the backend and frontend. They handle things like authentication, business logic, data aggregation, caching, persistence, and generally act as an api gateway. I really only ever use microservices to handle crosscutting concerns that are not directly implemented by the backend but have a frontend requirement. The only way that is harmful is if you write bad code. Bad code is always harmful.
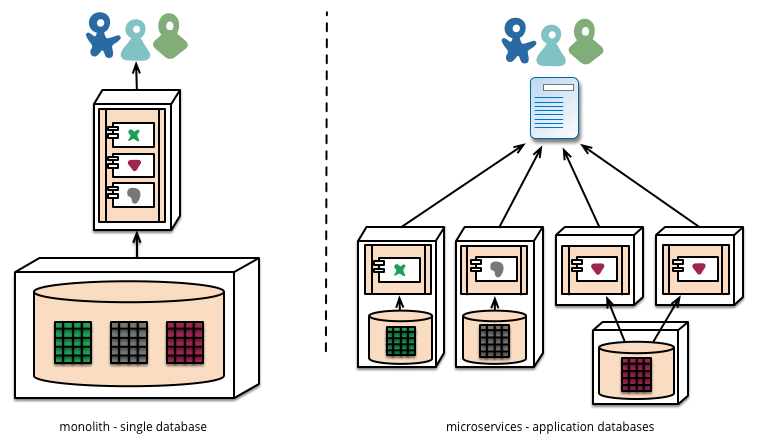
> The central premise of microservices architecture is that the services manage their own data.
No, microservices can handle data from a Bounded Context, that can be its own data, external data, or aggregate data. A Bounded Context is data that is part of a specific Domain that may connect to other Domains that have edges explicitly defined. Therefore the data is decentralized, it can connect to an API that is a monolith, it can interface with messaging services, send notifications over websockets etc because its... a middleware service.
From the article that you linked to debunk me:
> The Guardian website is a good example of an application that was designed and built as a monolith, but has been evolving in a microservice direction. The monolith still is the core of the website, but they prefer to add new features by building microservices that use the monolith's API. This approach is particularly handy for features that are inherently temporary, such as specialized pages to handle a sporting event. Such a part of the website can quickly be put together using rapid development languages, and removed once the event is over. We've seen similar approaches at a financial institution where new services are added for a market opportunity and discarded after a few months or even weeks.
And if I am reading this right, they have a monolith backend, but the frontend doesn't read directly from that it reads from some 'thing' in the middle? Oh what's that called? Its on the tip of my tongue. Ah, right, its called middleware. Because microservices are middleware.
Edit: Oh look that article you linked to debunk me also has the very image I am trying to describe with words:
I see microservices as a people/team architecture. It's a way to scale up people and define boundaries around who is responsible for what, without having to standardize how everyone implements what they are responsible for. Just expose it as a REST API. Problem solved. And problems created. This isn't all bad, it just isn't a "everyone should do this and all your problems will go away" architecture. That architecture doesn't exist.
Seems just a bit too black and white. Surely there can be reasons for splitting up a monolith. Some domains might require very strict boundaries for shared memory and concurrent software on a given system. CE Certified class C medical software comes to mind.
Isolating something to a simple deployment exposed through an RPC API might make it far easier and straight forward to validate and pass requirements.
Micro-services can be used and misused. Good engineering rarely follows these culture-trends. If it makes sense, it makes sense.
I read the explanation and I think the answer is still: it depends. Think about it this way, in your kitchen you dont just have 1 kind of knife. You probably have 2 or 3 different kinds of knives if you're doing basic stuff - and maybe 5 to 10 different knives if you're a top chef.
The same applies to systems architecture. Microservices isn't the only solution or the best solution.
Case in point: I've worked on high-frequency trading systems for much of my career. The early systems, circa 2000-2005, were built on top of pub/sub systems like Tibco RV or 29West - this was effectively microservices before the term was used popularly.
What happened around 2006 was that the latency required to be profitable in high-frequency came down drastically. Strategies that were profitable before needed to run much faster. The result was to move to more monolithic architectures where much of the "tick to trade" process happened in a single thread.
Point is: use the right tool for the job. Sometimes requirements change and the tools needed change as well.
Like almost anything when not used for the correct application. Say a hammer to insert a screw. It is not a good idea. One of my favorite things about using microservice, is that you can use multiple languages. This can grant you the ability to use a language which is better for the task, or for other programmers to contribute in their favorite language.
You can but you shouldn't unless there's a very good reason (ex: there's a very specific interface only available in a language that doesn't conform to the rest of your services) :)
IMO, microservice has two practice levels. Level 1, single codebase with multiple entrances (programs). At this level, the application already scales in horizontal and functional, while still has the benefit of code & data sharing. Level 2, eliminate code & data sharing, use RPC or MQ for communication, split the project into multipile repositories. This level might be regarded as the "ture" microservices which is considered harmful according to the blog post. Generally speak, if level 1 could fit your business, there is no need to go for level 2. If it does need level 2, well, it is the complexity itself which leads to the architecture, there is no shortcut.
A major benefit to microservices (over monoliths) that I haven’t seen mentioned yet is testability. I find it hard, or improbable to achieve a healthy Pyramid of Tests on a large monolith.
For example: a high level, black box test of a service endpoint requires mocking external dependencies like other services, queues, and data stores. With a large monolith, a single process might touch a staggering number of the aforementioned dependencies, whereas something constrained to be smaller in scope (a microservice) will have a manageable number.
I enjoy writing integration and API tests of a microservice. The ones that we manage have amazing coverage, and any refactor on the inside can be made with confidence.
Our monoliths tend to only support unit tests. Automated end-to-end tests exist, but due to the number of dependencies these things rely on, they’re executed in a “live” environment, which makes them hardly deterministic.
Microservices allow for a healthy Pyramid of Tests.
This is absolutely a fallacy. If you're testing a microservice and stubbing the other microservices, you aren't doing the equivalent of the high-level test on the monolith. You're doing something like a macro-unit test of the monolith with internal services stubbed.
I think there's a tendency to believe that a microservice written by someone else can be replaced with a stub that just validates JSON or something.
But in my experience, that thinking leads to bugs where the JSON was correct, but it still triggers an error when you run real business logic on it.
It's an easy trap to fall into because that microservice exists to abstract away that business logic, but you can't just pretend it doesn't exist when it comes to testing.
So stubs may be good for unit tests, but only if there are integration tests to match.
It's also useful if the team providing the service can provide a fake or a stub with interesting pre-programmed scenarios, this reduces the number of false assumptions someone can make, is sort of a living documentation (assuming people update their fakes). Something like contract testing (Pact etc) can also be useful, although I haven't seen it being used in practice yet.
Sounds like the services shouldn't be split up into 10 if there's that much dependency going on.
Like, services are an abstraction. If one service has to call all other 9 services, and the same occurs for the other 9 services -- then that's a monolith acting over the network.
Im yet to see a system that consists of other versions of code than ”new” and “current”. You test against changes only, what you described is some mess in deployed versions / versions management.
Its losing „some” adventages of startup grade microservices and gain maintainability adventages of „netflix/facebook” level grid... Depends whats your scale. Shipping shit fast is often not the best solution at that scale, doing it right is. And I have already explained to someone else in this thread why that approach is important.
This is true for moderately-sized microservices. If your microservices are too small, though, it's essentially impossible to write integration tests of the overall system as a whole--any such test would need to spin up N different dependencies.
> I find it hard, or improbable to achieve a healthy Pyramid of Tests on a large monolith
I'd venture to say that this is a strong indication that You're Holding it Wrong™
> a high level, black box test of a service endpoint
Then maybe don't do these kinds of high-level black box tests?
Because...
> requires mocking external dependencies
...if you're stubbing out everything, then it's not actually a high-level, black-box test. So no use pretending it is and having all these disadvantages.
Instead, use hexagonal architecture to make your code usable and testable without those external connections and only add them to a well-tested core.
In the absence of independency, a service development organization will hit a ceiling and fail to scale beyond that. While there may be a whole host of other problems that microservices does not solve, this single problem makes it worthwhile in many cases.
That all said, implementing microservices well or even scaling beyond the point where microservices become useful requires a great deal of engineering discipline. Concepts like configuration as code and API contracts have to become something more than theoretical.
Teams of ten. Each service is owned by exactly one team.
That rules out every monolith I've seen at companies that still did that.
But unfortunately, Microservices, becomes a religion, a cargo cult, and companies have hundreds of tiny little services.
My services are not monoliths. But are they microservices? Don't care. They work. Certainly they are just a couple of services within a network of several hundred, but I work at a large company. And every one of those services has one team responsible for them.
When people decided to go Microservices route, In my 4 yrs of experience with it, please define couple of things before you go down that route. 1. How to share the database when there is too much of dependency between 2 microservices , think event driven or other mechanism like materilized views. 2. Please give developer more importance in this setup as there is too much of responsitbility being thrown up at devs.
If you don't know how to structure a monolith well (using libraries/modules) then you will 100% fail building well structured micro services. Micro services take the difficulty of building a well-structured monolith and adds even more complexity (networking, protocols, no global ACID, no global priority list, inter-team politics etc. etc.)
I'm unsure what people are building when they say they are building micro services. I don't understand how any company like Uber or monzo end up with 1500 services to maintain.
I mean do they abstract the function of "emailing" out into 50 different micro services. Or 1 micro service?
microservices are useful, but not for the reasons listed here (or the reasons often assumed)
personally, i'm more a fan of "realm of responsibility scoped services" to decouple technologies/datastores of parts of a system that do not interact by design (for instance, your user account / credentials handling from literally anything else), and then use a system like kafka (with producer-owned format) to have a common data bus that can tolerate services that process data asyncronously (or even things that keep users in the typical "refresh loop") dying for a bit.
I think nowadays most developers pretty much collectively point their browser towards linkedin.com the moment they here an architect mutter the phrase 'Service-Oriented Architecture'.
> Network failure (or configuration error) is a reality. The probability of having one part of your software unreachable is infinitely bigger now.
Network partitions are indeed a problem for distributed software in general. By the time microservices are worthwhile, however, the application likely already necessitates a distributed design.
> Remember your nice local debugger with breakpoints and variables? Forget it, you are back to printf-style debugging.
...why? What's stopping you from using a debugger? A microservice v. a monolith should make zero difference here.
At worst, you might have to open up multiple debuggers if you're debugging multiple services. Big whoop.
> SQL transaction ? You have to reimplement it yourself.
...why? What's stopping you from pulling it from a library of such transactions?
I don't even really think this is a "problem" per se. Yeah, might be inconvenient for some long and complicated query, but that's usually a good sign that you should turn that into a stored procedure, or a view, or a service layer (so that other services ain't pinging the database directly), or something else, since it simply means bad "API" design (SQL being the "API" in this context).
> Communication between your services is not handled by the programming language anymore, you have to define and implement your own calling convention
Which is arguably a good thing, since you're able to more readily control that calling convention and tailor it to your specific needs. It also gives ample opportunities for logging that communication, which is a boon for troubleshooting/diagnostics and for intrusion detection.
> Security (which service can call which service) is checked by the programming language (with the private keyword if you use classes as your encapsulation technique for example). This is way harder with microservices: the original Monzo article shows that pretty clearly.
The programming language can do little to nothing about security if all the services are in the same process' memory / address space; nothing stopping a malicious piece of code from completely ignoring language-enforced encapsulation.
Microservices, if anything, help considerably here, since they force at least process-level (if not machine-level) isolation that can't so easily be bypassed. They're obviously not a silver bullet, and there are other measures that should absolutely be taken, but separation of concerns - and enforcing that separation as strictly as possible - is indeed among the most critical of those measures, and microservices happen to more or less bake that separation of concerns into the design.
I wish Dijkstra had named his article on the go to statement[1] something else. It feels like every other author nowadays want to use the sense of authority that the "considered harmful" gives them. Like it's obvious and widely accepted that it's harmful, and they're giving you an FYI.
Just name it "The downsides of microservices" and we'll know that it's your personal opinion. This title might get you more clicks, but it's a turn off for me.
(Actually it was Wirth that came up with the "Considered Harmful" title. Dijkstra sent the paper as "A case against the Goto statement" [1].)
I would go on a limb and say that CH-titles should be themselves considered harmful. [2]
Personally, my main issue with them is that they invite (often unfavourable) comparisons with EJD's paper.
“The original title of the letter, as submitted to CACM, was "A Case Against the Goto Statement", but CACM editor Niklaus Wirth changed the title to "Go To Statement Considered Harmful".”
So, Dijkstra’s choice for a title would be “A Case Against Microservices”.
I never quite understood the objection to "considered harmful." To me the very wording of the phrase is a jest; it's said with tongue firmly planted in cheek, even if what follows is quite serious, and it fully and effectively declares its intention to go poke some sacred cow in the eye. I never read it as overbearing or judgmental. I love it!
Ah, yes, the recursive Considered Harmful. This article was quickly followed up by the rebuke "'Considered Harmful' Considered Harmful" Considered Harmful. Shortly thereafter, the entire blogosphere had a stack overflow error and nearly took the entire internet offline along with it. Recursive Considered Harmful Considered Harmful.
If you have enough karma, you can flag any article which uses "Considered Harmful" in the title. That won't get rid of clickbait in general, but maybe authors will choose a different variety of clickbait.
The author is totally right about the HTTP layer/networking stuff. I don't think you have to re-implement SQL transactions, but you do need a backing store that allows acknowledging a message has been processed and not down-sides to processing the same thing twice (idempotent).
I did a post about microservices as I've seen them, and I see the more as software evolution matching that of our own biological and social evolution:
Like our own immune system, the thousands of moving parts have somehow evolved to fight infections and keep us alive, but it's easy to not be able to understand how any of it really works together.
{kind=link}
This is such a nice quote that speaks a lot about what it means to be an experienced (senior) software engineer. Our field is such a dynamic one! New tools and techniques appear all the time.
It's easy to fall into the trap of thinking that newer tools are better. I think this is because in some areas of tech this is almost always true (e.g. hardware). But in software, new tools are techniques are rarely fully better, instead they just provide a different set of trade offs. Progress doesn't follow a linear pattern, it's more like a jagged line slowly trending upwards.
We think we are experienced because we know how to use new tools, but in reality we are only more experienced when we understand the trade offs and learn when the tools are really useful and when they are not.
A senior engineer knows when not to use micro services, when not to use SQL, when not to use static typing, when not to use React, when not to use Kubernetes, etc.
Junior engineers don't know these trade offs, they end up using sophisticated hammers for their screws. It doesn't mean that those hammers are bad or useless, they were just misused.