In cases like this, the parser and lexer can often produce a better error message if they are written to accept a more lax input and then check it for errors.
For example, instead of faithfully implementing the grammar from the specification, allow numbers with leading zeroes and then produce an error for them.
Another situation where this comes up is parsing language keywords. Instead of writing a separate lexer rule for every keyword, write a single rule for keyword-or-identifier, and then use a hash table lookup inside of that to determine if it is a keyword or identifier.
Usually, if there is a token that is a prefix of another the longer token wins. For example, in Javascript --x is parsed as the decrement operator instead of as two unary "-" operators.
> instead of faithfully implementing the grammar from the specification, allow numbers with leading zeroes and then produce an error for them.
But that's the problem. The tokenizer doesn't talk to the grammar parser (and vice versa)
The tokenizer could understand numbers with leading zeroes and throw an error there.
Something to think about: do languages - not json - interpret -1.2 as [MINUS][NUMBER] or just [NUMBER]. Or how does languages deal with 1.0-2.0 compared to 1.0+-2.0
If you know you are expecting an expression, then it is easy for the parser to understand ‘-‘ as a unary negation if it is the first symbol, otherwise it must be a binary subtraction operator.
Exactly. I was referring to the grammar the tokenizer uses for tokenizing numbers. Instead of faithfully copying the JSON spec, you could use a simpler rule that also accepts leading zeros.
As for the leading "-", in languages that have expressions it is common to parse the "-" as a prefix operator because that covers both negative numbers (-1.0) and negating variables (-x).
But in JSON there are no expressions like 1.0-2.0 so the leading "-" is parsed as part of the number.
> The parser will not complain about leading zeros because JSON has no concept of leading zeros.
Of course there is no logical reason why the parser shouldn't have this concept just because the spec doesn't require. IMO, beyond basic correctness, user friendly error messages are the main differentiator between excellent parsers and crappy parsers.
Browser JSON parsers probably shouldn't be optimized for user friendliness, since to the users running the program any error message is going to be unfriendly. They are optimized for speed, and if nice error messages slow thing down at all, then bare messages it is.
Maybe there's a way to re-parse with a friendly parser with there's an error and dev tools is open.
In a language I worked on ( github.com/skiplang/skip ), at the moment where we throw a syntax error, we can look at the previous few tokens and generate much better error message.
In the case of the above, if last is ], previous is number and before is 0, then put a nice error message where octal notation is not allowed.
This is not “pure” from a language theory sense but in practice if you add a handful of common ones, it makes for a much better experience.
I agree. Often, it's much easier to generate good diagnostic messages by adding failure paths to lexer or parser definitions. i.e. in the 01 case, add a rule for numbers with leading zeroes to the lexer, which generates an error explaining that leading zeroes are prohibited.
When your inputs are from real JSON emitters, it is silly to even have error handling other than rejection.
Helpful error messages for humans writing JSON is a special use case, not "the main differentiator" marking an "excellent [parser]".
Exposing a "helpful" JSON parser to the internet is a bad idea, and probably a waste of electricity, since the error messages will likely go into a black hole. An "excellent" parser might even reject some technically valid forms, for not being regular (indicating a suspicious or malfunctioning client).
> When your inputs are from real JSON emitters, it is silly to even have error handling other than rejection.
I'm guessing from this that a "real JSON emitter" is one that perfectly implements the JSON spec and has absolutely zero bugs? Does such a thing exist?
> Exposing a "helpful" JSON parser to the internet is a bad idea, and probably a waste of electricity, since the error messages will likely go into a black hole.
There's a lot of software where any kind of unexpected error just gets repeated back to the user. I'm sure you've seen a modal popup like:
Unexpected error, please try again
(SyntaxError: JSON.parse: expected ‘,’ or ‘]’ after array element)
This is immensely unhelpful to basically everyone involved. If the message at least hints that it's due to a problem with the input itself -- for example: "SyntaxError: Invalid value ‘01’" -- then it's much more likely that an end-user can figure out which value is causing the problem and work-around it, and report a much more meaningful bug to the developer (thus allowing it to be solved significantly faster).
Taking the argument that "helpful" JSON parse errors are pointless to its logical conclusion, there should only be a single possible error "JSON parsing failed", and I can't see how that's anything but a recipe for making everyone absolutely despise your API/product/etc, especially were your JSON parser ever to have even a single bug that caused that response erroneously.
>I'm guessing from this that a "real JSON emitter" is one that perfectly implements the JSON spec and has absolutely zero bugs? Does such a thing exist?
If the JSON Serializer has a bug then the only option is to fix the bug instead of adding a human that is manually correcting mistakes in the generated JSON output. The only purpose of human friendly errors is because humans are involved and since they aren't we have to unnecessarily add them to make your complaint valid. (Don't tell me you're feeding the human friendly error messages into an ML algorithm. That's just bullshit.) The days of office workers doing pointless busywork of this type are long gone.
I'm not sure why you're saying humans aren't involved. Humans are writing the code (often with bugs), troubleshooting operations, supporting other humans using the software, and identifying and fixing bugs.
While I agree fixing the bug is the only option, it still has to be identified first. A bug that is based on data can appear to happen "randomly" and if the error is a useless one like the OP or even just "invalid JSON" it can take a long time before isolating the exact cause (especially if it's not obvious which piece of software is even the source of the error), and in that time end users, support and ops people lose trust in the system.
If your environment's JSON serializer is fundamentally capable of producing invalid JSON in normal operation, you probably have a lot of other problems to overcome.
Reporting the last valid input and the start of the first invalid location (possibly repeating the first couple characters of invalid content, filtered for safety) is what I'd generally prefer in an error message.
> user friendly error messages are the main differentiator between excellent parsers and crappy parsers
It think parser quality is a matter of correctness, error messages, speed, and resource use. How much each of these are to be prioritized depends on application. I'm entirely with you that most of the time error messages matter a lot and are often worse than they should be.
Probably not for any great reason: worst case scenario is to simply use the fast parser, and when it fails, then go back to the end of the last successfully parsed expression, and run the the slow parser to get a good error.
That is, it's not terribly difficult to deal with the tradeoffs if your description of the problem is at all correct
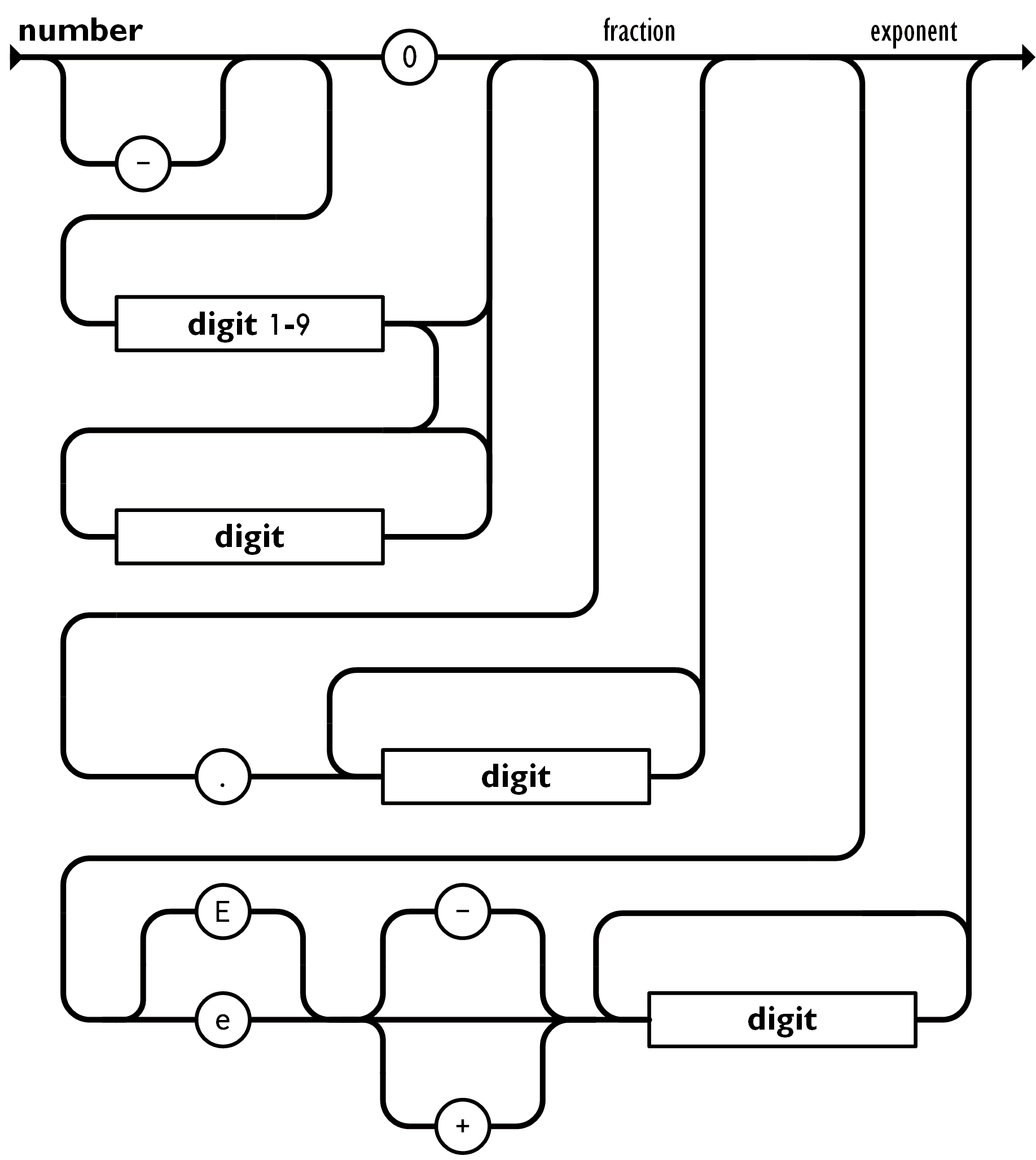
I was initially surprised that all the lexers treat "[01]" as four tokens, but it makes sense from the state diagram.
In the past I've encountered JSON lexing that only considers token boundaries on "special" characters i.e. ",}]:" and whitespace. This will return a lexing error when it sees "01" (equivalently "truefalse").
One could imagine first tokenizing only based on whitespace, then only starting to figure out what the tokens are. Which means parsing them individually. Which means another parsing step.
I think this would match human more closely: structure is more obvious based on visual separation than detailed analysis.
I guess it wasn't done that way because the current way of operation means one parser to rule all sources, and that parser can handle more complicated cases. That kind of design decision is more surprising later, but is kind of understandable when you draft a language as the same time as your first parser.
Octal notation is traditionally used in several contexts - file mode probably being the most common. If you were writing a JSON object to describe a file to be created, and you were under the mistaken impression that JSON supported octal with a leading zero (like most languages), it would be entirely reasonable to write something like:
Error messages are "blaming the user".. its job is to help inform the user the mistake he made.
You can silently beat your child everytime he makes a mistake, until he accidentally does the job correctly (and doesn't get beaten), but it seems to me that making use of our ability to communicate can be much more efficient (and significantly less painful for the child).
And json is merely a (very innefficient, and somewhat problematic) protocol for information exchange; it's not something you should expect people to have read the spec for, especially when its whole popularity stems from it being "intuitive" -- that is, you don't really need to read the spec to deal with it effectively
According to the proposal, this has been shipped in V8 in Chrome 66 (from the V8 bug report: The ECMAScript ⊃ JSON proposal shipped in V8 v6.6 and Chrome 66). And yet my Chrome version 79 does not parse "[01]", throws the same error as described in the article. Same error in Node 12.14.0 (which includes V8 7.7.299.13). Something doesn't add up.
Not sure what's confusing. "[01]" is not valid JSON. JSON being a subset of JavaScript means that all valid JSON constructs are valid JavaScript constructs. So, the subset statement says nothing at all about "[01]"
JSON.parse("(function() { })") doesn't parse either, despite being valid JavaScript. Both constructs are specific to JavaScript, and do not exist in JSON. Hence, JSON is a subset of JavaScript.
The problem with octal formatted numbers, and why JSON (and strict mode JS) explicitly disallow them dates back to the JS engines of the time.
Essentially you have Netscape and IE. Netscape added support for "octal", IE did not, that meant that you had code like `x = 017` that had different values in the two engines. Given the early JSON parsers essentially just called eval() on the string that wasn't ok behavior for a data interchange format.
Then you have the absurd behavior of the Netscape octal implementation, which leads to such wonders as `018-017==3`, which make it a super terrible footgun.
Sensibly modern syntax makes the difference between octal and decimal very explicit with a 0o prefix, just like 0x, 0b, etc. I wish I knew why it was originally decided to not use 0o when 0x was in use.
If you have a file or network stream with millions of separate JSON items, then you might want to parse and process each item separately as it is received, and the surrounding structure just gets in the way. That being said, it's properly better to explicitly acknowledge that you're using something-like-json-but-not-really-json like http://jsonlines.org does instead of simply concatenating json objects.
With the application understanding that the top level object is an array of independently parsable json objects, it should still be possible to stream the format I suggested, assuming you use a streaming / sax parser.
A non-online/non-streaming parser can parse [0][1] in an online/streaming way by first parsing one text ([0]) then the next ([1]), whereas it has to parse all of [[0],[1]] to produce a result. Similarly on the encoding side.
Concatenated JSON is ambiguous, so you need to put some whitespace between any JSON texts where both aren't arrays or objects.
When I was writing something (partly) as a learning exercise the easiest way to handle errors was to have an error handler on the server-side JSON encode any errors. The client-side JS would then split the string it got back on newlines and then parse each part. Each chunk of JSON had a field to say if it were an error message and if so the error would be logged to the browser console. I don't recommend, by any means, that people do this generally.
Its possible the parser was laid out to choke on octals as a way to protect the 'standard'. Its one decision to not support octals, and its another to make octal-style an error so those numbers are not parsed as base10.
You have it all backwards. What a string in any language means is defined by the language specification. If the JSON spec doesn't say that '01' is an octal number, then it's not an octal number. What you would like it to be, or what other language specs say, is completely irrelevant for what that string means in JSON.
Also, making a language X parser accept anything that is not in fact language X is nothing but a terrible idea. If there is one thing that standards are good for, it's interoperability. And if there is one thing that hurts interoperability, it's having different implementations of supposedly the same standard accept and reject different inputs. That's how you get websites that work in one browser, but not another, because one browser was so helpful to make up some meaning for your creative markup instead of rejecting it with an error message, which obviously helps you absolutely nothing with the next browser that is of a different opinion. If you think the spec is stupid, you have to change the spec, if you don't manage to do that, you still should implement the spec, because interoperability is more important than whether your program can read some input that isn't JSON and that therefore no other JSON parser is guaranteed to understand anyway.
It seems honoring this type of technical correctness matters a lot. For example, imagine if ECMA added a new feature (e.g. 0-prefixed octal literals) in 2020..
Another issue: security. Imagine a hacker figured out that you used a mix of JSON parsers on your application (e.g. V8 and jq), and they produced different output.
I believe what you're actually saying is that regardless of whether or not it is technically correct, it would be incorrect (and I agree with you there).
My question was more "for inputs not defined as being valid by the spec, is the result undefined (a la C++ UB where anything and everything is legal in response) or is it required to reject said input".
The sibling response says extensions are allowed, but that wouldn't come into play if an input is specifically called out as disallowed (vs simply not taken into account whatsoever).
RFC8259 allows arbitrary extensions, so as long as it doesn't cause any misparses of regular JSON it would be acceptable, at least up to that standard.
EDIT: Also, yes, I the mistake with my initial example -- as '8' doesn't exist in octal, we have no choice but to interpret the leading '0' as padding and '08' as base ten, whereas '11' can be interpreted as base eight.
IMHO if it's not going to support octal anyway, it makes zero(!) sense to artificially limit/special-case things like this, because then it's much simpler and more consistent to have leading zeros behave like any other digit.
JSON was made to be "based on a subset" of Javascript. The only way to be compatible with JS while removing octals is to disallow leading zeroes entirely. Doing otherwise would lead to JSON and JS behaving differently with the same input.
Of course, until recently JSON wasn't a strict subset of JS but that was an oversight rather than by design.
Not only that, but rejecting leading zeroes allows parsers to add octal support themselves by accepting the leading zero, just as how some JSON parsers extend JSON by allowing comments, or trailing commas, or NaN/+Inf/-Inf.
If you ever want to count in base-8 (or a subset), or have an abbreviated form of binary, or pack decimal in a way that's easier to reason, or divide a number in half (down to 1) without getting fractions, or represent file permissions (a grouping of four octals).
Is JS a modern language? It was made 24 years ago as a prototype for a scripting language loosely mimicing Java. Presumably octals would have been still used often on recent machines.
I think JSON would be vastly improved if it were to just allow comments. Maintaining configuration in JSON is unnecessarily painful due to this pointless feature gap.
The reason JSON can't support comments the way XML does, is that comments aren't part of the JavaScript "DOM". They disappear when you parse them, so they can't round-trip, and there's now way to stringify comments back out.
Standard XML parsers and XML/HTML DOM APIs give you all the comments and whitespace, and it's up to you to ignore them if you don't care, and they're not lost when you parse and re-serialize. Comments and whitespace are part of the standard DOM/SAX API, but you can't just nail those onto another model like JavaScript polymorphic objects/arrays after the fact.
Because parsed JavaScript objects and JSON structures provide no way to access the comments the parser threw away.
Although of course you could implement a parser that saved the comments, but it would need to support another more complex API than directly accessing JSON objects, which could somehow describe where each comment was in relation to the parsed object (since multiple comments can appear anywhere), and what kind of comment it was (// or /* */), as well as where all the whitespace the parser ignored was. (Although XML parsers typically don't tell you about whitespace inside of tags, so that can't round-trip.)
That is theoretically feasible with a JSON API implemented from the ground up in any language, like JSON.Net for example. But it's not practical in JavaScript itself (or Python or any language that parses JSON into pre-existing polymorphic arrays and objects), because you parse JSON into actual JavaScript (or Python) objects, whose API and implementation isn't under your control. So JSON being able to round-trip with any language other than JavaScript (and Python) itself would have been silly.
JSON would not be as powerful and useful a format if parsing then serializing JSON lost information. JSON was meant to be a round-trippable format, so there was no other choice but to leave out comments.
But maybe there's a use case for a "lossy" compressed JSON format like JPEGSON. ;)
If you're maintaining a configuration file in JSON format, you're using the wrong tool for the job. I know a certain popular package manager does exactly this, but popular doesn't necessarily mean well designed.
{kind=link}
For example, instead of faithfully implementing the grammar from the specification, allow numbers with leading zeroes and then produce an error for them.
Another situation where this comes up is parsing language keywords. Instead of writing a separate lexer rule for every keyword, write a single rule for keyword-or-identifier, and then use a hash table lookup inside of that to determine if it is a keyword or identifier.