Not to be confused with mTCP, a TCP/IP library for DOS focused on low memory footprint and efficiency so that it's usable on IBM XT class machines. Includes a bunch of applications like IRC HTTP FTP clients and servers.
Interesting. However, Last modified: 2014. There has happened a lot in the Linux Kernel since then. I wonder what the state of the art is nowadays and how it compares to the Kernel.
The kernel is still quite slow at handling TCP/IP packets. Its the bane of my existence with KeyDB. I'm still experimenting with io_uring which should help a little bit but that was only released this year.
I'm not claiming it is fast. I'm claiming there is a lot of water under the bridge and development done, both for the kernel and probably also for custom TCP stacks. Hence my call for a more up to date comparison.
That said, indeed, io_uring seems like quite great progress.
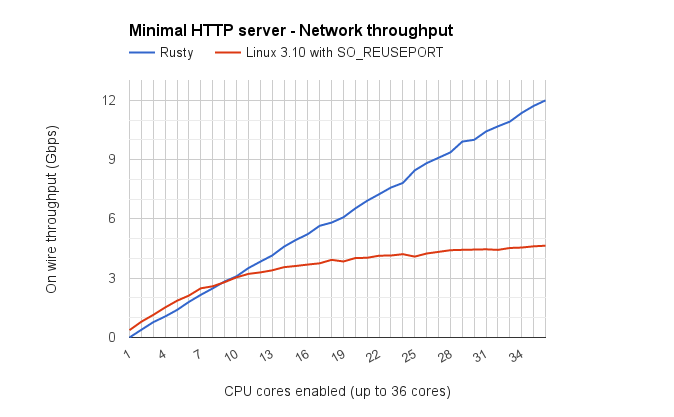
I worked on such a TCP stack while doing my MSc. thesis a couple of years ago [1].
Handling TCP in the kernel has some overhead due to system calls.
Also, the way sockets are designed does not make them very scalable, as you have lock contention on the TCP state machine. The SO_REUSEPORT feature introduced in Linux 3.9 solve some of these lock issues, but the kernel TCP stack is still not fully parallel [2].
> But the kernel TCP stack is still not fully parallel
Yes, and this project, if moved into kernel-space, would entirely replace that stack and its state-machine.
> system calls
You’ve still got the overhead (context switches and memory copies) of getting the IP packet out of/into the kernel, which I don’t think is all that much less than the overhead of getting a TCP packet out of/into the kernel.
Really, what you want is SR-IOV to allow the user-space process to do direct Ethernet DMA to its own dedicated network card. No copies at all!
But if you’re willing to do that, then the application is basically acting as its own kernel... so why not just admit that, and instead of writing a user-space process that has half the features of a kernel, just either 1. write your logic as a Linux kernel driver, or 2. compile your program into a unikernel framework? Then your VM-nee-application’s host can be a proper VMM like Xen or ESXi, where it’s easier to configure that SR-IOV dedication as part of your VM-nee-application’s workload configuration.
For this reason, I’ve never understood people trying to do things like this “in user-space.” You’re playing at being a kernel—with all of the problems of being a kernel—without the ability to rely on an existing, well-written kernel as a basis for your logic (like e.g. the parts that handle the L1-L3 layers of the network stack, which you aren’t changing much.)
> But if you’re willing to do that, then the application is basically acting as its own kernel... so why not just admit that, and instead of writing a user-space process that has half the features of a kernel, just either 1. write your logic as a Linux kernel driver, or 2. compile your program into a unikernel framework?
Because the kernel is still a lot of other things for you other than networking - I think it's a stretch to say that all user-space networking makes your work "half" of that of a kernel. And, you're not necessarily the one doing it. You may be an application, and your user-level TCP (including kernel bypass) may be a library from someone else. But to your general point of now you are now well past the city walls, and may run into trouble, I agree. I assume that this sort of thing is only done by a small number of people.
It does raise the question about if it would be possible by the kernel to implement features that so to say erect city walls in a way that processes can't access whatever it want. Ie, granting access to some of the ethernet DMA but not all of it, or something similar. Perhaps it isn't possible in theory, but perhaps it is, or could be.
> the kernel TCP stack is still not fully parallel
Every mainstream OS today predates mainstream SMP. While support is built into each, it's just ... support. They just were not made in the world where every system is SMP. To see how big a design difference that makes, well, look at Erlang or Go.
Technically DragonFlyBSD was the evolution of a non-SMP kernel, though indeed they've reorganized enough that it more than qualifies as "engineered for SMP."
I think the Haiku kernel was also? At any rate it certainly is now, in much the way DragonFlyBSD's was if nothing else.
You're starting to make me think most of what I read about BeOS isn't true. One of those things was that it was designed for strong, concurrency support. They bragged about it in the demo showing how it didn't degrade under massive load. Another paper mentioned the "benaphores" that improved on semaphores a bit.
So, was it not designed for concurrency and they just somehow fixed a lot of it later? That retrofits usually don't work is why I believed claims that concurrency was a design goal.
Concurrency and SMP are two very different things. One can have a kernel that handles concurrency better than anything else alive but it does not have any support for SMP.
But ... I didn't say anything about BeOS in my comment? I was talking about Haiku, which has very different origins than BeOS, especially on the kernel front where the internal architecture was and is pretty different from the Be kernel.
I actually don't know how much the Be kernel was designed for SMP from the first days; I think it was but I'm not sure. At any rate it definitely did have better concurrency for desktop usage than anything else at the time, I believe.
Probably because it's more experimental and less mature than the others. It's a small operation. However, they got a lot of innovation in concurrency and recently filesystems.
If you align the interface's packet hashing with kernel and application space cpu pining, most of the tcp locking is limited to a single cpu, so there's no cross cpu contention.
Microsoft calls this receive side scaling, and it's also available in FreeBSD. On FreeBSD, this really helps with tcp data packets, but connection setup still has bottlenecks; there's not an api for setting up outgoing sockets to align with the cpu you're on, but it's possible to do it with manual port assignment on outgoing connections.
You’re being downvoted, probably because many people reading this thread already know that kernel <> userland context switching is very expensive, but I think it’s a valid question: there was once a time I also asked this question, and I was happy to learn the answer.
Possibly (I am not a kernel dev) to avoid the memory copy. There are user space network implementations like netmap and dpdk which do this. Possibly this could be optimised in the kernel, I'm not au fait with it enough to be able to say.
To do that properly, you'll have to interface with the network device directly through userspace. Whilst this is certainly possible, you end up with implementing a device driver in the end which might or might not be what you want to do.
Which is exactly what Mellanox and others are doing. At QuasarDB, we’re using their drivers to bypass the kernel entirely, which (at scale) saves tremendous amounts of CPU load.
The implication of what mTCP is doing: Only threads on the same CPU core can communicate at the highest speeds. Isn't this situation broken? Shouldn't we have better hardware support for communicating threads? Why in modern software, are threads communicating through CPU cache invalidation?
Why broken? If they're on the same core then they share the L1/L2 cache which is as fast as it can get.
Why can't I have fast, low instruction cost communication between any two CPUs, regardless of which core it's on? In other words, why do I have to do that bookkeeping to have super fast communication between threads/actors?
Peeps who do chips aren't stupid. It's probably laws of physics rather than incompetence that stopping it, and if it isn't that then it's economics.
The RISC revolution was in part due to "peeps who do chips" getting stuck in their ways, succumbing to CISC group-think, and forgetting to "play Moneyball" with price/performance. I don't think communication between threads was so much an issue in the past.
But if it works, well, cache line snooping is, I guess, exceedingly fast so why not.
Is it really worth sacrificing an entire cache line to do it? Are there other communication mechanisms which could achieve the same or higher speeds with a smaller component count? I don't see how it would violate the laws of physics if the answers were no and yes.
Why do you need faster communication mechanisms? Unless you're "burning" an entire core via busy waiting which costs some performance you will never reach the latency limits of the cache. Your bottleneck will not the communication mechanism, rather the bottleneck will be that the receiver isn't processing the messages fast enough. If your problem is really that time critical then using a CPU was a huge mistake in the first place. What you want is an FPGA.
> Why can't I have fast, low instruction cost communication between any two CPUs, regardless of which core it's on?
Fizzics, specifically a mixture of C and some electrical crap about signal propagation which I don't unnerstand. Einstein, he say no.
> The RISC revolution was in part
true I suppose. Even dumber things were reputed to have been done in the design of the SPARC chips.
> Is it really worth sacrificing an entire cache line to do it?
First show me where this is mentioned in the doc. Second, yeah, why not. If you can pass 512 bits of info between threads in a few cycles, sounds ok to me. If you want another mechanism, be prepared to pay for it. Memory has been around for ages, it's well understood, and bloody fast. It'd be stupid not to use it.
Look, you can't just have stuff cos you want it. You've given no reason for needing it, or that you understand the tradeoffs at the hardware level, or any appreciation of the blinding speed of current chips. How would faster XYZ improve your life?
> Why can't I have fast, low instruction cost communication between any two CPUs, regardless of which core it's on? In other words, why do I have to do that bookkeeping to have super fast communication between threads/actors?
L1 cache is literally inside of the core of modern chips. You can't beat its speed because its physically the closest speed possible.
Moving cache further away (ex: L2 or L3) means more wires, more capacitance, and slower electricity. Electricity doesn't move instantly: it has to fight the capacitance of wires. The wider the wires, the more electrons you need to put onto the wire before its voltage changes. There's also inductance: the longer the wire is, the longer you need to hold a voltage before electrons actually decide to move.
Second: L1 caches do a LOT of book-keeping for you. All cores on modern systems (anything more modern than DEC Alpha from the 90s) will have cache coherence automatically.
That's downright huge, and modern multithreaded programming would be damn near impossible without the ordering guarantees of basic cache coherence. (yes: even ARM / MIPS and their "relaxed memory model" are more coherent than chips from earlier eras).
So first of all, be gracious about the level of memory ordering available to the modern programmer.
------------
So how are caches coherent? Most modern caches use some form of MESI to communicate with each other (invisibly: this is "below" assembly language and is happening at the hardware level).
When one cache claims "exclusive access" to the data, no other cache will write to it (although they may read stale versions of that data from their own cache). When that core / L1 cache is done, it will "invalidate" the data.
Modern cache coherence protocols can go faster: MESIF for Intel means that writes may be (F)orwarded to other caches automatically (which is slightly faster than (E)xclusive -> (I)nvalid -> (E)xclusive in the 2nd core).
Again, this is all done automatically, because programmers want to have their data look the same from all cores (for some definition of "looks the same").
This does NOT mean that the data is in the correct order however (!!). L1 caches can change the order of reads and writes before the data is shipped to other cores. Indeed, this is the very POINT of L1 cache. If one core is doing a while(true) iter++; loop, its more efficient to merge the writes together and "batch" them out slowly. Ex: Core#2 may see "1, 10, 33, 600" each time it reads the value of "iter".
Indeed, the most efficient implementation of this while(true) iter++; loop is to have "iter" be a register private to a core that has absolutely no communication to the outside world at all.
Again, this is all done automatically, because programmers want to have their data look the same from all cores (for some definition of "looks the same").
In terms of bookkeeping examples, we have to make sure we're not inadvertently causing False Sharing.
This sort of thing is quite implicit as opposed to being explicit. This is because communicating with a caching+coherence mechanism is a bit of a kludge.
When one cache claims "exclusive access" to the data, no other cache will write to it (although they may read stale versions of that data from their own cache).
Get your head out of CPU caches and low level stuff for a moment. Imagine that someone proposes a high level communications protocol to you which acts like this. That would be ugly. That's the sort of mechanism you'd expect to see at a very low level of the networking stack. That's precisely the sort of thing a programmer wants abstracted away from them, so they can think of communication as communication, not as a series of details about the behavior of hardware.
> This is because communicating with a caching+coherence mechanism is a bit of a kludge.
Hmm. Right.
> Imagine that someone proposes a high level communications protocol to you which acts like this
It is very clearly not a gleaming tower of high-level abstraction but a hillock of filth with a little goblin upon it that actually scampers about doing the work. It sacrifices beauty so it can run fucking fast. Reality is gross, get used to it.
> Get your head out of CPU caches and low level stuff for a moment
I suggest you go and look at dragontamer's previous posts before you make rather insulting comments like that - he knows more about this area than you or I put together ever will. I read his & BeeOnRope's stuff (<https://news.ycombinator.com/threads?id=BeeOnRope>), you should too.
It sacrifices beauty so it can run fucking fast. Reality is gross, get used to it.
Again, it sounds as if you're trolling. Also, pretty much the same hardware that supports cache coherency would also support conceptually cleaner models for communication. A special register one CPU could write to, and the rest could read from, for example. (async propagation, of course) Using a cache line to for this purpose means that the entire cache line can't be used for other purposes, or at the programmer's peril.
before you make rather insulting comments like that
Not at all meant as a insult. Changing levels of abstraction is very useful, often powerful, and no one is above a reminder to do so.
Also, I've been reviewing your comments. They're somewhat quick to talk down and jump quickly to high handed conclusions about where other commenters are coming from
Fizzics, specifically a mixture of C and some electrical crap about signal propagation which I don't unnerstand. Einstein, he say no.
Please review the thread and try to find the understood references to Hennesy & Patterson which precede your linking to it. While you're at it, please substantiate where any mechanism I've suggested violates the rules of physics, C, relativity, or electromagnetism.
> A special register one CPU could write to, and the rest could read from, for example
Finally, an actual suggestion! OK, how are you going to mediate the thread access so one 'owns' it exculsively for writing while others can rad it? And when will the other threads know when there is something to read? And how wide is this register - 64 bits? And how much overhead will there be for this negotiation between threads? Something like:
x this register is mine for writing, all acknowledge please
x each thread acknowledges (taking various times as each thread lives on different cores/sockets so limited to the speed of the slowest)
x writer thread writes to register
x writer thread releases lock and signals one or more reader threads
x reader threads read and acknowledge lock so another writer can claim the lock
Quite an overhead. Now do that multiple times and it gets slow because it's only 64 bits, which is a lot of overhead for each chunk of data.
Compare that with multiple independent cache lines of 512 bits which can be filled and read independently, then passed around using existing, highly tuned and extremely fast cache coherence protocols that already exist.
> Changing levels of abstraction is very useful, often powerful, and no one is above a reminder to do so.
AFAICS you didn't specify anything until this post. How can we evaluate a claim of 'there has to be something better' until you give it?
> Please review the thread and try to find the understood references to Hennesy & Patterson which precede your linking to it.
Can't see any.
> While you're at it, please substantiate where any mechanism I've suggested violates the rules of physics, C, relativity, or electromagnetism
I was responding to this details-free request: "Shouldn't we have better hardware support for communicating threads?" Better has cost. You just seem unaware of the tradeoffs.
> Also, I've been reviewing your comments. They're somewhat quick to talk down and jump quickly to high handed conclusions about where other commenters are coming from
Yeah, not one of my finer features :( but if someone suggests something solid I'll talk, if someone is willing to learn I'll try to help, and if I'm wrong I'll admit it straight away.
This is evidence that either you're not familiar enough with these issues, so you need to have some things spelled out for you, or you have a rather narrow view of how things should be done at the level of machine language. Funny, because the entire discussion has been about hardware that doesn't commonly exist.
OK, how are you going to mediate the thread access so one 'owns' it exculsively for writing while others can rad it? And when will the other threads know when there is something to read? And how wide is this register - 64 bits? And how much overhead will there be for this negotiation between threads?
Absolutely none of that is necessary for pub/sub semantics between actors. (Either in the form of a register or a scratchpad.) Interesting that you jumped to those several unnecessary conclusions, then ran with it. Left as an exercise. (Hint, it's trivial to show you can't do it with just one instance. However, you can make do with just one tool.)
AFAICS you didn't specify anything until this post.
Sorry, but that has nothing to do with your consistently inappropriate tone, your lack of substantiation on my other points, and your Dunning-Kruger penchant for running off without understanding where the other commenters are coming from. I long for the USENET days when I had a 'killfile' for this stuff. Have a good day. I think I've exhausted the entertainment potential from this one.
'Scusi, I said "they [each core] share the L1/L2 cache". Badly put but I thought on x86 each core had strictly private L1/L2, and L3 was shared across the socket. Am I wrong in thinking L2 is private to each core?
I think L1 / L2 is private per core, but I'm not 100% sure. I "retreated" by stating L1 cache, because I'm 100% sure that l1 cache is private per core.
I know L3 is external to the core, and L1 is private. L2 is that iffy spot in my memory that I'd have to read a few manuals to remember exactly where it is... lol.
Not the parent, but yes on modern x86 L1/L2 is private. The key difference though is that the L1 is smaller and actually a physical part of the core, whereas the L2 is bigger and sits next to the core (read: further away from the execution engine).
Moving to e.g. shared scratchpad memory would be a major paradigm shift, you'd have to do a lot of coordination between CPU vendors, OS/kernel developers, high-performance library writeslrs, etc to make it happen.
> Moving to e.g. shared scratchpad memory would be a major paradigm shift
Shared scratchpad memory is (slowly) happening in the GPGPU world, at least in very limited circumstances.
But yeah, I think that's why GPGPU programmers are managing to get better scaling than classical CPUs, because GPGPUs are more willing to toy with the memory model, and GPGPU programmers are willing to use those highly-specialized communication features.
I don't know much about GPGPU-land, but all of the difficulties I foresee have to do with multiprocessing/sharing/context switching... my guess is that only one logical program can use the scratchpad at a time?
> I don't know much about GPGPU-land, but all of the difficulties I foresee have to do with multiprocessing/sharing/context switching... my guess is that only one logical program can use the scratchpad at a time?
Well.. that one logical program can have 1024 SIMD-threads (maybe 16x (AMD) or 32x (NVidia) "actual" threads... where an "actual thread" is a "ticking program counter" by my definition), but yeah, its "one logical program" from the perspective of the GPU.
Even more specific than "one logical program", but "one threadgroup". So if you have a program that spins up 4096 SIMD-threads, only 1024 of them at a time can actually share a particular Shared Memory. (The GPU will allocate say, 10kB to the different "thread groups", but Threadgroup 0-1023 can touch its own 10kB block, while Threadgroup 1024-2047 can only touch another 10kB block)
GPU Shared Memory can be "split" to different programs. So one program can reserve 10kB, while a 2nd program can reserve 20kB, and then both can run on one GPU-unit. But the two programs are unable to touch each other's shared memory.
all of the difficulties I foresee have to do with multiprocessing/sharing/context switching...
I'd like to be able to park a high performance actor on a particular CPU, and have it consuming its "inbox" queue, no context switches necessary.
my guess is that only one logical program can use the scratchpad at a time?
How about registers or a scratchpad which has async pub/sub semantics? One CPU can write, and the rest can read? A mechanism like that would use the same hardware which already supports cache coherency, but would let programmers forget about a lot of potential headaches.
As I recalled, you wrote channel instructions, or chains of channel instructions, as "CCW"s (Channel Command Words), which you dispatched to the channels via a "SIO" or "SIOF" instruction (Start I/O, or Start I/O Fast).
Once the operation started, the SIO(F) returned to you and the channel operated asynchronously from the CPU, moving the data directly in or out of memory. I think SIOF returned as soon as the channel received the instruction, whereas SIO waited for the instruction actually began.
So the channel actually added as sort of co-processor with the same access to memory as other CPUS. I'm pretty sure the channel could use virtual addresses, but the memory of course had to be fixed (pagefixed) during the operation.
> How about another set of registers, which can be written by one CPU, and read by the others?
The L3 cache is doing something similar. Whatever you come up with has to cope with each core implementing out-of-order execution, so it can't be both trivially simple and ultra-fast.
The L2 and L1 caches are more local to the particular core, and so are faster. More generally, it seems to me unlikely that it would ever make sense to trade off against per-core performance.
> I suppose some of this could be accomplished by compilers on current hardware, if they had information about CPU cores being targeted.
Are we talking about a new software abstraction, or a performance-enhancement on existing hardware? The latter seems unlikely to me - the parallelism folks would've thought of it.
{kind=link}
https://brutman.com/mTCP/