Tech, to Business:
So, hear me out guys. With the power of "The Cloud", we can break our compute workload down to the function level, and have them run as a service for us, rather than say an entire VM, or even an entire container.
And because it's a "Cloud" service, we pay for what we use, so if there's no workload for the functions to service, there's no cost. We just pay for the time the tiny little container is active.
Business:
Ok, that sounds like it can save us money, and you seem confident in the technology, let's go with that.
1 Month Later:
Business: Why do all these actions take so much longer to complete? They used to load instantly with a "Done" message, now they're measurably delayed to respond.
Tech: Well, you see the containers that run our functions stop running once they've finished their work and it looks like theres nothing more for them to do, so when new work comes in theres a delay while the container starts.
Business: You mean like how my Dell takes 5 minutes to boot up?
Tech: Well, kind of, but its much quicker than that obviously, and it's not a whole operating system, it's just some processes in a process namespace...
Business: <visibly zoning out>
Tech: Ok, well tell you what we can solve this, we can setup something to periodically ping the system so the containers running our functions don't ever get de-activated, and that way they'll be ready to service requests immediately, all the time.
Business: OK great that sounds like what we want.
1 Month Later:
Finance: Why did our bill for "functions" suddenly spike in the last month, compared to when we started using it?
Tech: Well you see now we have to keep the function containers running 24x7 so they're quick to respond, because $Business complained they're too slow to start up from inactive state.
Tech Onlookers: ..... <blink>.... Wat... Why... Why would you do that?
(Edited to add:)
Tech Entrepreneur: I can outsource that process of keeping your function containers active for you, for just $1/container/month!
There's also a parallel universe where Tech Entrepreneur#2 sits in darkness for a few months while building a competing product with Rails or another comparable stack and gets everything up and running 10x faster on a single server and it ends up costing less per month.
Yes. It is pretty much useless for web servers as even the scale out from 1 vm container to 2 will require a cold start. In hindsight, this is kind of obvious as you don't expect them to keep a bunch of containers loaded with your dependencies ready to serve requests. They might offer something like that eventually, but at that point your setup is basically the same as ec2 servers loaded with your service in autoscaling groups so why not just use that?
> you don't expect them to keep a bunch of containers loaded with your dependencies ready to serve requests
I think you would expect them to at least use swap for density and always keep one extra instance running and ready to serve requests. It's not like people generate functions on the fly, so it shouldn't even cost anything extra. Swap will help with unnecessary things kept in memory.
1: I've created a lot of experement functions that I hardly ever use and have ones that are no longer used so that would be expensive.
2. The last company I worked for isolated functions to vms on a customer level. That way, if someone hacked their way past the function container, they would then still have to hack their way past the VM container to access another customers data which is what you would have to do anyways on the public VM offering.
That's all plausible except the price issue. Say, you keep 10 containers alive, so you make 10x 100ms calls every 5 minutes. That's gonna be $0.20 per month. 20 cents.
Internal math at my org says that lambdas cost about 20% more than an equivalent amount of EC2 power at full utilization. Now hitting full utilization is very hard, but the point is that lambas are only cheaper compared to underutilized EC2 hosts.
That's ultimately the misuse 9f the technology though right. Unless it's a freak, business changing, spike in usage due to exposure or whatever that lambda are not critical path suitable and don't seem to have been implemented with that intent.
For example if your sign up process is lambda you did you got your cost benefit analysis wrong on anything other than a prototype or mvp, but if your 'change your profile photo', something that maybe happens a handful of times across a month on average per user at best, and you implemented that as your lambda to reduce load and delay scaling needs on your core infrastructure then that feels like you did it right.
Any many people (like me), think Kubernetes is a better way to increase utilization compared to Lambdas. Especially with things like autoscaling, you can keep a kubernetes cluster pretty highly utilized, and no cold startup dance.
If you don't scale up at 80% usage you either have extremely non-volatile workloads (in which case, yes, of course, use EC2s), or you're doing it wrong.
I'm still a bit puzzled by the hype around FaaS. It seems like a useful tool for things where you don't want major queuing under pressure, but you can tolerate human perceptible delays. But it also seems easy to build a big ball of mud deeply tied to the nuances of the chosen FaaS provider. It just seems like most use cases are probably going to be just fine with more conventional horizontal scaling techniques.
But I think I missing something, so I'd love to hear from someone who can paint this picture for me.
I'm pretty new to it but so far I think the big selling points in a corporate environment are:
1. (Maybe, someday) no real Ops work.
2. 100% utilization (at a cost).
3. Measurability of cost in #2.
I agree about the ball-of-locked-in-mud danger. And so far I've seen the Ops part be actually a bigger issue than it was before, because there's so much opaque, badly documented madness involved. With AWS Lambda + API Gateway anyhow, I can't speak to the others.
Even so, it seems like long-term the Ops end of the puzzle can be planned/automated away for the most part. That leaves utilization and billing.
It can be very very useful to say "This costs exactly $X and that cost scales linearly" when planning resource allocations. Even if everyone agrees it could probably be done for an unknowable amount less. The predictability and the isolation of the cost is sometimes worth spending more money. (Of course the predictability requires that the Ops Ninjas not be required, which again I think is possible long-term but definitely not short-term.)
Anyway that's just for one realm of application, which I think is getting more popular ("do this internal thing we used to have some EC2's do").
The no-ops part is compelling, but we've already had that for years in the form of PaaS for small teams and K8s for large ones.
I think the billing part sounds a bit like a trap to me. At least while FaaS retains so many quirks, it's like trading billing for the engineering time of contorting a business process to a given FaaS model (e.g. trying to eek out the lowest average and worst case latency; also working within language runtime limitations).
I'm pretty sure ops will never be automated away; it can only be transmuted to a different form :). But, at best, you can achieve elegant separation of ops and process concerns. That's where I worry FaaS could be a bit of a hazard, if not carefully utilized.
> ops will never be automated away; it can only be transmuted to a different form
Precisely, and the promise of FaaS is that it can become a black box you don't care anything about, and bundled into the markup you're paying on CPU, memory and network.
So far in real life it looks more like Ops is very much involved whenever you update a function or -- gods help you -- actually have to debug something in production. As long as this is the case it's a broken model, because as soon as you pull your Ops Ninja away from some other task you're right back in the bad old world of unpredictable costs.
My sense (as a relative newbie) is that the providers know this and are slowly trying to make stuff easier and more flexible -- and more predictable -- to deploy. Amazon Elastic Container Service being one example.
The catch is that the more standard it is, the less lock-in there is, and so far my experience with AWS suggests that lock-in is a major part of their strategy.
This made me smile because I too have been puzzled by the hype around serverless. I'm sure it does have its uses but it wouldn't provide an acceptable solution for any of the problems we currently need to solve. Not saying that won't change but I do find it vaguely irritating that serverless has at times been presented to me as an end to all woes when that clearly is not the case.
Having just spent sometime actually learning "serverless" between lambda and GCP I am presently baffled as to how this isn't weirdly hard to use docker containers.
To your point, it seems like AWS ECS really is the best of both. You get the no-infrastructure benefits of Lambda with the flexibility/control of a docker container.
You keep the ability to exercise a fair amount of control, easily, and clearly.
And you don't sit inside really opaque execution environment.
Sure, the scaling and provisioning of those Docker containers is opaque, but I'm much more willing to deal with it at that level.
I'm guessing you're thinking of their Fargate option. ECS itself is not terribly opaque (at least to my eyes). Fargate's biggest downside is its own cold start times - unlike Lambda, there's no caching to give you warm starts on jobs.
The flip side - so long as its a service and not a job, who cares? :D
> But it also seems easy to build a big ball of mud deeply tied to the nuances of the chosen FaaS provider.
I guess you can. However, when I built Lambda functions I did pay attention to restricting lock-in to the entrypoint, and when I later had to migrate elsewhere for non-technical reasons, that was very much doable. In other words, it's easy but not necessary to build a big ball of locked-in mud.
I have yet to experiment with it but I think the best use-case is cron-type functions. Imagine all the little robots you could build to automate your business. And you get monitoring unlike cron.
That sounds like spaghetti to me. And I also understand the total run time of each function call to be limited, typically. So that means no long overnight jobs, which is a big cron/Jenkins use case.
I'm using AWS Lambdas for a project. Every lambda listens on an SQS Queue. This isn't latency sensitive in the sense of user interaction, but I certainly care about latency to a degree - primarily throughput though.
The reason I've chosen this is because I do not want to manage an OS. Patch management is something I am not interested in tackling - it's a hard problem and AWS has it down anyways.
There are other reasons as well (I find ephemeral systems very appealing), but this is the most significant.
Lambda is not useful. It solves a few problems but creates even more new problems.
Some problems include:
- It makes managing multiple environments (e.g. development, staging, production) almost impossible.
- It makes debugging difficult because you can't run the code on your own machine and step through the code. Most projects cannot be tested end-to-end due to environment incompatibilities between different services and front-ends running locally... It's a fact that multiple developers can't share a single development environment because each developer needs to work with their own test data but Lambda doesn't allow this.
- Lambda adds all sorts of unexpected limits on your code; e.g. cold starts, maximum function execution duration and others.
- The lock-in factor is significant; once you're hooked into Lambda and all the surrounding services that it encourages, you cannot leave and you have no bargaining power in terms of hosting costs and your future is entirely dependent on Amazon.
- Other AWS services that you can integrate with Lambda also exacerbate problems related to handling multiple environments and debugging. Services like Elastic Transcoder and S3 are blackboxes and are very hard to debug. If something goes wrong, sometimes the only way to resolve the problem is to contact Amazon support and spend weeks sending messages back and forth to figure out the issue.
- You're contributing to centralization of wealth and power instead of helping small companies and small open source projects. You're helping to turn Amazon into yet another too big to fail company with infinite leverage on the rest of the economy.
- It takes the fun out of coding. As a developer, you no longer feel any ownership or responsibility over the code that you produce, you're just handing over all that code to Amazon. In fact, it might as well belong to Amazon because that's the only company that is able to execute that code. It doesn't help with employee turnover.
The main reasons why Lambda is popular are because Amazon spent a fortune on marketing it and there are a lot of vested interests in the industry who want it to succeed (to drive up Amazon share price).
Many of the problems you notice are correct, but...
> It makes managing multiple environments (e.g. development, staging, production) almost impossible.
I don't know why you say this? In my experience, this was one of the most amazing parts: my CI/CD setup simply deployed a new Lambda function for every branch in my repo, which was equivalent to the production one in terms of environment.
> It makes debugging difficult because you can't run the code on your own machine and step through the code.
It took some work to initially setup, but I did manage to do this pretty well. Perhaps related to the next point:
> The lock-in factor is significant; once you're hooked into Lambda and all the surrounding services that it encourages, you cannot leave and you have no bargaining power in terms of hosting costs and your future is entirely dependent on Amazon.
This is true, but can be mitigated. I restricted the lock-in to the entrypoint, and managed to transfer my functions elsewhere later with relatively little effort. In this case, the Lambda functions were behind an API Gateway proxy, and I converted them to the same interface used by Express.js before passing them to my business logic. That allowed me both to execute the business logic locally, and to migrate it where it is running now, on a standard Express.js server.
> It takes the fun out of coding.
Well, I can just say that it was still fun for me - most of the fun usually is in the business logic, although the experience of simply experimenting in a different branch and having a complete production-like environment pulled up for that still amazes me.
You make some reasonable points, but many of them don't reflect my experience with Lambdas.
> It makes managing multiple environments (e.g. development, staging, production) almost impossible.
It certainly doesn't. You just have to use an infrastructure-as-code tool such as Terraform or Serverless. AWS's own method of dealing with environments is best ignored.
> Lambda adds all sorts of unexpected limits on your code; e.g. cold starts, maximum function execution duration and others.
Like any other platform, Lambdas have certain perforamance limitations you need to be aware of. They're not a fit for every problem but the future is going to be increasingly serverless. These limitations are likely going to be much less of a problem as the technology matures.
> The lock-in factor is significant; once you're hooked into Lambda and all the surrounding services that it encourages, you cannot leave and you have no bargaining power in terms of hosting costs and your future is entirely dependent on Amazon.
Again, use of a platform-agnostic setup like Terraform helps mitigate against this. In theory it ought to be relatively simple to change FaaS providers (I haven't actually tried this).
> You're contributing to centralization of wealth and power instead of helping small companies and small open source projects. You're helping to turn Amazon into yet another too big to fail company with infinite leverage on the rest of the economy.
The centralisation of power and wealth is true to an extent but there are two sides to this. It's also empowering for small organisations. It allows small companies to very quickly ramp up availablity and have extremely solid reliability without a specialised infrastructure team. You can also start up something very quickly and cheaply given AWS's free usage tier.
Doesn't that mostly apply to all serverless platforms? Serverless is cheap and allows cloud providers to use excess capacity to allow small pieces of software to run, scaling almost infinitely[0]. But it is always vendor lock-in, whether you choose Azure or Amazon. It is a propietary platform but that applies for most of the cloud if you use services that don't exist elsewhere (Azure blobs, Azure Cosmos DB, etc)
d. You're contributing to centralization of wealth and power instead of helping small companies and small open source projects.
up is open-source but also has a paid plan[https://up.docs.apex.sh/#guides.subscribing_to_up_pro]
e. It takes the fun out of coding.
I'm not sure about that.
1- It's amazing that Java has the fastest cold start time! Faster than Nodejs.[1] That's exactly the opposite of what I've heard before.
2- I am so tired of hearing about cold start times for dormant apps as if that is the only cold start scenario. It is arguably a worse problem to have cold starts when scaling!
What do I mean by cold starts when scaling? You adopt serverless. Things go great. Your app is never dormant. You're not serverless because you want to shave costs for infrequently unused apps. You're serverless so you have infinite scale and pay by the millisecond and minimal devops and so on. But whenever you have a burst of scale and Lambda needs to spin up more instances... some of your unlucky users are going to hit that cold start. And this hack of keeping an instance warm would do nothing to solve that.
I mean, do they? Do we know? It's possible that AWS warms up instances before throwing traffic at them but.. has anyone looked at this?
> But whenever you have a burst of scale and Lambda needs to spin up more instances... some of your unlucky users are going to hit that cold start. And this hack of keeping an instance warm would do nothing to solve that.
I've been doing a bunch of reading as a side-effect of being in and around the riff and Knative autoscaler efforts. What you're describing is known in other professions as a "stock-out".
The good news is: there are existing models for answering this kind of question. From what I've seen the "order up to" model is a fit, but I've yet to find time to work on testing that theory.
The bad news is: this problem never goes away. You are always going to be oversupplied or undersupplied. Autoscalers don't let you break Little's Law or overturn causality.
The good or bad news, depending on how you think: this tradeoff can be tuned. You can choose an acceptable probability of running out of running instances vs the acceptable average level of utilisation. That tradeoff is purely economic, it is a business decision, not an engineering decision.
An autoscaler cannot throw the bones, gaze into the crystal ball and mystically divine your intentions. A human will still be responsible for the decisions that matter.
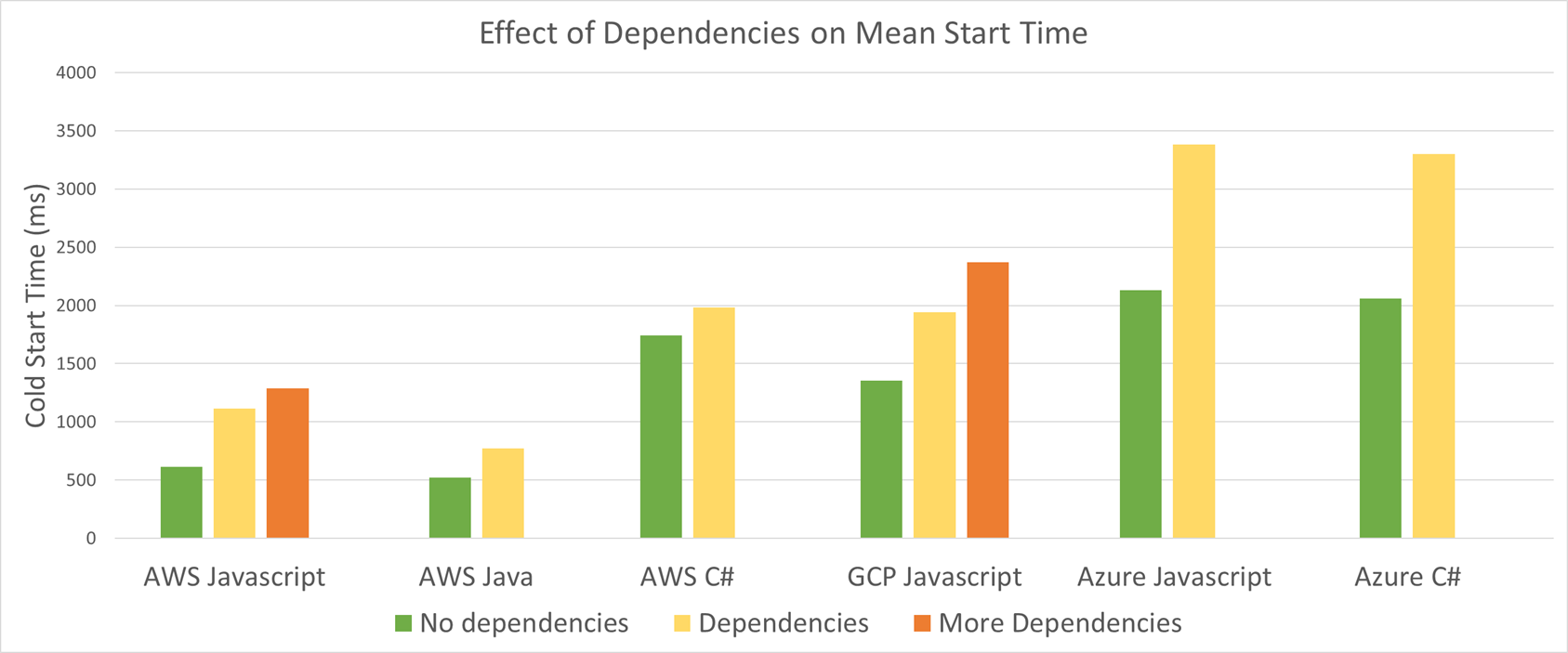
That chart is quite strange. Why would JS start take 500ms (on my system it's 80ms) and be slower to start with more dependencies?
Maybe it's because the bulk of the time is just copying the deployment artifact to the local disk. In that case the overriding factor is the size of the package.
If you require() the libraries at the top, as it seems to be common in Node applications, it makes sense that more dependencies add to the cold start time.
A shockingly large number of people run around repeating what they remember from Java 6 or earlier, without bothering to realize tha Java and the JVM have changed a lot.
Yes, one could prewarm N instances by sending N parallel requests every 5 minutes. You have to know N though :)
For most apps, scale-out cold start won't be too much of a deal breaker: longer instance lifetime + shorter start will do the trick. And wait for the next wave of optimizations from vendors, I'm sure there's more to come.
> Yes, one could prewarm N instances by sending N parallel requests every 5 minutes.
Uhh.. you’re just speculating here right? I seriously doubt Lambda spins up a whole new container for every single “parallel” request in a short burst. There’s probably a little bit of queuing and/or they aren’t exactly parallel.
I think it’s something the vendors need to solve, like by directly prewarming prior to throwing traffic at it.
I agree the vendors needs to solve this. In the meantime I think you can hack it by using Kinesis shards ( one lambda per shard ) if you know you will need many lambdas in advance. https://github.com/awslabs/aws-lambda-kinesis-prewarming
I don't know how serverless platforms deal with it, but startup times could be "solved" by starting up the function and cloning it when it's ready to process requests, as Unix daemons have done for a long time.
What if we had smaller programs, such that an executable could be started on demand for each request? You could also avoid GC and long-term stability issues this way by having a short-lived program. It even allows you to have multiple different microservice functions written in different languages served by the same system. So long as they use a similar API - we could call it a Common Gateway Interface?
(Yes, this is a joke based on how we used to do it 20 years ago)
One thing this doesn't talk about is Cloudflare Workers. Rather than running a separate container for each function we use V8 isolates directly, meaning the cold start time is under 5ms.
Interesting. I always thought AWS Lambda being a complete Linux environment with curl and everything is just supremely wasteful. What could be the reason AWS implemented it like that? To support many programming languages /runtimes?
I feel as if the whole "warm up the lamba as a pre-step"-thing takes away from the whole benefit of serverless. I wonder if AWS Lambda could be smart enough to anticipate requests based on some historical or daily pattern. Also, I'd be curious to know if it is still cost effective to use lambda with this technique (pre-warming) or to straight up go for a EC2 instance.
Or.. you know.. don't have user-facing interfaces serviced by endpoints that aren't running all the time?
I can see that maybe there is a case to make for using functions as a service, to handle batch processing of things, or possibly to service background API requests.
> I wonder if AWS Lambda could be smart enough to anticipate requests based on some historical or daily pattern.
This is called "predictive autoscaling". In other fields it's called seasonality and you can build inventory and manufacturing plans around it.
While researching FaaSes last year I saw a slide deck from an Amazon PM about Lambda (I promptly lost the link). The thing that stuck with me was a claim that a substantial amount of their autoscaling "magic" was due to predictive autoscaling.
Netflix wrote up[1][2], but have not opensourced, their predictive autoscaler "Scryer" in a few blog posts. The tl;dr is that they use a combination of fourier transforms and simple correlations to make a basic forecast of how many VMs to have ready at different times of day. A reactive autoscaler adjusts on the day.
I'm still really puzzled why AWS lambda has golang and Azure functions has Java and python but GCF doesn't have anything but JavaScript. That's a big hole that must be leaving a lot of developers feeling frustrated.
GCP is just very slow at releasing and behind in both features and services as compared to AWS and Azure. The trade-off is that the GA services are usually more consistent, cheaper, faster and easier to use and integrate.
GCF is still in beta so it's the worst case, but they recently announced Serverless Containers which will let you run anything insider a docker container on-demand. That'll get around the language barriers and is the inevitable destination of all serverless platforms eventually.
I do feel like "Firebase Cloud Functions" (GCF) is generally more polished than AWS Lambda. Lambda seems a little like it was slapped together and the UI often seems a little incoherent, which probably reflects their first mover advantages and disadvantages. It is not always straighforward to use the CLI tools for Lambda as well (but you can just wrap them in a bash script and forget about it generally). But, there are subtle gotchas with working in JavaScript (Promises!) especially within the context of a lambda/function. If you return the wrong thing inside your function or misunderstand the way promises work, you can get something that looks like it works and passes lint, but fails in production, and the logging pipelines for both AWS and GCF leave a lot to be desired.
Azure doesn't yet have meaningful Python support - `import requests` will take >10s to run every time. The next version of functions will do, but when they say preview it really is right now.
I'm not sure if there's an equivalent in GCP but one of the issues we have with AWS lambda is that cold start performance is also greatly affected by whether or not the function is running in a VPC. In addition to warming up the function, a virtual network interface has to be attached to the worker. This can take 10+ seconds in the worst cases.
Hopefully this is an issue AWS fixes soon. The VPC cold start latency could end up forcing you to make some less than optimal infrastructure choices like running infrastructure on the public internet
The whole point of serverless functions is to do work that isn’t necessarily real-time, but of which this is a lot and each unit of work can be completed relatively quickly (say, periodic sync tasks and the like). I really think if the nitty-gritty of cold start behavior is foremost in your mind you’re likely Doing it Wrong(tm).
I like that we're seeing more nuanced evaluations of serverless than the previous hype, but totally agree that there's certain use-cases where serverless shines and cold-start seems negligible in practice.
For example, on the real-time side, busy APIs with functions than execute quickly. If the caller has either a decent timeout + retry configured (or doesn't care), cold start really isn't an issue. User facing web technologies? Serverless has never been that compelling for that given auto-scaling webservers is a pretty solid technique.
But truth be told, not having to deal with servers at all is magical. And if your team is used to it, it does cut down on a lot of worry such as patching stuff. Spectre or Meltdown patches? Ha, zero effort for us.
> But truth be told, not having to deal with servers at all is magical. And if your team is used to it, it does cut down on a lot of worry such as patching stuff. Spectre or Meltdown patches? Ha, zero effort for us.
The problem with this (which applies to "cloud" infrastructure) is that, ultimately, it's somebody else's server.
You may not "worry" about something like low-level security patches, but that also means you have no control or even visibility into them. It doesn't mean you're not subject to the consequences.
Of course, there's always something magical about any form of outsourcing when it works realy well. I'm not sure this form has enough of a track record to be blindly trusted, however.
If you are using serverless functions for something that a user sees, cold start time matters a lot more. Python's Zappa is made for taking Flask/WSGI apps to AWS lambda, and it actually has a configuration option to allow for automatic invocation of functions on a schedule to keep a pool of warm containers.
I`m making a multiplayer game that includes dices using firebase + cloud functions. I must use cloud functions for the game because I can not let the client roll the dices on it`s own and just let it write to firebase, that could be easily cheated. When starting the game, cold starts are very noticeable, but after a few moves, everything feels fine.
Has anyone here migrated back from lambda to conventional servers? How was the experience like. Is there any straightforward way to convert serverless projects to traditional services en masse. In what cases would you recommend moving away from serverless?
We have from Google cloud functions because they are a joke (see cold start graph on OP link). Even during development it was horribly painful to have 10+ second call times on many many requests while testing (and the same in production). Even requests that are only a few minutes or seconds away from each other would cold start randomly.
I already had a centralised entry point for cloud functions (just a basic abstraction), but generally they are pretty much wrapped Express requests, in GCP at least, and AWS too I think so the experience should be similar between AWS and GCP.
Changing that to be actual pure Express functions and not use the cloud functions API was pretty easy and quick, and while I was there I refactored our entry points a bit to be easier to migrate in the future.
The only thing that took time was making a new deployment process (we moved to App Engine so it's still "kinda serverless"). Since cloud functions have their own deployment system, I had to write our own deployment scripts, management of environments and so on rather than relying on the one provided by firebase cloud functions. Not a lot of work really, and this is something you would need if you have your own seevers anyway.
Once you have this done, it's pretty easy to move your "cloud functions" to any scaling node server host, or even to another cloud FaaS provider.
Eager to test it out we ran thousands of tests attempts with different RAM sizes and I can corroborate this persons findings in regards to the reduction of cold start time from functions with larger RAM allocations and seeming unpredictability of cold start on GCP. I hope with time they will improve cold start times or increase the minimum time for making a function "cold".
From the parts I can see in Knative-land, it's being given a lot of thought. My view is that the biggest improvement to be made is in smarter handling of raw bits. Kubernetes doesn't quite understand disk locality yet and most docker images are less-than-ideally constructed in any case.
I wrote several thousand words on the topic a few months (email me for the link).
The gist is: you can make an image easy for developers, or you can make it performant in production, but you cannot have both.
Ease of development typically leads to kitchen-sink images or squashed images, but production performance requires careful attention to the ordering and content of layers.
An alternative approach for user facing apps is to connect directly to the database from the browser. Lambda still has a role to play in such an architecture, but hopefully most of your basic crud operations can go direct, with less commonly called functions like login depending on Lambda. I address this option about 2/3 of the way through this webcast on serverless best practices https://blog.fauna.com/webcast-video-serverless-best-practic...
Thanks. :) That was the last thing I wrote before falling asleep... TLDR is that many (not just FaunaDB) cloud databases have a security and connection model that's suitable for connecting from the browser. I know Firebase has been doing it forever, and you can also do it with DynamoDB if you don't mind complexity.
It takes a little bit of thinking to set up the security rules so that users can only see what they are allowed, but it's worth it for the performance and runtime simplicity. And of course you can always invoke a Lambda for code paths that need to run with privileged access.
The comparison of JavaScript cold start times by the number/size of dependencies is a little confusing.
I’m not too familiar with how all the various serverless platforms work, but a decent bundler would surely improve the cold start times of most JavaScript functions. Deploying dozens of megabytes of dependencies across dozens and dozens of files is obviously going to result in a longer start up time than uploading a single bundle generated by webpack or Rollup.
Enforcing a single <1MB file [0] seems to have at least partly allowed drastically improved cold start times for Cloudflare Workers in comparison with AWS Lambda, Azure Functions and Google Cloud Functions (although Cloudflare Workers also a much smaller feature set).
One of my favorite articles of recent times. What jumped out at me was that there is a dramatic difference in start up time depending on how much memory your cloud server has: the more memory, the faster the start up time.
Which is not necessarily intuitive. For all I knew there was some kind of penalty of a 1025MB memory image vs 512MB. Didn't think so... but I'm increasingly baffled by hardware issues in an increasingly virtualized world.
So, what is the killer app of faas? To my layman understanding the selling point is easy scale-ability, but it seems to be inherently at odds with serverless being the most expensive computing model?
Not necessarily; what matters is how peak-y the demand is. For example, my country's teachers portal gets orders of magnitude more requests during a couple of weeks of the year than the average (at the start of the school year). Going serverless for those processes might make sense.
While the idea of only paying for what you use seems to be an interesting proposition with serverless. I think the true cost savings come in no longer having to manage VMs.
With that in mind the coldstart problem can be avoided entirely with Fargate and Azure container groups. Sure you pay for an app to be on all the time, but you were doing that anyways.
I’m using Azure container groups and their managed DB service right now, and my CI pipeline is thin and I have had no need of an Ops person to manage VMs.
This is just AWS, GCP, and Azure — it would be nice to see Zeit and Cloudflare Workers in the comparison as well. (Any other serverless providers of note?)
I think there is a business case for a small app where you could input the url of your function and have it called every ‘x’ seconds or minutes to keep the function warm.
Would anyone here use it? I can put together a small app in a few days.
He is describing an HTML+JS solution. Even then, it's just a few lines of JS - create an image or a script object with a given URL, append it to the body.
At least on AWS, increasing memory also comes along with more compute and more networking bandwidth. If there are a lot of packages to be imported and possibly decompressed that could have a large impact
"AWS Lambda allocates CPU power proportional to the memory by using the same ratio as a general purpose Amazon EC2 instance type, such as an M3 type. For example, if you allocate 256 MB memory, your Lambda function will receive twice the CPU share than if you allocated only 128 MB. "
{kind=link}
And because it's a "Cloud" service, we pay for what we use, so if there's no workload for the functions to service, there's no cost. We just pay for the time the tiny little container is active.
Business: Ok, that sounds like it can save us money, and you seem confident in the technology, let's go with that.
1 Month Later:
Business: Why do all these actions take so much longer to complete? They used to load instantly with a "Done" message, now they're measurably delayed to respond.
Tech: Well, you see the containers that run our functions stop running once they've finished their work and it looks like theres nothing more for them to do, so when new work comes in theres a delay while the container starts.
Business: You mean like how my Dell takes 5 minutes to boot up?
Tech: Well, kind of, but its much quicker than that obviously, and it's not a whole operating system, it's just some processes in a process namespace...
Business: <visibly zoning out>
Tech: Ok, well tell you what we can solve this, we can setup something to periodically ping the system so the containers running our functions don't ever get de-activated, and that way they'll be ready to service requests immediately, all the time.
Business: OK great that sounds like what we want.
1 Month Later:
Finance: Why did our bill for "functions" suddenly spike in the last month, compared to when we started using it?
Tech: Well you see now we have to keep the function containers running 24x7 so they're quick to respond, because $Business complained they're too slow to start up from inactive state.
Tech Onlookers: ..... <blink>.... Wat... Why... Why would you do that?
(Edited to add:)
Tech Entrepreneur: I can outsource that process of keeping your function containers active for you, for just $1/container/month!