Why does it require that the server has password logins enabled? This seems contrary to every "secure your server" guide I've seen and opens your server up to the password guessing game. It seems like a cool product, but that's a huge non-starter.
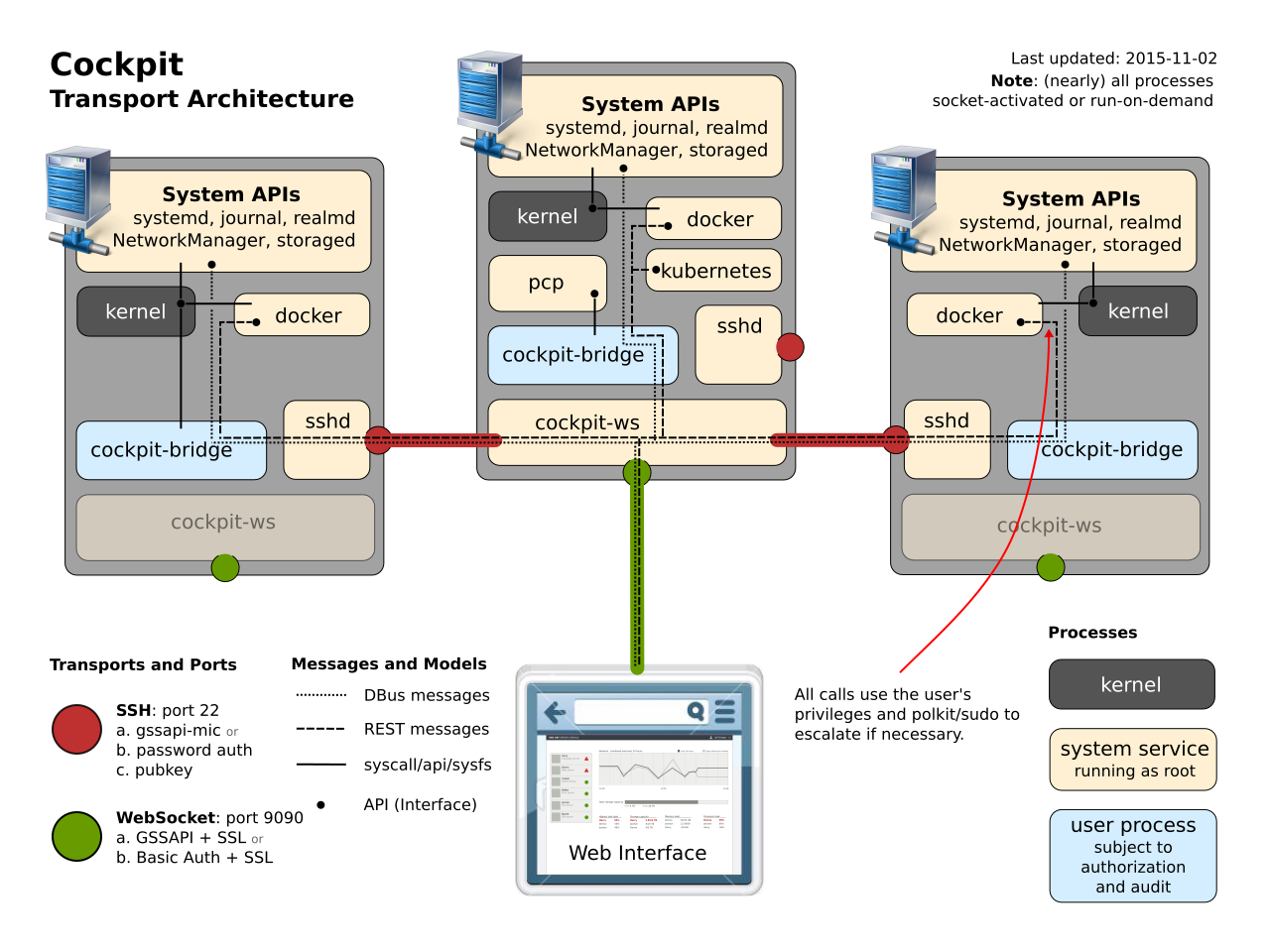
The target server will need to have password based authentication enabled in sshd. When this is setup for the first time, Cockpit will ensure that the user connected to primary server has the same password on the secondary server.
I don't think it does. That quote is from the section explaining how to configure "Password" authentication. i.e. to use Password authentication, you must enable it on the target server.
It then goes on to list how to use Kerberos or Public Key methods.
You are right, I missed the one liner above this that stated it needed one of these methods: [password, kerberos, or public key].
However, it does sound like if you use the docker image that you need password logins on the primary machine unless you modify the docker image to add a public key. I may just be reading wrong again though.
Reading again, it does look like the installation is limited in some way if you choose to use public keys and your user doesn't have the privileges (without sudo) necessary for some of Cockpit's commands it tries to run.
Note that when a user is authenticated in this way [public key] the authentication happens without a password, as such the standard cockpit reauthorization mechanisms do not work. The user will only be able to obtain additional privileges if they do not require a password.
You could run a dedicated SSH server listening on local host, accessed through a tunnel. Not ideal but not non starter either, if the benefits of Cockpit are that big.
The web server can also be run from the cockpit/ws docker container. If you are running cockpit on an Atomic Host this will be the default. In this setup, cockpit establishes an SSH connection from the container to the underlying host, meaning that it is up to your SSH server to grant access. To login with a local account, sshd will need to be configured to allow password based authentication. Alternatively you can setup a Kerberos based SSO solution.
AKA, it is up to your SSH server to grant access to the container.
Probably because these "security guides" just repeat what others said without any real consideration?
In fact, using key-based authentication just shifts the weak point from one server to another, and, if implemented incorrectly (let's login without passwords to several servers - how convenient!), it's a security disaster. People need to think rather than follow recommendations blindly.
"Common knowledge" is a big problem in the security industry, like you mentioned. It's common knowledge that you need a 32 character randomly generated password with special characters and numbers and mixed case, right? But actually that's less secure, and now security folks have to work overtime to convince people otherwise.
And it's common knowledge that passwords are super insecure and should be replaced, but oftentimes the people replacing them don't understand that it's possible to replace passwords with a less secure system, and don't have the skills necessary to judge that risk.
Key-based systems do have their risks. If I compromise your dev machine (probably using a simple password), I now have free access to all the machines your key unlocks.
Defense-in-depth is important, as well as a strong IAM system. You need physical security to protect your dev workstation, coupled with a strong login system to your machine, hopefully a VPN (locked with a physical token) or local network requirement to get onto your production servers, and then break-the-glass methods to check out permission to escalate your privileges when needed, followed with a keylogger for your admin session and attestation that your break-the-glass in production was necessary.
That being said, if you're looking for a replacement for logging into your production machines over the Internet with a simple password... key-based authentication is lightyears ahead of what you're doing. Passwords are far too easy to guess or brute force.
the part that gets me is that key based authentication is much, much more secure, as long as you have a passphrase. How many 'howtos' and other sites on the internet say to just create a key with no passphrase? Its right up there with the number of guides I see for deploying things on Redhat, that first have you disable selinux.
Yeah as someone who works in the security industry, the ubiquity of security awareness targeted at end users is both a blessing and a curse. It's a blessing because now many more people know what key-based authentication is. It's a curse because now people get mad when my report has a finding that their no-passcode single key authentication system is worse than the "use your RSA token to check out the constantly-revolving root password" system they just replaced.
Like when people use the phrase "two-factor authentication" without knowing what the three factors actually are and why they matter.
If you compromise my dev machine, you'll install a keylogger and sniff all my passwords. The only way I see that even passphrase-less keys are worse than passwords is if I physically lose the machine (and don't use full disk encryption).
I am sorry but your example of 32 character password chosen at random is not less secure to brute force. There are 95 type-able characters on qwerty keyboard. That's 95^32 possible possible passwords or about 2^210. Compare that to an AES-128 key. That's only 2^128 possible keys. So a truly random password of such length is harder to brute force than AES-128.
The real reason is passwords are weaker is first and fore most people. People reuse passwords or choose ones that are too short or simple that brute force becomes possible. If passwords where chosen at random and of proper of length they can be equally as strong as a key. Further, passwords basically functions the same as a key symmetric cryptography. People just don't like to memorize long random strings. (Although many apply key stretching since passwords may be of lower entropy).
Second when it comes HTTP it really only supports basic and digest authentication which is based on MD5, and further is susceptible to offline brute force attacks, and a down grade attacks to basic without TLS.
Thusly, most websites just send your password over TLS. However, because each site basically can handle passwords however they want they can store them in plain text. Secondly, if your TLS sessions is compromised you sent the password over over that connection it can be compromised. Sadly, the browsers don't support J-PAKE which by the way has an RFC.
I guess my point is password authentication can be just as secure, and really they are just shared secret crypto-systems. Problem is people choose low entropy passwords first and foremost. So just generating a key and saving locally avoids that issue.
Websites (HTTP) can use client X509 side certs as authentication and this gets rid users choosing bad passwords. However, if browsers implemented J-PAKE you don't have to worry about accidentally visiting the site via plain text will comprise your password or a comprised certificate authority. You could always validate the certificate yourself since we don't have something like J-PAKE in place.
For SSH long passwords can be just as strong, but you must verify the fingerprint matches your servers else you may get MITMed. Although if people see a server with SSH using password logins. They may try to brute force the password which may be annoying for the system admin. So the system admin enables key based authentication stop people from trying. Even though you have a high entropy password and your not worried about a brute force attack. The attacker does not know that so they will try anyways.
I'm neither a sysadmin nor a securyt expert, so I might be terribly wrong, but, as I understood it, password-based authentication was undesirable because the attacker could try to brute-force it.
Key-based auth doesn't have this flaw so it's arguably safer in that it has one less entry point.
On the other hand, not sure I fully understand your argument. You are saying that not being vulnerable to password brute-forcing is not enough since you could still hack the server? or what exactly do you mean by "just shifts the weak point ... to another"?
>what exactly do you mean by "just shifts the weak point ... to another"?
I'm not the person who made that argument, but I can give you my reasoning to support it.
Your key is on your laptop and unlocks your server, now your server is safe. But your laptop is just secured with a password. I brute-force the password on your laptop, and now I have no barriers preventing me from accessing your server. Your server is secure, sure, but the risk was just pushed back to your laptop which may be more or less easy to compromise than your server (depending on the threat).
I'm not arguing that key-based authentication isn't a good step forward. If you're using passwords on your Internet facing servers, stop doing that and start using keys. But you also have to protect your keys and any machine those keys are installed on, otherwise you're just shifting the weak point to another machine.
> But you also have to protect your keys and any machine those keys are installed on, otherwise you're just shifting the weak point to another machine.
I’m okay with this, personally. What’s riskier: a public server listening on port 22 for any SSH traffic or my personal laptop which doesn’t accept random requests from the entire internet and is almost never out of my sight? And even if someone compromised my machine (e.g. theft), they probably don’t care or even understand what SSH keys are; they’ll probably just wipe the thing and sell it on the black market.
That’s not a good reason to ignore sound security practices, but threat model-wise, my laptop is much less likely to be targeted and successfully compromised physically by someone who wants to SSH into my build server.
Your laptop, maybe. It sounds like you understand security, which is good. Not everyone does. I'll give you an example:
I have a picture I like to use in my presentations where I was at a mostly-empty family restaurant and the person sitting next to me (alone) had their laptop sitting out and went to the bathroom without even locking the screen. In 15 seconds I could have popped in a USB drive and copied all of his SSH keys (and more) without anyone ever noticing. It could have been done before he even reached the bathroom door, let alone came back. I don't think you would do this, of course, but some people do. And your coworkers might.
On top of that, about 25%-30% of security incidents are caused by insider threats. Considering how easy attacks over the Internet are, that's an absolutely massive number. Even if your laptop never leaves your desk, it's entirely possible someone within your company might want to do some harm to you or the company and it might be the desktop support technician hooking up your new monitor while you grab another cup of coffee.
Your point about what's riskier is completely true: if you have Internet-facing servers using passwords, stop that and use keys. But when you do that, you need to study up on the new risks you may not be aware of. Security shouldn't just be a curtain you close. Companies/people who don't understand this love paying me shitloads of money to explain it to them :)
Why would you not have a passphrase on your key? Passphrase encryption is the default in ssh-keygen and probably every other ssh key generation utility. Having a magic file that grants access to a server scares the crap out of me -- but use the passphrase feature and it's far more secure than password auth.
You'd be surprised. ssh-keygen allows you to just hit enter and bypass the passphrase with no hoops to jump through and insufficient warning (IMO). Maybe that should be changed. But right now it's all too easy and convenient.
> Key-based auth doesn't have this flaw so it's arguably safer in that it has one less entry point.
This is exactly what people think when reading the guides. In fact, it's not that there is one less entry point, but this entry point was moved and now exists on another machine together with the key. And since many people use one workstation to log in to several servers, you now have one single point of failure (an equivalent of using one password for all servers).
I'd appreciate a good argument apart from downvoting. In every discussion I had about it with fellow sysaddmins we agreed the convenience of passwordless logins can't be considered a security feature in spite of what someone wrote and what others repeat.
No glove fits everyone. There are many answers to the problem and each depends on the set of circumstances in which your service exists. Security is, simply put, risk management.
To put things into a context: the 'average Joe' user is rarely going to be targeted specifically - which means that the biggest attack vector of the average user is brute forcing by bots and phishing attempts or maybe a key/password stealing malware.
Hence your argument that 'key-based auth' just shifts the attack vector is partially incorrect because automated attacks do not focus on a specific target but on a specific vulnerability - like password guessing bots for example which move from IP to IP and try a bunch of simple password. If these passwords don't work, the bots will not try to hack a dev's workstation, they'll just find an easier target.
So for the average user it makes sense to move to key based auth because it will remove a big attack vector. It is still possible that the workstation where the private key resides becomes compromised, but thats another attack vector that needs to be addressed by different security methods (eg, passphrase on the private key).
Does it work on non fedora/redhat? Does it need an agent on managed systems?
I'm developing a somewhat similar system[1], based purely on very easy to develop plugins, agentless, and integration with third parties where needed (Prometheus, for example).But without big corporate backup it is being difficult to keep the development pace.
I've used it before on Ubuntu and it worked just fine. As far as I understand, Cockpit deals directly with Systemd and Docker, so any system based on Systemd should just work.
Again, Cockpit does not explicitly deal with systemd.
Cockpit deals with dbus, and systemd is conveniently available there (hostnamectl, etc). storaged, networkmanager, and other functionality is not dependent on systemd, so it's really just the system journal, changing the hostname, and checking service status which would fail without systemd.
Docker is not required at all either, though it's an option.
That is directly contradicted by Cockpit's own doco, which explicitly states that Cockpit uses the systemd APIs and that "use of alternate system APIs are not currently implemented".
It should of course be obvious that Cockpit does explicitly deal with systemd. Desktop Bus is a transport layer, and the important thing about it is what DBus servers are on the other side of the broker are being talked to. In the case of Cockpit they are things like systemd's own idiosyncratic API for process #1 ...
Yes, cockpit uses hostnamed and timedated. Plus journalctl, which I noted. I'm perfectly aware of how dbus works, and if you think that hostnamed or timedated have 'idiosyncractic' APIs, I'd challenge you to look at the API for glib.
But it uses these because they are readily available over dbus. Not because cockpit has a hard dependency on systemd.
While that functionality wouldn't work, it would be really trivial to write your own using cockpit.spawn() to call `date`... or `hostname ...` instead of hostnamed or timedated. The truth is that hostnamed and timedated are simply better than the CLI tools.
However, I'm sure the Cockpit team would welcome a patch.
More to the point, there is absolutely nothing in Cockpit which is explicitly using systemd APIs outside of dbus, and this would not be hard to work around.
It would be a 20 line patch to break the systemd "dependency" on hostnamed. This is not a project intrinsically linked to systemd.
Even your hardwired "example" of journalctl is literally calling a process, which could just as easily be "cat /var/log/messages". It's 'hardwired' because systemd is the standard these days, whether you like it or not. However, extending the promise to simply do that if journalctl fails is trivial.
Maybe your idea of 'hard' dependencies and mine are very different. To me, a 'dependency' on, say, Python, means that there are Python calls all over the place which a reliance on specific semantics. That means that stubbing it out for Ruby or Lua or whatever would be hard. It is not "we wrote our application with this in mind, but we could patch it into stubbable modules in 3 minutes".
I think you just proved my original point[1]: As shipped, Cockpit will not function as intended on any OS that doesn't use systemd. If it requires patching and legwork the maintainers have not and do not yet plan to implement, it's up to the server maintainer to shoehorn it into their system. That would probably be more work than it's worth just to try out something that may still end up broken with each future update.
Again, no hate for systemd here, I was just pointing out what I had read in the documentation and making it known. FYI my laptop runs Elementary OS which fully depends on systemd and I have no issues with that situation, nor do I "hate" it. If I did I would run a different OS on it. systemd is part of Linux for the majority of distros, it's likely here to stay, and these days it's stable enough for daily use.
Personally I'd much rather see a GUI that can help string together snippets of Terraform/CFN and Ansible/Chef/Puppet/Salt/whathaveyou. A visual IDE for infrastructure automation, if you will.
IBM's SMIT did this, and did this 25 years ago (although it generated shell scripts instead of Terraform/CFN/Ansible/Chef/Salt/Etc you mentioned). You could have SMIT just go ahead and do whatever, or you can have it show you the sequence of commands it would do.
And it worked both from the command line and the GUI. I can see no issues with it having a web interface as well.
It really does feel like we're slowly recreating the mainframe the hard way, doesn't it? Some day soon we'll be rewriting Terraform in LISP and running it on something that might as well be z/OS.
So the idea is that you would choose your changes in the GUI, but instead of actually changing the target, it spits out the required code to do it for you in a repeatable way?
I would definitely find that useful for Terraform and Cloudformation. Searching for it, I see that AWS has a tool targeted at that: Cloudformation Designer.
A better idea would be to spit out a spec that tools could use to perform the thing, and get tools to follow the spec. Unfortunately, even though most tools do virtually the exact same thing, they all use their own incompatible ways to describe it in a config. I'm not sure why devs enjoy reinventing the wheel in incompatible ways all the time.
For example: you have Puppet, Chef, Ansible, Salt, etc. They can all make a directory. They do exactly the same thing on almost all systems they support, because POSIX.
They literally all just run this syscall: int mkdir(const char pathname, mode_t mode);.
But each tool has their own goofy way of being told to make the directory. Why can't I just pass "{'mkdir': [ '/the/path/name', '0700' ]}" to all of them? This is literally all they will be doing, and all they need to know. Just make this path with this permission. This is declarative programming, without a custom language!
Anything else, like directory ownership, should be an extra object, like "{'chown': [ '/the/path/name', '1000', '1000' ] }". Again, this is literally called the same way everywhere: int chown(const char pathname, uid_t owner, gid_t group);.
You can combine the two into one JSON blob in the output of this config management tool (that's what this GUI really is - a GUI CM with a dashboard). You can have sets of blobs with tags that are discrete reusable pieces of configuration. And every tool can just read them, follow a spec based on POSIX, and execute them.
Sure, you picked the simplest possible case for a configuration management system. Now, in this very simple case:
- What happens when "/the/path" changes depending on the distribution? How do you specify that?
- What should happen if the "/the/path/name" already exists? Should the system touch it or something?
- What if it exists but is not a directory? Should it delete whatever exists and create a directory instead?
There is no way to define that stuff using POSIX semantics, because POSIX is inherently imperative. "mkdir" means "make a directory", not "on this path there must be a directory".
That mismatch in semantics is real, and each configuration management system tries to close that gap in the simplest, most user-friendly way they can figure out. Most have flocked towards defining their own, as declarative as possible, API. For instance, ansible defines this as:
- name: Ensure name's base folder exists
file:
path: /the/path/name
state: directory
recurse: no
owner: pid/name
group: gid/name
I do think that, like that snippet above demonstrates, none of them do an astounding job at defining that API. However, I blame their failure to the hardness of the task, not to the incompetence of the developers of ansible/salt/puppet/etc.
Well let's be clear: a lot of tasks people try to accomplish are just bad ideas. Config management is not about having a magical tool that does everything you want exactly how you want on 50 platforms using one config file. Config management is just managing complexity. It works better the less complex it is.
The example above is two basic operations: mkdir and chown. On top of those operations are policies, rules which need to be applied. And then there are transforms, where the arguments or policies may change depending on some variables.
These are all different things that the above rule is mixing together, and we're supposed to think this is a good thing. We pretend it's less complex, but it's not, it's just obscured. And the end result is a lot of wasted effort to redo the same thing.
The GUI is useful because it can craft the operations, policies, and transforms for you, and output instructions to be interpreted and executed by an agent. You could keep all the complexity, but make it standard among a set of common tools. They really all do the same things - they just don't speak the same language.
Another way to think about this is from an app's perspective. It just wants to write to a log file in a directory, it does not care where. That's somebody else's job to figure out - just tell me where the file is! Wouldn't it be handy if the app had a language to tell a CM tool what it needed? It wouldn't have to say "make me file X in Y dir", it would say "give me a writeable file that I will call 'log_fd'".
Then we wouldn't need to craft an environment for it like parents assembling a nursery. The apps could be more self-sufficient, and the CM tools would just do their bidding. Using a standard language.
> a lot of tasks people try to accomplish are just bad ideas.
For most people, the point of config management tooling is to turn all their manual, bus-factor-of-one crufty legacy processes into automated, documented, centralized crufty legacy processes.
Ops people don't want a system that is opinionated or that pushes back to force them to change their process. They want a Turing-complete system, and maybe macros as well, so that they can quickly encode their hairy manual process into a hairy automated process, and get back to all the other firefighting they have to do as ops people.
In theory, with unlimited resources and fully automated systems, there should be no infrastructure problems to firefight. But probably even with limited resources we shouldn't need to firefight so much if it was engineered correctly.
I think about cars and planes, and wonder what life would be like if we needed a team of engineers sitting on the wing of a plane to keep it in the sky when the pilot moves the flaps.
> what life would be like if we needed a team of engineers sitting on the wing of a plane to keep it in the sky
It's the world we'd be in if new planes were in such high demand that the number of startups building them totally outstripped the supply of aeronautical engineers, to the point that most new designs only had ~5 man-years of effort invested in them on release, rather than the thousands they get today.
Software is really a different world, economically.
Can you explain a bit further how do you see that working? I use CM because I want to control the app; I want to tell it where it should store its logs (so I can process them), where it should store its data (so I can back it up), which ports it should use (so I can point my reverse proxy at it), etc.
If the app just asks for stuff, where would the management part come it? And why have a CM at all? Granting resources is what the OS itself does; the application can just call tmpfile().
A traditional CM tool in this new paradigm (which i'm coining App Management before somebody steals the idea) would probably become more of a configuration fulfiller (CF) in this context. It fulfills the configuration requirements that the app dictates.
The CF could modify its behavior to fit a given platform. If you're on Windows, it will do operation X in one way, and on Linux a different way. You could describe to the CF the information it needs to fulfill requests - where are the big data volumes, where are the credentials, how should it connect remote resources, etc. When the app asks for something, the CF will have just enough information to figure out how to provide it for that case.
The app can label resources however it wants. For example, if it called tmpfile("my_logfile_access"), a CF could return it a temp file, and record in some datastore that application X asked for a logfile 'my_logfile_access' and that it was provided. If you want to process logs, ask the CF where the 'my_logfile_access' file/directory is. If you abstract away the need to tag it and just have a function called logfiles() or something, you wouldn't even need to know this tag - your app could just write logs with some tag metadata, so when you go to process the logs, you figure out what it is after you've opened the logs.
Same for data, and ports, etc. Why should I have a Vagrantfile that maps ports? The app knows what ports it wants to offer. And why use numerical ports? We've had /etc/services for like 30 years and yet nobody seems to realize you can use a name instead of a port number and stop worrying about manually mapping numbers around. Honestly, so much of modern devops stuff is backwards.
Your ideas resonate a lot with dependency injection [1] to me. However, I don't see how such an "App manager" would be able to setup, for instance, an nginx server with multiple virtual hosts.
Some applications need entire configuration languages because they are so flexible that writing some ini/json/xml quickly becomes too cumbersome. How would your system deal with those problems?
Finally, your proposed solution seems to suffer from having to adapt all applications to be able to manage them. This is impractical to say the least, and if you had the resources to take that adventure... I think you'd be better off turning to something like Nix
This is a dumb example, but illustrates one way this could happen. The actual CM in the background that the App_Manager library connects to would take these config directives and communicate with the other software (nginx) in order to set it up how the app above has specified.
Ideally the above would not include an Nginx-specific configuration, but one that was more abstract, to allow any HTTP service to provide for the needs of the application. That's probably wishful thinking. But on the other hand, there are probably millions of examples of an application needing an HTTP server in extremely similar ways, so maybe service-specific configuration specifications aren't totally insane.
> Some applications need entire configuration languages because they are so flexible that writing some ini/json/xml quickly becomes too cumbersome. How would your system deal with those problems?
You can abstract away almost all of the details of an automated system. They're just not built today with this in mind. Systems today are built as isolated islands of complexity and depend on humans to teach them how to shake hands. This is largely not necessary, but it is with how people are currently managing systems.
> Finally, your proposed solution seems to suffer from having to adapt all applications to be able to manage them
In the same way that networked applications "suffer" from adapting a standard protocol.
Another example:
#!/usr/bin/perl
use DBI;
$dsn = "dbi:SQLite:dbname=$dbfile";
$dbh = DBI->connect($dsn, $user, $password);
$sql = 'CREATE TABLE people (id INTEGER PRIMARY KEY, fname VARCHAR(100), lname VARCHAR(100), email VARCHAR(100) UNIQUE NOT NULL, password VARCHAR(20))';
$dbh->do($sql);
But this looks complicated; I guess asking apps to suffer under the concept of a standard interface and language will never catch on.
When I apt-get install most applications, I don't need to tell them where they should put their logs, they just the mkdir('/var/log/...') API. I don't see us gaining much by adding another man-in-the-middle to translate a logfiles(X) call to mkdir('/var/log/app')/open('/var/log/app/'+'/var/log/'+X).
The reason I use a CM is mostly to configure the system itself (such as - which apps I want installed in the first place) and to define application-specific configurations, which a configuration fulfiller would have no way of knowing how to do.
The app knows what ports it wants to offer.
No, the app knows what services it wants to offer; ports are shared resources, so they can't be defined by each app.
We've had /etc/services for like 30 years and yet nobody seems to realize you can use a name instead of a port number and stop worrying about manually mapping numbers around.
On the contrary; /etc/services is part of the old paradigm, in which each application got a static port that you had to manually configure, even if you used a text file to give it a label. In my systems, the CM takes care of that, by allocating any free port and taking of the bookkeeping to prevent double use.
That is the polar opposite of what I'm suggesting. The FHS is designed to tell every application where everything will be. My idea is to have every application tell the system where everything will be.
Part of the problem is systems having their own standard. What I'm suggesting would be a standard way of an application defining its own standard, which other applications or systems could interrogate and learn dynamically. It would effectively end a majority of platform-dependence, other than the platform-specific interfaces we unfortunately have to live with.
> No, the app knows what services it wants to offer; ports are shared resources, so they can't be defined by each app.
> On the contrary; /etc/services is part of the old paradigm, in which each application got a static port that you had to manually configure, even if you used a text file to give it a label
You are missing my point. The point is to get the application to dynamically pass a service which it needs or wants to share.
Ports are shared resources, but that does not mean they can't change. They are largely disposable, arbitrary numbers assigned to higher level concepts. We assign them statically because you can't easily bind one port to more than one application, and due to the inherent limitations of most protocols.
There is no reason I should need to tell Docker to "map internal port 80 to external port 18080". I should only have to tell it "I'm running http, please tell whoever connects to you (Docker) that I'm running http, and give them a port to access my http service on".
I don't mean to be offensive, but I'm not sure you've necessarily delved deep enough into the space of config management to understand that what you're talking about falls into three sort of areas: 1) irreducible complexity as a fact of life when the management mechanism must adapt to all possible use cases, 2) solved problems, where the means and best practices for doing what you're asking for is already there, and 3) asking for things that don't really make sense.
How so?
> The CF could modify its behavior to fit a given platform. If you're on Windows, it will do operation X in one way, and on Linux a different way.
This is exactly what most CM tools do. Chef is my specialty and in Chef, anything that makes sense to do on multiple platforms will, if done correctly, present a unified interface. Resource providers and community cookbooks abstract the OS-specific stuff from you, the CM administrator, so you can just include high level concepts. When done well, it's as simple as describing the end configuration for an app (generally and for the specific instance you're spinning up) and off it goes.
> If you abstract away the need to tag it and just have a function called logfiles() or something, you wouldn't even need to know this tag - your app could just write logs with some tag metadata, so when you go to process the logs, you figure out what it is after you've opened the logs.
If you look inside of any decently written application, you'll find that they use a centralized logging facility of some kind, which then demarcates the border between application and the running system. The app will provide a means of configuring its logging output to some extent, and then you're responsible for where it goes on the other side. Logs on disk, Event Viewer on windows, journald, or being sucked up into a logging pipeline like ELK, it's really up to the particular use case. Note that already, we're dealing with some pretty seriously different outputs; obviously this needs to be configured somewhere!
> Same for data, and ports, etc. Why should I have a Vagrantfile that maps ports? The app knows what ports it wants to offer.
Maybe the app does, but how should Vagrant / Docker / etc. know about this? The app could supply a Vagrantfile and a Dockerfile, but how does the app know what port I want open in reality into its own little port space? I may be doing something weird and not want the defaults for any number of reasons.
> We've had /etc/services for like 30 years and yet nobody seems to realize you can use a name instead of a port number and stop worrying about manually mapping numbers around.
/etc/services was almost never something you could rely on outside of the major protocols and if anything I'd prefer to just see it stop defining anything above 1024. It's kind of silly to think that there would only be ~64k different services in the world, now, but I suppose in the 70s it was more excusable.
> Honestly, so much of modern devops stuff is backwards.
There's backwardness, but I think some of it is in the way you're thinking about it. I don't mean to be insulting, but a really well managed CM environment absolutely does provide the majority of what you're asking for. It's not all out-of-the-box, maybe it could be, but that's sort of a pie in the sky way of thinking - "gee, what if all the app developers actually coordinated on something!" - yeah, might could work if everyone agreed to get over their own vision/ego and implement a common thing, but that's both unrealistic and also potentially stifling of innovation.
Devops is the job of surfing on top of the chaos and bringing as much order to it as you can so that when you inevitably burn out and leave the company, most of the good work you did has more momentum and inertia than it used to before we implemented common mechanisms of doing automation. Another Chef or Ansible devops guy can slot into your place, figure out the theme, and keep it going - even if it's not how they would have architected it from scratch. There's a hell of a lot of value in that.
All the non-Unixy targets are POSIX compliant so the majority of the basic functionality is the same. All the other stuff like package management will vary among distros anyway, so they can just add extra portability glue for more complicated functions.
The cloudformation designer is... Not terrible, but it's pretty bad. It requires lots of clicking and manual work for simple things and doesn't help you do the complex ones. It's a 1:1 visual representation of the generated json/yaml and it's easier to just write those directly.
To be really useful, it should have some kind of snippet options (insert a vpc with all the usual subnets, routing, etc in one go), or some "fill in the blanks" functionality.
If you have an AWS account, you can actually modify/fork the template on the fly by clicking on one of the objects in the diagram and editing its properties (which edits the YAML CloudFormation template in the background).
With a system based on plugins and components like Serverboards[1] its quite easy to create new functional areas (screens[2] in Serverboards parlance) as the ones you describe. Some times its more difficult to really round up the ideas to make something useful, than implementing it [2].
If you have specific ideas on how would you like a functionality like that to be, I'm all ears to make it real!
I haven't used it personally, but judging by the marketing video Tower is mostly an enterprise dashboard with some self-serve features that allow invocation of Ansible playbooks (or perhaps some larger unit of automation - I've no idea if they made something up just for Tower); but the playbooks would still need to be hand-coded elsewhere.
Ahh I thought you meant you got some playbooks/roles/modules written but you have a gui to say which are run where. More of a higher level.
But I think I see what you mean and I like the idea. A low level GUI that lets you look up specific tasks in ansible and have it create the playbook for you at the end.
That would be pretty cool and not that hard to write actually.
The terraform plugin for jetbrains products works really well. It auto completes all the resource types and knows what keys are valid under each one, so will suggest keys and highlight a resource as invalid if it’s missing a required key. I can’t imagine coding terraform plans without it.
If you're doing Puppet then the plugin for IntelliJ works pretty well with Puppet code, including reference checks and all the good stuff you'd expect from a half-decent IDE.
Can't say anything about Chef or Salt, but with Ansible you get basically shit for help since the IDE just sees a YAML file and nothing more. This is partially the fault of Ansible though, to be honest, modules being standalone scripts that is cool - but they provide no standardized way to inspect their parameters and outputs beyond documentation.
Ansible's modules documentation is auto-generated from the code. Hence, there is a standardized (across all ansible's modules) way to extract their parameters/outputs.
... and systemd timedated and systemd's idiosyncratic process #1 API. Its own doco also states that it targets systemd and does not implement use of other APIs.
You could bind the web service to the loopback interface of the server. This way it cannot be accessed directly from the internet. Then you can use SSH port forwarding to access it from the web browser on your local machine.
Add nginx/apache with client certificate authentication in front of this and most of those concerns go away. Plus this way you don't have to worry about exposing the port but you need to distribute your client keys before hand.
This looks really awesome but the thing that i feel is missing from the website is simply what is it capable of doing? Like I want a list of features that it is capable of so I can evaluate whether or not I may have use for it.
It could definitely be clearer, but if you click on the name of the operating systems on that page, they'll produce a little dialog that tells you how to run Cockpit.
I've just watched a presentation [0] linked by someone else in this thread and am quite impressed by the architecture and UX shown.
But it seems to me that Cockpit is more about monitoring and doing ad-hoc changes and not permanent configuration. I base that assumption on the fact that for example there are multiple places where one can configure network interfaces in debian and there is no cli tool or api to persist network configuration created with ip (at least to my knowledge). I can imagine parsing and editing fstab automatically and 100% correctly to be tricky too.
On the other hand enabling or disabling systemd services is permanent by default and there are probably more cli tools that automatically persist changes done through them.
Can anybody more familiar to Cockpit shed some light on the persistence of most of the configuration options?
Since I'm not familiar with networkmanager in combination with other config: what happens if I configure some network interface using Cockpit that is already defined in /etc/network/interfaces.d/*? Will it just throw an error or could it bring my system into a broken/undefined state so that it wouldn't be reachable after the next reboot?
If the latter is the case it would probably be unwise to install/use Cockpit on an already configured system.
If it's enabled, networkmanager will parse out the files and present them over dbus, nmcli, etc. Changes with nmcli, gnome-network (which also uses NM), or other tooling will update the config files. The same ones in /etc/network/interfaces.d/
NM/Cockpit will show all of this information. If you change the address to 192.168.40.113, the config file will be updated (but otherwise unchanged), and the address will change on the running interface.
If it's not enabled, Cockpit will not see the interfaces at all.
How to get recommendations for a software solution on HN:
1. Submit an Ask HN thread, and ask for advice.
2. Watch your thread get no response or interest from anybody.
3. Give up on HN and go build your own solution.
4. When it's ready, submit it to HN to help others in your situation.
5. The recommendations you were looking for will appear in the comments.
Haha, now I'm worried that this is going to happen to me. I'm looking for a production-ready Terraform/CloudWatch project for Rails + Sidekiq: https://news.ycombinator.com/item?id=16447092
If I can't find anything, I'm going to build it myself. (And I'm going to add Cockpit to my servers.)
Yeah, getting Webmin security right is possible but very challenging. Whenever I'm doing a security assessment at a client and I see traffic to/from servers on port 10000 I always make a note that there's probably some vulnerabilities there that our pentest guys will want to explore.
I have no idea if Cockpit is any more secure, but Webmin does have its fair share of security issues.
Personally, no, i don't want a webserver managing my servers. But i surely hope not the same mistakes or security issues arise that happened for webmin.
How's the open source version of mist.io these days? I remember evaluating it (and cockpit, among others) for managing a small isolated network of about two dozen machines in early 2017 and it seemed that the open source release had been somewhat ignored and wasn't really working at that point.
Note that all of my work is on networks that are disconnected from the internet, so I ignore SaaS offerings or versions completely.
I think it's worth a second try. We've been updating it quite regularly lately and we're about to release version 3.0.0 of the Community Edition, most likely next week. It introduces support for monitoring and alerting w/ Telegraf & InfluxDB, among other things. If you're anxious ( and somewhat brave ;) you can try installing it from the staging branch today.
Also, there's a Mist.io Enteprise Edition nowadays that you can install on-premises. There's more info about that at https://mist.io
Cockpit looks cool, but I'm using the new Jupyter Lab as a pretty awesome Python remote web shell. Access to a terminal, file explorer, and editor covers most everything I need and being able to run Python/Shell code in cells has covered most everything else.
Maybe I'm just missing something but where is the name of the package? How do I install this? Is it an `apt-get install cockpit`? I don't see that written anywhere obvious.
Yes. Assuming a debian-based distro, try "apt-cache search cockpit" and it comes right up. To see the available version try "apt-cache madison cockpit" which returns (on my Ubuntu 16.04 desktop) "cockpit | 161-1~ubuntu16.04.1 | ..."
I also had this question and it took me about 5 minutes to figure out that you needed to click to reveal. It's fancy, but not at all practical. Hopefully someone updates it to just a flat list.
'atomic' is a wrapper. Just look at the dockerfile.
Given how much cockpit wants to, y'know, manage the real system, running it in docker is senseless, and there's no reason to have it in the install guide. If you want it to actually manage your host, use the dockerfile.
For those who may wonder, it looks like this is GNU/Linux only, no support for BSD or any Linux distro that doesn't use systemd. That means no Alpine Linux and no OpenBSD/FreeBSD.
cockpit is not dependent on systemd. They don't ship sysvinit scripts, but there's no hard dependencies on systemd anywhere. I'd expect that the system logging may not be very nice without journald, but the vast majority of the interface runs over dbus or spawns processes on the server.
From their documentation, it certainly sounds like it is:
> Cockpit uses systemd and the DBus APIs it provides to configure and monitor core aspects of the system. Use of alternate system APIs are not currently implemented.
and
> Cockpit configures the system time and time zone via the timedated daemon. To perform similar tasks from the command line use the timedatectl command
Edit: Also please note that I'm not disparaging Cockpit nor systemd, just pointing out that (according to their documentation linked above) it is tied to systemd which may be an issue for some.
dubs means it will be linux only, maybe should write an agent that deals with dbus, meanwhile the agent can work with other OSes to provide info cockpit needs.
dbus-daemon works on BSDs too. There as a Linux-specific implementation of D-Bus called "dbus-broker", but that's an implementation of D-Bus, and Cockpit doesn't care about that at all.
dbus-broker is in fact more specific than that. It does not function on all Linux operating systems, only the systemd ones.
It too, like Cockpit here (as shown at https://news.ycombinator.com/item?id=16448768), talks directly to the idiosyncratic systemd process #1 API (rather than, say, using the "service" command to start services on demand).
I've noticed you're using jquery (and that's fine) so what is YOUR opinion about current state of js? Are you considering any js framework? And if so, which one would it be and why?
Cockpit itself is trying to be a "platform of sorts for modules to hook into. oVirt, for example, will install a cockpit plugin during installation of a hypervisor node allowing you to manage the local host or global cluster maintenance state and see how many VM's are running on the system (I would argue this is of limited benefit since you could just login to the oVirt Admin portal to do the same thing, but hey).
So, yes, you're right - a lot of work still needs to be done, but Cockpit itself seems to be an adequate base, just need to add support for managing commonly needed services at least at a rudimentary level though (MySQL/PostgreSQL, Apache/Nginx/lighttpd, Postfix/Dovecot/exim/cyrus, etc).
The real advantage of it is that it allows installation of hosted engine easily, and a 'single pane' overview of a host (oVirt Node status without using nodectl, etc)
Since Cockpit wants to deal with dbus, the push is for other utilities (postfix, snmpd, etc) to publish relevant information over dbus, rather than teaching Cockpit the format of each and every configuration file on the system.
I wrote the Tuned plugin for Cockpit, and I maintain the oVirt plugin. I gave a talk at Devconf about plugin development, which is extremely easy, but the Cockpit team is small. It's very easy to write plugins for it, but even easier if they expose dbus.
That said, the cockpit API (http://cockpit-project.org/guide/latest/api-base1) makes handling files/processes from client-side Javascript in plugins simple. It's just that you'd need yet another config file parser...
Never realized it was even possible to do a hosted engine deployment via Cockpit, that's certainly useful (I've always just used hosted-engine --deploy from the command line because that's how I've done it since the 3.x days).
Do you have a link to a video of the presentation?
It was a workshop, but no videos that I'm aware of.
It was essentially "here's how to use React to build a cockpit plugin from the ground up -- it's easy"
I'm a Python/Go backend developer, mostly, but Cockpit is easy enough that even I can write plugins for it. The workshop basically walked through the git tags in https://github.com/evol262/cockpit-boilerplate
cockpit-ovirt has a "Hosted Engine" tab which is an otopi parser. You'd find it to present exactly the same questions/options as "hosted-engine --deploy" in 4.0/4.1, with ansible and otopi deployments and a new UX in 4.2 which isn't a 1:1 representation of the questions asked.
Once Hosted Engine is deployed, the oVirt cockpit plugin can show the complete status of the HE cluster, put nodes into local maintenance, the whole cluster into maintenance, etc.
That's great. Before I tried cockpit I tried Kimchi which was also a sort of base for plugins, they had a libvirt plugin.
But it was far from finished and required a lot of work. I ended up having to go to the terminal to solve things a lot of the time.
So being a Fedora/RHEL fan I will definitely try cockpit with libvirt or ovirt and keep an eye on how it develops. But I also expect the same issues I saw with Kimchi, being forced back to the terminal to solve issues the gui can't do, or for some reason gets stuck on.
{kind=link}
[0] https://www.youtube.com/watch?v=Oq6Vbwl-HqM