Humourously enough, when I worked on a team that was writing a graphical web browser for mobile in the late 90's [1], they used a display list for rendering.
The reasoning was somewhat different, web pages were essentially static (we didn't do "DHTML"), if the page rendering process could generate an efficient display list, then the page source could be discarded, and only the display list needed to be held in memory, this rendering could then be pipelined with reading the page over the network, so the entire page was never in memory.
Full Disclosure: while I later wrote significant components of this browser (EcmaScript, WmlScript, SSL, WTLS, JPEG, PNG), the work I'm describing was entirely done by other people!
[1] - I joined in 97, the first public demo was at GSM World Congress Feb 98
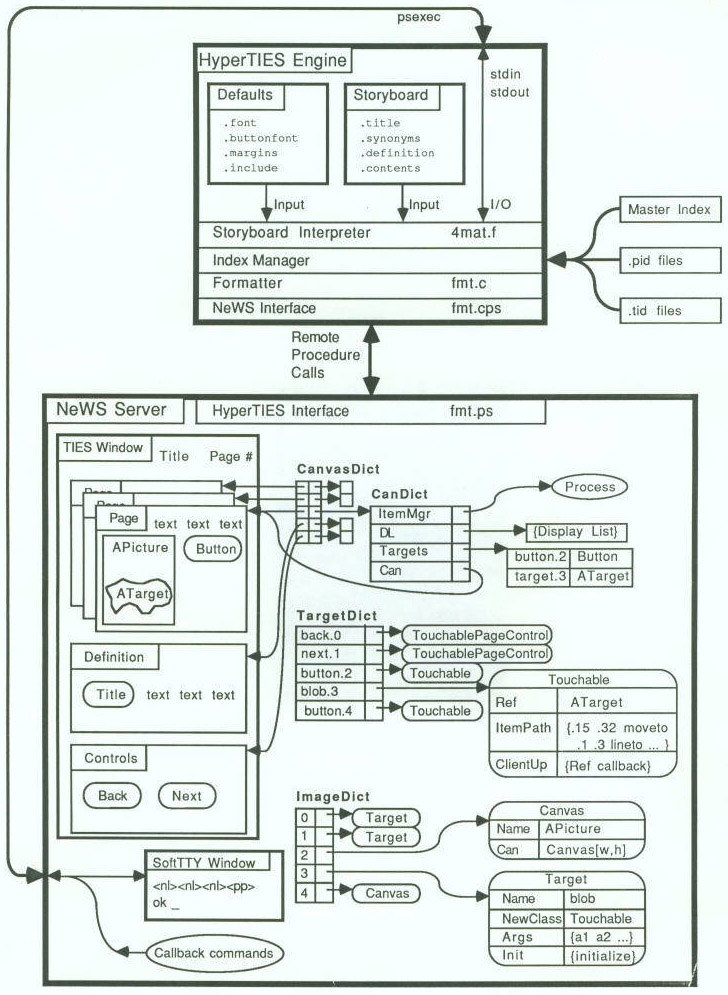
I developed a hypermedia browser called HyperTIES for NeWS that was scriptable in FORTH, and whose formatter could output FORTH code to layout and paginate an article for a particular screen size, which could be saved out in a binary FORTH image that you could restart quickly.
The FORTH code then downloaded PostScript code into the NeWS server, where it would be executed in the server to draw the page.
It even had an Emacs interface written in Mocklisp!
The company was STNC Ltd. The µbrowser was called Hitchhiker. STNC was acquired by Microsoft in July 99.
My understanding is that the demo at GSM World in 98 was the first time anyone had demonstrated a graphical browser on a cellphone that implemented common web standards (HTML/HTTP/TCP) rather than using a transcoding gateway (up.link or WAP style — the approach taken by Unwired Planet)
The smallest device that we targeted (IIRC) had a screen that was 100x64 pixels, we had 64KiB of RAM at runtime (`unsigned char gHeap[0x10000];`), and our ROM footprint was about 350KiB
Yup! That was the most limited device we ported to. I wasn’t even aware that it was officially shipped. Benefon made nice devices, the Q was really stylish for its time. If memory served they were mostly sold in Eastern Europe and Russia.
Now that this is closer to shipping, I'm curious what impact this would have on battery life. On the one hand, this is lighting up more silicon; on the other hand: a faster race to sleep, perhaps?
Have there been any measurements on what the end result is on a typical modern laptop?
Don’t know about measures. But eventually, after a couple stable FF versions are released with that new renderer, I’d expect positive impact.
GPUs are much more power efficient per FLOP. E.g. in my desktop PC, theoretical limit for the CPU is 32 FLOP/cycle * 4 cores * 3.2 GHz = 400 GFLOPS, for the GPU the theoretical limit is 2.3 TFLOPS. TDP for them is 84W CPU, 120W GPU.
A GPU has vast majority of transistors actually doing math, while in a CPU core, large percentage of these transistors are doing something else. Cache synchronization/invalidation, instructions reordering, branch prediction, indirect branch prediction (GPU has none of that), instruction fetch and decode (for GPU that’s shared between a group of cores who execute same instructions in lockstep).
Your browser is doing ~60fps rendering on the GPU already, it's just doing it much less efficiently. This does less work on the CPU _and_ less work on the GPU, for the same result.
I'll admit I'm certainly not an expert on browser rendering pipelines, but that's not the impression the article gave. Rather, it suggested that current browser engines may, in fact, be more efficient in terms of the absolute number of computations done.
When discussing existing browsers:
> But often the things on these layers didn’t change from frame to frame. For example, think of a traditional animation. The background doesn’t change, even if the characters in the foreground do. It’s a lot more efficient to keep that background layer around and just reuse it.
> So that’s what browsers did. They retained the layers. Then the browser could just repaint layers that had changed.
Then, later in the article, when discussing WebRender:
> What if we removed this boundary between painting and compositing and just went back to painting every pixel on every frame?
(Emphasis mine.)
So is WebRender less efficient in terms of power usage? Or is there some other factor that offsets the cost of this extra work?
> For the case where the CPU would have painted a single pixel, WR will certainly use a bit more power than CPU rendering with a compositor. For the case where a large portion of the screen changes, CPU renderers might miss their frame budget spending > 16ms drawing a frame, where WR will complete that task in 4ms.
> We might light up part of a GPU for longer than compositing would have, but we just saved >12ms of CPU compute. The power hypothesis is that the saved CPU compute consumes more power budget than the extra GPU compute we added. If there was no further JS code to run (app is idle) then we can go back to idle state after 4ms, instead of after 16+ms.
Hmm that sounds like outside of missed frames or otherwise busy sites consistently using more than 25% of the frame budget more power will be required by the new approach. Isn’t that going to be the most common case?
It depends. For a lot of web pages, the things webrender do are actually very simple and can be faster than Firefox's compositor even if there was no painting required. The expensive stuff like rasterizing glyphs are cached.
The idea is that if we can render everything at a cost that is equivalent to that of the compositor, then the benefits of the compositing infrastructure aren't clear anymore. For sure there will be pages where the compositor would have been faster for frames where no painting was required, at the end of the day it's a new architecture with new tradeoffs, but the goal is to be overall (much) faster.
I don't think this is actually true. If you're looking at a static page that doesn't change in any way, isn't the browser completely idle?
Edit: To clarify, I realize that the screen gets refreshed ~60 times per second (depending on refresh rate), but I don't think any rendering actually happens if it doesn't need to.
The GPU is still painting the screen at a set refresh rate (your monitor’s). Some monitors have variable refresh rates, but don’t go any lower than 30hz, and depending on settings like vsync the gpu might still be churning through hundreds of wasted frames. The latest iPads can go down to 24hz to save energy due to their custom 120hz display, but that’s a rarity.
Let's clarify, WebRender doesn't do anything at all if nothing changed. If the content of the window is static then webrender won't wake your gpu up until it really needs to. There seem to be a confusion about video games needing to render at constant frame rate, but that is only the case in games where there is always something changing on screen. It isn't that uncommon for other types of games with more static graphics to not render if nothing has changed.
What about if a tiny thing changes? Perhaps animated avatars totaling 1% of the page. Is that a scenario where the new method might use more power, because it redraws too much?
As pcwalton said, there is a whole lot of things on the web that are very cheap to render on a GPU if done right. For these things, a well tuned gpu renderer can easily outperform a naive compositor like what you can see in most browsers.
All of the caching optimizations that one gets from a compositor can be incorporated in something like webrender (and some are, like glyphs and a bunch of other stuff). Right now webrender doesn't have all of the tweaks to avoid rendering the whole page when there is a small spinning throbber, but that will be implemented eventually (there is still a lot of work going into rendering the long tail of weird and specific things right).
Actually, Gecko's compositor knows the screen space invalid region and scissors out the rest when compositing. The invalid region is passed to the window manager. Chromium also does that although they settle for an invalid rect instead of region which is fair. There is an issue on file to do the same with webrender.
In this use case the "painting" a compositor does from layers is copying one big rectangle. That takes next to zero time. That's not at all similar to "painting" where you actually re-render the entire visible portion of the page.
You don't see a notable difference between [tens of] thousands of glyphs and bits being layered on top of each other and processed through a display list, versus copying over one single rectangle from A to B?
In this case, the GPU just sends the content of the framebuffer to the screen. It does not re-render the content of the framebuffer, which is what the most energy is usually spent on.
Intel GPUs support Panel Self Refresh. Tablet and laptop panels can go very slow. Less than 24 FPS, for sure! It is whatever the low end is on their LCD controller (they forget over time, like DRAM).
It depends on the GPU arch. Some of them use a separate 2D compositor that uses much less power so if you're just scrolling layers you aren't lighting up the full GPU.
The GPU is drawing 60 times a second regardless of whether the page is static. Not sure how they do their streaming to the GPU, but there will be state changes every time you scroll, or click a button, etc., even on a static page.
There is a difference between drawing the frame into the frame buffer, and scanning the frame buffer out to the display. If you application is coded at all sanely, only the latter is happening at 60 Hz with a static page.
no, the GPU is refreshing the video output at 60Hz, the graphics are not being redrawn at 60Hz in your typical GUI application.
Games are a special case of course.
The specs for my mobile GPU say that it has 1024 cores. Wouldn't it be surprising if they were all fully active regardless of workload? (It seems like low-hanging fruit for making a laptop GPU energy efficient.)
Games eat a lot of power by rendering this way. So, definitely a concern, and I'd want to see benchmarks before switching from Safari on my macbook.
That said, GPUs are pretty clever about this. A big chunk of power consumption comes from IO. i.e., moving data from the GPU to the off-chip DRAM. Mobile GPUs optimize for static scenes where nothing is changing by keeping hashes of small blocks (say 32x32 pixels) of the frambuffer in on-chip memory. If the hash of a block hasn't changed, they don't bother re-writing that block into the framebuffer. But the GPU is still ends up running the shaders every frame.
I think you mean tile based rendering [1] - another huge plus of that architecture is the reduction of overdraw, where only the "most recent" write to certain block is effective.
I know it’s not officially released, so I’m hoping it gets fixed, but FF57 rips through my Mac’s battery life and runs insanely hot on simple JS apps. I still use it daily because it generally works, but there are a few apps I just have to go to Chrome for.
I think it's still in Nightly which is 58 now. I'm running 57 beta on Win10 and my about:support page says "unavailable by runtime: Build doesn't include WebRender".
The new improvements to Firefox fall under a project called "Quantum". Firefox 57 is merely the first Firefox release to have any Quantum components enabled, in particular Quantum CSS (a.k.a. Servo's CSS engine, Stylo) and Quantum Flow (which is a general umbrella project for making Firefox UI more responsive). Here are the others: https://wiki.mozilla.org/Quantum
57 does contain a number of faster things, just not specifically the work the article is talking about. Now that 57 is in beta, I’d imagine that the developer-focused blogs are talking about future things.
I suggest reporting a bug to Bugzilla. The positive side effect will be you will see how efficiently they handle such reports. And you will get it fixed.
I have the same issues on Linux. It's really fast, but often it hogs one core completely and the CPU does a lot of work, sending the fans in overdrive. Especially when videos are involved.
Let's hope things get ironed until a stable release in november
Mention Quantum Flow and "performance" in it. Make sure to attach a performance profile with https://perf-html.io/ using the linked add-on there.
I had many cases where the mozilla devs were glad about such bug reporst (especially if you are on Linux - I am too :) - which is not so often used and reported like Windows or Mac)
Despite the huge fans and heatsinks on modern desktop GPUs, I presume that a GPU would still use less energy than a CPU for the same workload, yes? Do mobile GPUs have a sleep mode comparable to mobile CPUs? Completely agreed that some measurements would be nice.
The Radeon Pro 560 on my MacBook Pro can draw "up to 75W". I don't know anything about how it manages power, but I do recall that Apple recommended in a WWDC session on writing energy-efficient apps that one should be careful to not trigger the discrete GPU when the integrated Intel GPU is sufficient. So that leads to another question: on my machine, which GPU would Webrender be using? I suppose I could find out experimentally, but I thought I'd ask in case someone here knows.
For WebRender, we targeted the integrated GPUs. You still need some logic to ensure you don't accidentally kick the discrete one into gear, but the integrated ones definitely have enough performance for almost anything WR will throw at it.
Could you elaborate the edge cases which fall beyond "almost anything WR will throw at it" ie what are the use cases where you would end up waking the discrete GPU?
Since the 15" MBP charger can deliver up to 87W, if you have full power draw on the MBP will you actually not be able to fully supply power over AC? I assume that the CPU also takes up around 20-30W.
But how much it can use gives you an upper limit on how much it will use. To boot, that also gives you an idea of how much power one can expect to draw under full load at any given time over any given time frame.
Power consumption is super-linear with clock speed. This means that in general splitting work from one core on to two cores running at half the speed will save power.
I would expect that in the long term, GPU rendering would be more efficient. In the short term the fact that the CPU is having to do a lot of work to manage the GPU may make it less efficient.
These UIs and Game engines typically burn CPU and GPU even for an idle menu on the screen.
I suspect that Mozilla will only re-render and composite on actual changes. Otherwise the power draw will be quite noticeable. The benefit of this new arch will be that they can guarantee 60 fps during that time.
WebRender is retained mode, not immediate mode. It will only repaint when repaint is needed, but if any repaint is needed, we will paint every pixel. There are CPU and GPU side caches for intermediate results like glyph atlases, so that doesn't necessarily mean we redo all the work every frame.
Just to give more perspective, invalidation is not free, and there are cases where invalidation itself takes longer than your frame budget. Also, in the case where you have to repaint everything or almost everything anyway, invalidation just made your problem worse since you spent cycles figuring out you can't skip any work.
Just tried it with the Nightly by setting gfx.webrender.enabled to true in about:config. Wow, that thing flies. It's seriously amazing. And so far no bugs or visual inconsistencies I could detect. Firefox is really making great progress on this front!
There's more steps necessary to enable WebRender in full capacity.
I presume, though, that things are buggier then and the potentially introduced performance drops might actually make it feel slower for now. I don't know, though, I haven't tested it with just gfx.webrender.enabled.
She is great at breaking down complex concepts into digestible and easily understandable pieces. Her whole Code Cartoons series is just plain awesome (https://code-cartoons.com/@linclark) and her conference talks are some of my all-time favorites!
If only it were as simple as just using Loop-Blinn. :) The technique described there will produce unacceptably bad antialiasing for body text. Loop-Blinn is fine if you want fast rendering with medium quality antialiasing, though. (Incidentally, it's better to just use supersampling or MLAA-style antialiasing with Loop-Blinn and not try to do the fancy shader-based AA described in that article.)
Additionally, the original Loop-Blinn technique uses a constrained Delaunay triangulation to produce the mesh, which is too expensive (O(n^3) IIRC) to compute in real time. You need a faster technique, which is really tricky because it has to preserve curves (splitting when convex hulls intersect) and deal with self-intersection. Most of the work in Pathfinder 2 has gone into optimizing this step. In practice people usually use the stencil buffer to compute the fill rule, which hurts performance as it effectively computes the winding number from scratch for each pixel.
The good news is that it's quite possible to render glyphs quickly and with excellent antialiasing on the GPU using other techniques. There's lots of miscellaneous engineering work to do, but I'm pretty confident in Pathfinder's approach these days.
I hadn't seen Pathfinder before; very cool! Especially if it's easily transferable to gpuweb, if and when that ships.
Reminds me of Mark Kilgard's old NV_path_rendering extension, which (as so often happened for interesting NV stuff) never made the jump to portability. One of its touted benefits as an in-driver implementation was the ability to share things like glyph caches between multiple apps with separate GL contexts, but with "apps" increasingly becoming "browser tabs", maybe a browser-managed cross-tab cache is almost as good.
BTW, is the WebGL demo available online anywhere, for people who don't want to install npm?
I'm very excited about your work on Pathfinder! I think great possibilities will open up once there is a way to efficiently rasterize vectors on the GPU.
Do you think, once the implementation is more complete, that it would make it possible to render fullscreen scenes of vector graphics (say in SVG) with hundreds of moving and morphing shapes on a mid-range phone/tablet/pc?
I know it's very difficult to predict these things, but I thought you may have already seen enough performance characteristics to make an educated guess :)
I noticed that Pathfinder went from calculating the intersection of beziers on the GPU with compute back to doing triangulation on the CPU. Any reason for this major switch in approach?
I assume you've seen other things like Slug, glyphy, etc., which use a combination of CPU pre-processing and GPU processing to make the bezier intersection as efficient as possible...
Because (1) compute requires newer hardware than what would be ideal; (2) compute cannot take advantage of early Z, which is critical for SVG (neither can Slug or GLyphy, by the way); (3) the two step process is hostile to batching.
Slug is asymptotically slower than Pathfinder at fragment shading; every new path on a scanline increases the work that has to be done for every pixel. (Of course, that's not to say Slug is always slower in practice; constant factors matter a lot!) GLyphy is an SDF approach based on arc segment approximation that does not do Bézier intersection at all.
> Loop-Blinn is fine if you want fast rendering with medium quality antialiasing
For example, when using SVG shape-rendering: optimizeSpeed ? I truly hope that SVG is going to be part of this new magic, and that the shape-rendering presentation attribute is utilized. I don't think current SVG implementations get much of a speed boost by optimizeSpeed.
Speaking of which, to what extent will SVG benefit from this massive rewrite?
Really cool work. Can't wait until we can give PathFinder a go in FF for text, and hopefully even SVG, :)
BTW, I see you implemented PathFinder in TypeScript as well. What do you think of it, especially since I assume a lot of your recent programming has been in Rust?
Well, it's only the demo that's in TypeScript. The demo is just a fancy UI that takes the Rust-produced vertex and index buffers and uploads them to the GPU for rendering. Ideally, I don't want to have to any code duplication between the Rust WebRender and Pathfinder demo code.
That said, Rust on the server and TypeScript on the client go really well together. Strong typing everywhere!
I'm not sure what you mean by "they" and "character" here. In general, the tessellation, whether it's constrained Delaunay triangulation or a Lorenzetto style trapezoidation as Pathfinder uses, needs only be done once per glyph and then can be reused for any size. However, note that both hinting and stem darkening for gamma correction distort the glyph outlines in a way that depends on the pixel size, so it's not quite that simple.
The name "WebRender" is unfortunate though. Things with a "Web" prefix - "Web Animations", "WebAssembly", "WebVR" - are typically cross-browser standards. This is just a new approach Firefox is using for rendering. It doesn't appear to be part of any standard.
I remember reading at some point that WebRender could actually be isolated relatively easily and then applied to basically any browser. That sort of already took place, going from Servo over into Gecko.
So, it might actually turn into somewhat of a pseudo-standard.
You send display lists to it over IPC, and it's easy enough to generate those from C++. It has a well defined API boundary, which makes it easy to use.
This is in stark contrast to the style engine in Servo which relies on memory representation to be fast. So integrating it requires very tight coupling of data structures.
Buggy graphics drivers are definitely a concern, not just for security but for stability. Specifically, graphics drivers crash. A lot. Simply moving GPU access to a separate process (which is common in modern browsers) means that a driver crash doesn't bring down any webpages, much less the whole browser; if done right you just get a flicker as the GPU process is restarted.
I'd largely forgotten what pixel shaders actually were, so it was nice to get a high level understanding through this article, especially with the drawings!
I was already extremely pleased with the Firefox Quantum beta, they really are stepping their game up. If this is truly as clean as they say it is, web browsing on cheap computers just got much smoother.
I really appreciate the time they are taking to describe the changes in an easy to understand way. The sketches and graphics really help explain a pretty complex subject.
Vulkan has been a consideration from the earliest architecturing steps done in WebRender. So, the internal pipelines are all set up to be mapped to Vulkan's pipelines.
It's actually OpenGL which fits less into the architecture, but it's still easier to just bundle WebRender's pipelines all together and then throw that into OpenGL.
They do, but we're targeting Intel HD quality graphics, not gaming-oriented NVIDIA and AMD GPUs.
That said, even Intel GPUs can often deal with large numbers of draw calls just fine. It's mobile where they become a real issue.
Aggressive batching is still important to take maximum advantage of parallelism. If you're switching shaders for every rect you draw, then you frequently lose to the CPU.
Speaking of batching, I look at this demo [1] on my mobile phone, and I can get ~3500 sprites without dropping below 60FPS.
A web page may not be able to reuse as much image data, I know. But smart game engines frequently look for ways to better batch sprites.
And technically speaking, if you're using a Z-buffer, you don't need to sort opaque layers at all. You can draw the layers in back and then draw more layers in front. Yes, you get overdraw in that case, but if you're using Z values for layering, you could potentially get better batches by drawing in arbitrary order (i.e., relying on Z-depth to enforce opaque object order), and in my experience larger batches gives you a bigger advantage than reducing overdraw.
Interestingly enough, I'm getting same result on Mac OS. Unless I hold in the mouse, I get about 2 fps. Seems like the same result on all canvas instances. I'll file a bug.
As far as I understand this, that demo will have no benefit whatsoever from the changes described in the article. Since it uses <canvas> with WebGL, it has always done all its rendering on the GPU in a videogame style way – in any version of any browser.
Correct. But the idea is that WebRender uses the same (general) techniques that a game-engine like this would use to make web page renders happen faster.
Safari obviously has some optimization’s being used. On my iPhone 7 it had no issues at all until around 60k. At that point adding new bunnies would slow it down but as soon as you stopped touching it would pop back up to 60fps.
I had to get to hundreds of thousands (maybe 250k?) and it started bouncing between 40 and 60.
I have a Thinkpad T40s with intel integrated graphics, it struggles playing games. I’ve had WebRender turned on for about a month; it generally works well modulo bugs, which all bleeding edge software has, of course.
> What if we stopped trying to guess what layers we need? What if we removed this boundary between painting and compositing and just went back to painting every pixel on every frame?
This feels a bit like cheating. Not all devices have a GPU. Would Firefox be slow on those devices?
Also, pages can become arbitrarily complicated. This means that an approach where compositing is used can still be faster in certain circumstances.
To address your second point, you seem to be saying that missing the frame budget once and then compositing the rest of the time would be better than missing the frame budget every time.
That is certainly true, but a) the cases where you can do everything as a compositor optimization are very few (transform and opacity mostly) so aside from a few fast paths you'd miss your frame budget all the time there too, and b) we have a lot of examples of web pages that are slow on CPU renderers and very fast on WebRender and very few examples of the opposite aside from constructed edge case benchmarks. Those we have found had solutions and I suspect the other cases will too.
As resolution and framerate scale, CPUs cannot keep up. GPUs are the only practical path forward.
> To address your second point, you seem to be saying that missing the frame budget once and then compositing the rest of the time would be better than missing the frame budget every time. That is certainly true
I'm not even sure. The frame rate is important for smoothness, but the regularity is also important : reading a video with at a consistent 30fps rate is more pleasant than running a 60fps animation and dropping a frame every 2 seconds.
Actually, virtually every device the average grade consumer uses, has a GPU. For instance, even Atom processors have GPUs. Granted, they don't have as much cores as a full-fledged nVidia GPU, nor as much dedicated memory, but they are still GPU with several tens of cores and specialized APIs that were designed specifically for the tasks at hand. Plus, they offload (ish) the CPU.
Something without a GPU: VirtualBox. Last time I tried a Servo nightly in VirtualBox (to be fair, a few months ago), it immediately crashed/aborted with a GPU-related error.
I think there's a good argument for preventing security-critical apps from raw GPU access, because graphics cards and drivers are a huge amount of attack surface.
I still think WebRender is the way forward, but I hope they get it working with something like llvmpipe.
While I understand the concern about security, I think it is beside the point. The surface attack is effectively the GPU and its driver, not the web renderer. The technique that are put in place by the web renderer are and were used by game engines.
If anything it'll push the GPU makers to have better drivers support.
EDIT: As for the no-GPU case, it is an edge-case, in which we could for example switch to the classical renderer. If you're running FF from a VM as your daily driver, there's something not right somewhere I think. (I'm thinking of C&C servers for satellites still running on WinXP and stuff)
> If you're running FF from a VM as your daily driver, there's something not right somewhere I think.
I am. QubesOS is a similar setup that runs applications in Xen VMs for security. I think you can do GPU passthrough but it's not recommended. At this point I don't think I would ever go back to running a browser "bare", even if there were no bugs, being able to have complete control over it (e.g. pausing, blocking network access, etc.) is a godsend.
I think the idea that "it'll push GPU makers to be secure" is weak. We're so far from that point it's not even on the horizon.
It certainly used to work fine with llvmpipe; I tested it when it first came out and it worked with no problems. Was pretty fast, too; it wasn't crippled by it though the stress tests (that do horribly in Firefox and Chrome) didn't do that well in it either (of course). This may have changed and broken it on llvmpipe.
In general we've not smoothed out this stuff so that you can fall back cleanly when a GPU doesn't exist.
There is a comment in this thread that explains this very well.
1) So the average CPU can do arroung several GFLOPS, the GPU however, even the integrated, can do some TFLOPS. S
2) CPUs have syncronization primitives, re-ordering, execution permissions, all sorts of besides the task ops they have to enforce. GPUs for the most part do not care about any of that.
From 1 and 2, you could spending 16ms classically rendering a web page, or spend 4ms rendering the page and 12ms on idle.
From an energy standpoint, it's the same if not arguably better. (I'm not an expert but I think for simple and over repetitive shaders and the batching implemented, it is actually logical)
> 1) So the average CPU can do arroung several GFLOPS
Maybe 15 years ago.
I think 200 - 1000 GFLOPs is common modern era CPU performance. A single core can do 32 floating point operations per clock cycle. Half that, if you don't count multiply accumulate as two ops. Drop another half if you want 64-bit floats.
To come back to my second point, let's say we make a webpage arbitrarily more complex. Where does the tipping point lie, where compositing would become more favorable (in terms of time and energy) than repainting everything on every frame?
Also, what (time and energy) savings could compositing bring if implemented on the GPU? (versus repainting everything on the GPU).
I addressed your first paragraph in another comment, but for the second one, compositing is currently on GPUs in most browsers. Layers are painted on the CPU and uploaded as textures to the GPU, which are then composited together. Manipulation of a few properties can be done cheaply in the compositor (modifying the layer transform or opacity for example). And that is assuming that you perfectly layerized, which is a heuristic process. You can find plenty of web dev articles about how to fix your CSS so that it layerizes propertly or how to avoid animations and transitions that can't be accelerated in the compositor.
Another savings (memory, time, unsure about energy) comes from not having to upload giant pixel buffers to the GPU.
I imagine the render task tree also has to determine which intermediate textures to keep in the texture cache, and which ones will likely need to be redone in the next frame. That kind of optimization has to be tricky.
With a compositor you're already drawing every pixel every frame on the GPU, whether it's just a cursor blinking or not. The WR approach basically only adds a negligible amount of vertex shading time.
IIRC GPUs already do a more efficient version of what you're proposing, at least the mobile ones, by using tile-based rendering. Thus only the general area of the screen that changes gets modified while the remainder is static. This way you can easily control how many GPU cores are actively changing and thus need power, while you keep the static state in the other cores and they consume negligible power.
I tried testing it out on a ThinkPad T61 to see how well it works with an older embedded GPU (Intel 965 Express), but I can't enable it (on Windows 10) because D3D11 compositing is disabled, it says D3D11_COMPOSITING: Blocklisted; failure code BLOCKLIST_
So does that mean that it is known not to work with that GPU? Can you override the blocklist to see what happens?
Edit: It also says:
> Direct2D: Blocked for your graphics driver version mismatch between registry and DLL.
and
> CP+[GFX1-]: Mismatched driver versions between the registry 8.15.10.2697 and DLL(s) 8.14.10.2697, reported.
Indeed that is correct, the driver is marked as version 8.15.10.2697 but the fileversion of the dlls are 8.14.10.2697, this seems to be intentional by Microsoft or Intel, note that the build numbers are still the same. Firefox is quite naive if it thinks it can just try to match those.
Take it from a Thinkpad X60 owner, the Intel GPUs from that era are absolute trash. They don't support OpenGL 3.0 on any platform (in fact, they didn't gain 3.0+ support until Sandy Bridge in 2011(!)) so don't expect any of this recent GPU-centric work (which seems to be targeting OpenGL 3.0+) to work on these GPUs. It would probably work just fine on the contemporary Radeon and GeForce cards since they support OpenGL 3.3.
While I would consider myself more a Golang fan than a Rust fan, I am impressed by the speed by which the Mozilla team is changing fundamental parts of their browser and somehow I believe rust has something to do with that speed.
I've been working professionally with Rust for a year now. When I got over the first wall, it has become the best tool I've had for creating backend applications. I have history with at least nine different languages during my professional career, but nothing comes close giving the confidence and ergonomics than the tools Rust ecosystem provides.
Firefox, especially the new Quantum version is awesome. But Rust as a side product might be the best thing Mozilla brought us. I'm truly thankful for that.
> nice! can you talk more about Rust's tooling? How do you debug? What IDE or text editor do you feel comfy with? Do you have/use/need autocomplete?
For writing code, I've been using IntelliJ with the Rust plugin for the past year.
Autocomplete works pretty well, there is Cargo integration so you can edit your dependency file in IntelliJ and things will automatically update so that autocomplete and documentation (go to definition) for the newly added dependencies start working immediately.
There is also simple build/check/run support, with build and test output appearing in the lower panel inside the IDE. There are some quirks, but they have been very minimal.
I've never used IntelliJ to debug Rust itself, because in most of the projects I've worked on, the Rust code has been designed as a completely separate library with a semi-public API, intended for embedding in another language like Swift or C#.
So the debugger has almost always been Visual Studio or Xcode, but it works exactly as I would expect even without using any sort of Rust plugin for either one.
The other day I was stepping through the call stack to find the source of a crash (one that I caused by failing to keep the P/Invoke signatures up to date with our Rust functions), and Visual Studio switched right from C# to Rust from one frame to the next, showing the source code and the line where the crash occurred in Rust.
Really I can't think of anything that has been even a moderately significant problem, it's been great all around.
While I mostly use Emacs and have only actually written a little bit of Rust, from what I've gathered the two best IDE experiences are either VSCode with RLS (Rust language server, which uses an adaptation of the compiler for reporting syntax errors and various other information like jump to definition, coupled with a simpler but faster engine for things like autocompletion so that you can start doing that before the server finishes a full compile) and the Rust IntelliJ Plugin which uses IntelliJ's native tooling and adapts it to understand Rust, which has the advantage of all being originally written for fast and robust autocompletion, highlighting, and the like, rather than adapting something written as a compiler to provide that information, but the disadvantage that you need to implement a lot of Rust's syntax and type inference so there are some more complicated cases that it can't necessarily handle yet.
If you're interested in trying out a Rust IDE, those are the two I'd try and see how you find them.
Probably not that complete, but getting better. I needed to write some of my own libraries, but for http server/client hyper[0] is fast and quite comfortable. It's getting a http2 support soon[1] and the ecosystem around the tokio[2] framework grows fast.
I need to do fast consuming and for Kafka the situation is quite good, for rabbitmq I have stuff that works but I needed to hack with a knife to get stuff working the way I wanted.
Everything's quite low level in the end and there hasn't been a task I couldn't solve either by myself or finding a library and doing a couple of pull requests to get things running. The hardest was to implement a working HTTP-ECE for web push notifications by reading and understanding all the RFC drafts, but the project[3] teached me a lot. Basically all my consumers deal with millions of events every hour, using 0.1 cpu's and about 50 megabytes of RAM. Uptimes reaching 2-3 months if I don't need to update the software.
Net/http is still less mature, but this an absolutey massive golang ecosystem. You can certainly write http clients and servers today.
Unicode, string processing, regex—all of these have performant, stable implementations, either in std or in crates. Recently i’ve been doing audio processing in rust; the code there is at least as good as the equivalent in go. Overall I’d say I haven’t had issues finding a package for something in a couple years, though the quality varies from “has a full support community” to “DIY if you need something”.
However, rust really shines with datastructures. Heap? Btree? Doubly linked lists? It’s all high quality, performant, and type-safe code (though the internals are unsafe as hell), which was my major pain point in go. Doing anything with a typed datastructure feels a lot like copy/paste coding in go, though apparently templates formalize this.
Can you tell me about your audio coding endeavours in Rust? Are you into writing VSTs or stuff?
I've been reading more and more about Rust and while I've fallen in love with its premises I still fail to tackle the real world task of starting to do stuff with it. Would you give me some pointers?
I work with Python and C professionally and have more than 15 years coding backend stuff for un*x systems, to give you some bg.
I haven’t played too much with VSTs beyond a proof of concept for logic tools. However I have been doing plenty of realtime processing! It’s great: it integrates seamlessly with the C ABI—I wrote my own core audio binding (though there is already on on crates) to get to know the API, and I was far more restricted by the poor documentation than the FFI itself.
But, rust has everything you need: find-grained control over memory and ownership, inline assembly and intrinsics (I haven’t attempted autovectorization yet), bindings to common audio formats, and excellent parallelization. The datastructures are extremely expressive, especially if you come from a C background; so far I really just want better VLA support, which is mostly annoying to work around (you have to manually poke the values into memory at the correct offset in an unsafe block).
I did find that tokio-rs wasn’t suitable as I had hoped for realtime work with an async/future api and fell back onto ringbufs locked with mutexes. The good news is you can wrap that in futures itself and have a great async api that does its work eith shared memory, minimizing the viable races.
Rust will definitely be a player in the audio workstation world; right now you’ll be implementing the bindings yourself, but you can go out and write plugins today so long as the ABI is C.
Will there finally be a unified use of the GPU on all platforms (win, mac, linux, etc) or will WebRender just be a Windows only feature for quite some time?
I have WebRender working on Linux with Intel 5500 integrated graphics. Hardware acceleration is still a bit glitchy though I'm afraid (with or without WebRender).
To enable, toggle 'layers.acceleration.force-enabled' as well as 'gfx.webrender.enabled'
edit: It's also working through my Nvidia 950m (through bumblebee), although subjectively it seems to have a little more lag this way.
Why are they so obsessed with 60 fps? 120 fps looks considerably better, and there are other effects like smear and judder that significantly decrease even with significantly higher frame rates, say 480 fps [1].
The WebRender folks are well aware that higher framerates are the future. Here's a tweet from Jack Moffitt today, a Servo engineer (and Servo's technical lead, I believe): https://twitter.com/metajack/status/917784559143522306
"People talk about 60fps like it's the end game, but VR needs 90fps, and Apple is at 120. Resolution also increasing. GPUs are the only way. Servo can't just speed up today's web for today's machines. We have to build scalable solutions that can solve tomorrow's problems."
As everyone said, 60fps is not the destination but merely a waypoint. It's a good goal, considering 99% of screens that are in use today refresh at 60 Hz or their regional equivalent. Higher refresh rates are next.
Not an expert, but I feel that that was more of an analogy/image to give what they were aiming for. The real objective is not 60fps, the real objective is to use the GPU to do tasks that it was designed for. Plain and simple. This however, gives the user a smoother experience, and 60 fps generally gives a noticeable difference.
We're not as other people have said in other comments. On normal content you can often see WebRender hit 200+ fps if you don't lock it to the frame rate. To see this for yourself, run Servo on something with -Z wr-stats which will show you a performance overlay.
I don't think, they are obsessed with 60 FPS, that's just what for most people is synonymous to a smooth experience and is often not met by browsers at this point in time.
In the video, he says 500 FPS, but assuming there's no more complicated formula behind this, I think it would actually be 2174 FPS. (0.46 ms GPU time per frame -> 1/0.00046s = 2173.913 FPS)
We specifically target integrated GPUs, and several of the main developers work on linux using Intel GPUs with open source drivers. There's every reason to think this will be amazing on Linux.
On Ubuntu 16.4 LTS, I just now installed rust nightly[1], and pathfinder[2], and the three demos appear to work in the default firefox 56, but not in chromium 61.0.3163.100[3]. Disk usage was half GB, split between ~/.cargo and pathfinder/ . Time was... less than a snack. My GPU was integrated Intel HD 520. I already had npm 3.10.3.
I have it enabled on one of my Firefox profiles. Would not yet recommend for normal browsing, there's still rendering errors and sometimes seemingly random performance drops, but you can definitely see it working.
That is, I have to be lucky for this benchmark [1] to not crash my "regular" Firefox Nightly.
With WebRender on the other hand, the benchmark becomes entirely unimpressive, as if you were just playing a pre-rendered video.
My system has an Intel i5-3220M with HD Graphics 4000 (was midrange for a laptop in 2012) and 4GiB RAM. OS is openSUSE Tumbleweed with a KDE Plasma + bspwm combination as desktop environment, so no desktop compositor (no idea if that makes a difference).
Nicely done article, but please please stop using analogous terms like quantum, rocket, atoms, jet, etc... These terms actually means something in the real world. Working in the limbo between web dev and science exacerbates how silly this is. Find your own terms please.
Just tried it on iMac 27" late 2015, High Sierra, latest nightly with WebRender enabled. Went to https://codepen.io. Froze the screen for 30-40 seconds, then just black. Had to hard reset.
I don't think it would help WebVR (maybe in the future rendering DOM as textures, but it'd be limited to only 2D), but today WebVR applications goes through a different pipeline, running purely on WebGL.
Some of us are running alternate WebVR stacks. :) On a Vive, playing with the 3D demo, it looks like I'm getting ~50 minimally-readable lines of text, with no motion, and no lens correction (integrated graphics). Should be ~80ish with corrected chromatic aberration. Which is pretty good for the low-angular-resolution and PenTile Vive. It's comparable to the usual hand-tuned pixel fonts rendered flat (part of that is PenTile pain).
Anyone know if they used any specific tools for the graphs/figures? They remind me of XKCD style graphs, really like those for technical yet informal explanations!
This is great! I'm really impressed by the technical achievement, and hope everyone takes lessons from it to put performance and FPS at the forefront of their concerns when developing applications.
Sadly, seeing the state of the industry, people will just use this as an excuse to continue write more and more sloppy code that would perform terrible even on the newest and faster WebRender version.
In other words, this version might run current websites at 60 fps. But wait a few years, and it will become the norm that a lot of websites render at 10fps or less.
There should also be a way to punish developers who fail to run their sites at 60fps on WebRender, similar to how browsers will start to punish sites that run without https.
For example, if a site fails to run at 60fps for a few seconds, show some kind of alarm on the address bar that this site is very slow and might crash the browser.
No, not "crash the browser" (coz browsers are not supposed to crash no matter the site's content), but that "this site might drain your battery quickly" or something along those lines.
{kind=link}
{kind=link}
The reasoning was somewhat different, web pages were essentially static (we didn't do "DHTML"), if the page rendering process could generate an efficient display list, then the page source could be discarded, and only the display list needed to be held in memory, this rendering could then be pipelined with reading the page over the network, so the entire page was never in memory.
Full Disclosure: while I later wrote significant components of this browser (EcmaScript, WmlScript, SSL, WTLS, JPEG, PNG), the work I'm describing was entirely done by other people!
[1] - I joined in 97, the first public demo was at GSM World Congress Feb 98