This looks like a solid if not amazing comeback of AMD into the server market. Sure, single threaded performance may not beat Skylake-SP, nor will the LINPACK (and most wide SIMD/FMA-heavy works) performance, but that still leaves most of the HPC/engineering applications that either do not have workload that lends itself to heavy vectorization or are simply not tuned for it (and won't be overnight).
All in all, whhen you have a server that seems so close in performance to Intel for less money and consuming less power, I can't imagine that EPYC won't see broad adoption and Intel won't be squeezed.
I'm glad AMD is back and there is renewed competition in the server market!
Not to mention AMD has a very clear Roadmap for Zen IPC as well as node. Compared to Intel which has been delay after delay or rename. There will be Zen+ next year on 7nm, and 7nm+ in 2019. Not sure if they are the same on Server, but they are suppose to fit in the same socket on Desktop.
Good point, it looks like they have a decent path forward and hopefully they take good advantage of the new nodes and the available room for refining the uarch.
Socket compatibility would be wise, I hope at least the Zen+
I'm hoping they soon get back to competing aggressively at high-end HPC too, perhaps they could spend some area on Zen+ on better FP SIMD, or even flexible width SIMD (though the latter would be more realistic on the 7nm successor).
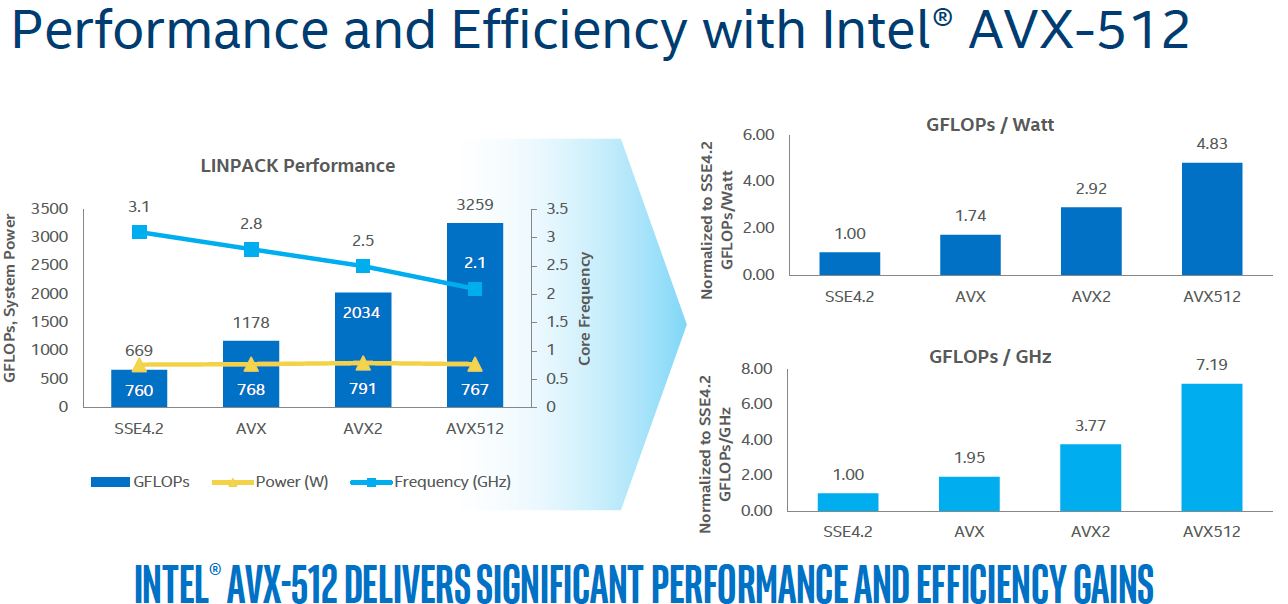
It will take some time until that question can be answered. For some it will likely matter a lot, e.g. engineering or HPC applications that rely heavily on dense solvers. however, even for non FP-heavy workloads (like integer-heavy stuff say databases) the wider SIMD with the new mask and blend instructions [1] _could_ make a significant difference. Still, in many cases significant difference will likely be seen only after careful tuning!
Also note that Intel is refining their pesky market segmentation game: the full 2x 512-bit FMA/cycle is only available on high-end CPUs, only lower-end it's only 1 FMA/cycle and you still get the extra AVX512 clock throttle hit [2]!
I really like the fact that AMD stayed away from such devil-in-the-details feature-based market segmentation!
Wide availability of an ISA creates the economic opportunity for people to hand tune / optimize for it. I wonder if Intel is shooting themselves in the foot by creating instructions that are available only in a tiny fraction of shipping CPUs. AMD would have had a much harder time with Ryzen if AVX 512 was shipping in volume on a bulk of the chips and if a wide variety of software had been written to exploit it.
Depends on the size. Sure AVX512 is great until either A) you thermally throttle or B) you cache miss. Keep in mind that AMD has 8 memory channels vs Intel's 6. So if you need to hit main memory (randomly or sequentially), AMD has a decent edge.
HPC and scientific computing are quite small niches of the server market though. The database, java etc benchmarks are more important in making or breaking it as a commerical product.
Sure, but I was addressing the areas where the Zen arch is clearly not beating Intel. Database, java, etc. are areas where the initial benchmarks indicate that EPYC is quite competitive.
But the article states that they didn't have enough time to tune (they had the chip for just a week compared to 2 weeks for Intel) and a more detailed look is forthcoming from Anandtech, so it might be wise to wait for that.
1. The mesh interconnect looks like a big loser for the smaller parts. It's a big jump up in complexity (there's an academic paper floating around which describes the guts of an early-stage version) and seems to be a power and performance drain. I can't imagine they got the clock speeds they wanted out of it. Sure, it's probably necessary for the high-core-count SKUs, but the ring bus probably would have done a lot better for the smaller ones.
2. There's almost nothing in here for high-end workstations (which typically have launched with the server parts). Sure, AMD has Threadripper coming soon, but this looks like Intel's full lineup... so where are the parts? We've bought plenty of Xeon E5-1650s and 1660s around here, and it doesn't look like there's anything here to replace them. That's unexpected. The "Gold 5122" (ugh what a silly name) is comparable, but at $1221 is priced just about double what an E5-1650v4 runs.
Workstations are a bit of an interesting case because their loads look a lot more like a "gaming desktop" than a server: a few cores loaded most of the time with occasional bursts of high-thread-count loads. That typically favors big caches, fewer cores, and aggressive clock boosting. If you're only running max thread count every now and then, you can afford a huge frequency hit when you do. But since these are business systems we try to avoid anything that doesn't say "Xeon" on it (or "Opteron", in years past) as reliability is paramount. To see nothing here from Intel in this launch is discouraging, to say the least. I have an upgrade budget and it looks like it'll be heading nVidia's way at this point.
> 2. There's almost nothing in here for high-end workstations (which typically have launched with the server parts). Sure, AMD has Threadripper coming soon, but this looks like Intel's full lineup... so where are the parts?
Wasn't that launched last month with LGA 2066, http://www.anandtech.com/show/11550/the-intel-skylakex-revie...? Sure, those do not wear the Xeon name, but that platform has cpus that are comparable to Xeon E5-1650 and 1660s. And there are additional cpus with higher core count announced.
That line doesn't support ECC though, so it's a pretty poor choice for a production workstation. And the LGA2066 platform has power delivery and thermal issues [1], likely due to the launch getting pushed up and mainboard vendors not having enough time to get things right. Gaming customers can tolerate a bit of flakiness from their systems, but Intel's enterprise (i.e., Xeon) customers will scream bloody murder if Skylake-SP launches in anywhere near as bad a state as Skylake-X did.
> 1. The mesh interconnect looks like a big loser for the smaller parts. It's a big jump up in complexity (there's an academic paper floating around which describes the guts of an early-stage version) and seems to be a power and performance drain.
Indeed surprising given that they had a few years to learn from the KNL experience.
Got a link to that paper?
> I have an upgrade budget and it looks like it'll be heading nVidia's way at this point.
Just for curiosity: what workload allows you to go with NVIDIA instead of Intel (rather than AMD)?
The mesh is described in a bit more detail in Anandtech's previous article [1]. The figures are directly from the paper they cite [2], which is available on SciHub. I admit to not reading it in detail, only looking at the figures, but I'm amazed that with as many redrivers and repeaters as they have, they can only hit 2.4GHz on the mesh (as quoted on page 7 of this article). That thing has got to be dragging the whole architecture down.
> Just for curiosity: what workload allows you to go with NVIDIA instead of Intel (rather than AMD)?
The particular workload I'm thinking of is Abaqus FEA. Per-core licensing is a part of that, but it's starved for double-precision (FP64) FLOPS and thus runs great on an appropriate Tesla. We have a number of K40s (which last I looked was the best workstation FP64 Tesla) for that exact reason. And they cost less than a single "Gold 6154" Xeon that the sibling comment (rightly) singles out for good single-thread performance. Throw in Abaqus's horrid per-CPU-core licensing and it's a no-brainer. Intel is just charging too much money for anything launched today to be viable in a workstation.
Ugh, per-core licensing is pita. Tell the decision-maker at your work to pay for the cores or switch to some code with more sensible pricing model. Do the alternatives (like Ansys) charge per core as well?
Unfortunately, Abaqus is required for the work we do. According to our senior ME, it has the best contact surface handling and therefore is the only software that's suitable for our types of models. (I don't have much more detail to add, as I don't actually work on our FEA stuff. I just get to advise, as the EE who knows computers inside and out.)
Looks like the Xeon Gold 6154 will make for a reasonable per-core performance workstation chip. Unfortunately it looks like it probably won't be overclockable though.
A nitpick regarding the comment on the 8XXX series which is targeted pretty much only for 8 socket systems (or 4 in non-fully populated configs).
> This pricing seems crazy, but it is worth pointing out a couple of things. The companies that buy these parts, namely the big HPC clients, do not pay these prices.
We in HPC would not touch these outside big memory systems which is even niche for us. The consumers of these are far more likely to be those with data warehouse style needs (a.k.a Oracle customers).
Much like the rest of the world 2 socket systems in HPC are by far the most common.
Looks like die-to-die latency isn't all that great on EPYC, as expected:
"What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches."
Also:
"AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations."
I was kind of expecting this, but it's still disappointing to see. Looks like if you need a lot of L3, Intel is still the best/only option. Not to say that AMD hasn't made massive improvements though - and it's also worth noting that while AMD's memory latency is generally worse, throughput is also typically better than Intel.
This is extremely workload-dependent. If you have a lot of processes and they have good affinity, you don't mind that the L3 is organized like it is on the AMD chip. On the other hand, single threaded workloads suffer, as do applications with lots of threads that move around a lot.
I'm curious to hear from AMD about the L3 cache latency issue. The article shows L3 access just a few ns quicker than going to DRAM, even to the other CCX on the same die. That's ugly!
This strikes me as either a bug or a benchmarking glitch, though other benchmarks seem to imply that the situation is real.
Assuming it's legit, this gives AMD a great opportunity for a boost in their first respin of the 8C/16T die.
The L3 issue isn't quite that simple. Sure if your dataset fits in Intel's L3 that's great. Problem is that a single shared L3 (for the same amount of effort/transistors) has much lower bandwidth than smaller separate L3s.
So a dual socket AMD has 8 zeppelin chips and 16 8MB L3 caches. I'd be quite surprised if intel could match the bandwidth of those 16 L3 caches. Additionally if there is enough cache misses AMD has a 33% advantage in both outstanding memory references (16 at a time in a dual socket) and bandwidth.
Basically both architectures are HUGELY complicated. Even minor things like which compiler/which compiler flags can make a big difference. Now more than ever it's important to benchmark your workload, any simple rule of thumb is likely to be useless.
EPYC sure does look good on paper. But the big question in my mind is how will OEMs react to it. Will it be offered on equal footing in actual server systems from major brands (HP, Dell etc)? Most people won't be buying CPUs by themselves, so the list prices are mostly moot point. I do seem to recall that K8-era Opterons didn't do as well on the market as they could have been based on the HW alone. I fear we might see a reprise of that play again.
One difference this time around is that AMD can make a good business just selling to Apple(servers), Facebook, AWS, GCP and Azure. As long as they hit their use cases they can create a good, sustainable revenue base. They also have a semi-custom division for tailoring their offerings, which the big cloud providers would definitely expect at the volumes they purchase in. Also, it's a good tool for them to use as leverage when negotiating with Intel.
> a good business just selling to Apple(servers), Facebook, AWS, GCP and Azure
How can other clients get in on this? My CS department (UK university) is wanting to replace servers (and extend ML capacity) and I've been making them wait until AMD availability becomes clearer (but I can only do that for so long...).
There's definitely a market here - if anyone from AMD happens to be reading this and would like to demo... though I'm not sure our volume would be quite the same scale as the above.
You are (like us) most likely too small. Unless you are buying 1,000 machines at a time you don't get there :(
Waiting one more quarter for AMD servers to arrive from the major vendors is a good idea. But if your spend is in the millions then you can probably get the contracts (if needed for budget rules) and test systems now, especially if you ask the cluster builders.
If you can't buy them from your favorite vendor, look around and buy from whoever's selling them -- I see that SuperMicro says they're selling AMD EPYC servers. If your deal is big enough, any SuperMicro distributor can lend you a machine to test on.
Why not talk to OEM's? Many have been running benchmarks for some time and surely have an idea about performance -- though one important question is whether that "idea" is biased or not.
I believe Lisa Su's email is lisa.su at amds website. You should try writing her an email. She's from an academic background and may be willing to do something. Unlikely to work, but if you never ask the answer is always no.
There are some interesting numbers there on the "memory subsystem: bandwidth" page. Basically Skylake-SP has a pretty low single thread bandwidth (12G/sec) to start with, that is just 40% of what you can get using a single pinned thread on Epyc, but it increases almost linearly when you have more threads.
Wondering other than some sparse matrix applications known to be memory bandwidth bound, what kind of performance impact this is going to cause. Is there any real memory bandwidth bound applications other than ML/AI stuff used by those Internet big names?
Many if not most HPC/sci. comp applications are memory bound (or actually their implementations are). [ref missing, but google around and you'll find plenty]
More and more applications are drifting into the memory-bound regime, especially with the wider SIMD instruction sets increasing arithmetic throughput while memory throughput lags behind.
My back-of-the-envelope calculation (with a guesstimated AVX512 clock) gives a 12 FLOPS/byte for a big Skylake chip like the 8176 while this was around 9 FLOPS/byte for Broadwell. I'm not entirely sure about the instruction throughput of Zen, but it looks like the 7601 should be around 4-5 FLOPS/byte (that's worst-case with mixed FMA+ADD workload based checked Agner F's manual [1] IIUC).
Of course this does not consider NUMA and other effects, but given the above a lot of applications will benefit from the great bandwidth advantage of EPYC.
"With the double DRAM supported parts, the 30% premium seems rather high. We were told from Intel that ‘only 0.5% of the market actually uses those quad ranked and LR DRAMs’, although that more answers the fact that the base support is 768GB, not that the 1.5GB parts have an extra premium."
AFAIK, GitLab's server proposal included them. They will probably not use 128GB TSV LR-DIMMs immediately though. I think the price gap between 32GB RDIMMs and 64GB LR-DIMMs are falling right now right?
What's the bottom line for someone like me building simple cloud applications without specific hardware requirements? I tend to look at CPUs as black boxes. Will my Digital Ocean / Linode / whatever VMs soon have a better price-performance ratio?
{kind=link}
All in all, whhen you have a server that seems so close in performance to Intel for less money and consuming less power, I can't imagine that EPYC won't see broad adoption and Intel won't be squeezed.
I'm glad AMD is back and there is renewed competition in the server market!