I've some experience in visual programming languages (both professional and in my studies) and I advise against the graph-form where you connect nodes and edges.
This does not mean that text is the only way to implement programs (and even if you connect nodes, you're still programming), but maybe a good local optimum is in-between, e.g. interactive shells like Jupyter's Notebook and the Mathematica interface. I know there is LabView, the Blender-Editor and AFAIK some Unreal-Engine tool that uses this model, but bigger programs seem really incomprehensible to me.
It's always easy to show-case 5 programs in these node-&-edge editors, but I do not think it is the best approach for visual languages, as one should not under-estimate the layout problems and how to represent information in boxes.
So, I am all for new ideas in visual programming, but I am not sure if the "free canvas" approach works.
I don't think you remember how the yahoo pipes worked. It was a brilliant mix of graphs for flow control, premade boxes for all common data manipulation and scripting for that extra feature if needed
I miss them a lot and appreciate the effort here, but don't forget the visual model for data manipulation wasn't invented here but was testsd refined and proved functional by previous existing services
> It was a brilliant mix of graphs for flow control, premade boxes for all common data manipulation and scripting for that extra feature if needed
I work for a startup that builds a dataflow app platform that fits that description nicely. We support gathering data from databases, files, APIs, etc., full graph-based flow control, strong .NET types on everything, tons of premade boxes for common operations, and support for C#/Python/R/F#/VB for custom data manipulation. Here's a quick example dataflow: http://blog.composableanalytics.com/2016/09/25/querying-data...
> I don't think you remember how the yahoo pipes worked.
True, I learned about it when it was already dead, but thought the goal was similar to the stuff Zapier offers and I would really like to try it. Not to automate stuff, but to checkout the visual editor.
The pipes goal was to transform data upon a pull, not move data on triggers. The client was likely a reader, while those event system mainly push to api.
Funny you say that -- engineers are one of Zapier's best customer personas. Quicker and easier to implement functionality than deploying code to the cloud. Plus, non-engineers can take over maintenance so engineers can work on more interesting things.
"Patch and wire" can work in certain contexts, especially for data flow models. You are right they don't scale well (Burnett's scaling up problem), but if the programs are relatively small, they are completely manageable. And it does force you to keep your components relatively small and simple (using compounds to hide wiring for more complex designs).
IMO, the reason the wiring model doesn't scale up is that most don't provide a way to create submodules (compounds?). I expect that decomposing a problem into a chain of smaller subproblems is a fine way to manage a dataflow.
Yahoo Pipes didn't really offer that, or any anyonymous stdin/stdout. So huge graphs were necessary for complex problems.
I agree that it is difficult to tackle bigger problems with this model, and everything that deviates from rss in -> manipulation -> rss out is maybe better served with textual programming. Though I did use pipes in a ruby program of mine basically as micro service for everything web related, shortly before it got turned off...
But Yahoo Pipes did have submodules. You could have one of your pipes as a block in another pipe (I'm planning on supporting that at a later stage). And it had userinput that could get assigned as additional input to blocks in a pipe (for that I don't have a mental model yet).
Checkout Rapidminer and Knime for great examples of box'n'arrows applied to machine learning pipelines. I've used Rapidminer a fair bit and they really have a great model including a dynamic number of inputs/outputs from a single box and ability to make boxes that encapsulate pipelines made from other boxes. I was able to do an order of magnitude more experimentation using this visual style than if I had tried to script it in code. I'm a software engineer who loves to program so the fact that I'd pick this tool for that job over programming I think says something.
For a more stable, and more business analyst friendly tool, check out Alteryx. It's not open source, but is powerful, stable, and has SDKs in multiple languages.
It only had submodules in the sense that you could embed a pipe, but IIRC, they were always sources -- you couldn't pipe data into them. It had a notion of the 'output' block but no input with which you could implement such decomposition.
I think I have the same opinion, but express it as: words (i.e. text) can represent or reference anything. They can reference modules. Trying to do this with lines becomes messy quickly.
OTOH unix-style pipes (also used in jq), shpuld be even more limited, being only a tree. They can get too complex, and then you use files as a way to implement modules (in a sense). So pipes have their place.
> I expect that decomposing a problem into a chain of smaller subproblems is a fine way to manage a dataflow.
It is, which is why basically all graphical modelling techniques used for system analysis use it. An executable diagram system that doesn't leverage the experience of system analysis diagrams seems somewhat poorly considered.
I work for SnapLogic (an enterprise visual integration product) - the "free canvas" works great for us with live preview of results/data; here's an example linking a third-party code review tool's webhooks with JIRA: https://i.imgur.com/gNr1gGD.png
All of our integrations can be converted into a API with a click of a button too.
I work at a sort-of-competitor to you guys (honestly not sure we cater to the same user bases or not) but I actually like your UX. It's quite sleek. At Alteryx, we have a more traditional Node/Edge model, which probably occupies less screen real estate than your UX does for the same pipeline. However, it would be interesting to study if it's easier for humans to cognitively process a given style.
The line of products you and I work in have shown me just how much research we still need to do on human processing of visual charts. UX professionals are just way behind on this across the industry IMHO. We've got some great ones here, but it's not easy finding them.
The image shows some of the problems quite well. E.g. the following things are not clear to me:
[0] I suppose Rhombi symbolize choice. But where are the branches? What if "Already Done" is true? Or does the else-branch enforce implicit fail-state somehow?
[1] What's the difference between parallelograms and squares?
[2] What's the scope of the "For Each Issue"?
[3] Why is the second output of "Copy Webhook" named ("output1"), but not the others? Are they implicit default output (maybe "output0")?
[4] What happens with longer pipelines? Do you wrap or have a scrollbar?
Furthermore the size of the modules have same size, so one gets into rendering issues (e.g. the names of some nodes don't fit the "boxes"). Sorry, I didn't want to sound harsh, I just think that visual programming is not automatically simpler, just because it doesn't use text (at least directly - one has also to name "modules"). You also don't use the "free-canvas" in its extreme form I described (where you can rearrange everything), as you've e.g. implicit edges between nodes, which is a good idea probably, as users get a feeling about the complexity of pipelines by measuring their length (which would not work if there are different lengths for edges).
[0] Kind of. It's a filter, so "false" means "do not advance". We have different Snaps for If-Else (the Snap would have 2+ outputs and you would route to a respective "branch" of the pipeline)
[1] They denote different categories - parallelogram = READ (i.e fetch data from somewhere), square = Transform (modify existing data)
[2] For Each Issue - for each object in the specific, targeted array of incoming JSON object... (basically split the array chosen)
[3] Correct
[4] You can adjust the rotation of each output, so it could snake around. You also can drag the output of one to the input of another that are not side-by-side and it will mark them as connected, so you have layout in any way. Finally, you could split up into separate pipelines and use another Snap to tie them together.
I don't think you are being harsh - I'm not sure there is any way for a visual programming language to be both powerful enough to permit massive customizations and concise enough to be immediately readable. Some level of interpretation has to be done.
A web endpoint. So think of an HTTP endpoint where the request body gets turned into the input data and the query parameters become available to be used/mapped anywhere in the pipeline. It makes the integrations pretty dynamic.
Compared to putting together the net list of even a mildly interesting digital circuit interactively this is actually really easy. Not as easy as doing it with a text editor and some programming language or scripting solution would be but I think that Y! pipes was never aimed at the developers, much more at ordinary users and those are much more comfortable with such visual solutions than they are with text.
There are some successful commercial products that use a visual graph model. MaxMSP [1] and Shake [2] (now discontinued) come to mind. You're right that it doesn't scale well as a UI, however.
Unreal Engine 4 Blueprints are amazing from what I've seen, and show what a good visual editor can be capable of. LabVIEW is a PITA in my experience. That being said I have not invested very much time in LabVIEW but I have no motivation to either. I don't mean to flame, that's not the intention, but does anyone on HN actually think that LabVIEW is a comfortable and productive tool? If so, how and why?
I used it for 6 years controlling a complex experimental apparatus for some physics experiments.
It's great at getting out of your way and letting you focus on the results. It's definitely not a typical programming language.
It's great for integrating off the shelf stuff from any major test equipment company. Flow a couple lines and boxes and you've got a PID circuit. Add a few more and you've got a real time oscilloscope. Add a few more and you have data logging. At some point you need to sit down and restructure to get it maintainable, but people who are good with it design it well from the start.
It fits the test bench and small/mid-size experiment system very well.
> I wonder if there is a way to get the best of both worlds? [...]
I believe so.
Furthermore high-level languages with syntax-highlighting (think Haskell, Python, Elm, etc.) in state-of-the-art text editors are in a better position than the "free-canvas" node-edge editors to provide the base for such a widely used language.
Blockly goes into the right direction, but has a childish touch and I do not think the keywords should have a background with padding.
I think the advantage is that they make syntax errors impossible and are more discoverable, because the available blocks can be seen in the sidebar. Of course once you have mastered a language, it is more efficient to write text, but for a beginner it can make the entry less daunting.
Pipeline Pilot (Biovia/Dassault) - Deeply entrenched, industry-grade visual (+textual(PLSQL)) programming system. Depending on who you ask, it is either the bees-knees or a f*ing cancer.
Have a look at the ideas SGI 'explored' with 'IRIS Explorer'. This was ahead of its time and ahead of even SGI hardware. However you could layer up lots of interesting datasets in ways that would otherwise require programming at some other level.
IIRC this became the basis of Cosmo Worlds which a company I was with, at the time, used extensively to build computer based training. It was an interesting mix of visual programming and scriptiong. It was based on wiring inputs and outputs into scripts. I really enjoyed working in Cosmo Worlds.
Cosmo Worlds was the tool I used to get my sister a job. I downloaded Cosmo Worlds and I paid for it. Around £450 pounds in 1998? We spent the weekend building a VRML version of her CV with all those things Cosmo Worlds was brilliant at, spatial sound, things that moved, lousy lighting that cried out for a GPU.
My sister had rocked up fairly homeless the week before, we put a solid 36 hours on CosmoWorlds and my sister ended up in an awesome career thanks to what was on that one floppy disk - VRML.
The ambition of Cosmo Worlds was something else, we ended up with a flat web instead.
It was a great technology fun bit of history my company was in a bidding war with Computer Associates for it when SGI decided to dump it, sad part was we where a profitable CBT company that had the extra development capacity to support it. Sadly we did not have the pockets that CA had and therefore where outbided, we knew it was the death of Cosmo Worlds and had to adjust course pretty rapidly, sad part was there really was no competitor for real time web based 3D at the time. VRML had a chance until Cosmo Worlds died. We ended up moving all of our CBT to the unreal engine and retreating back to the desktop. Back then I wrote a pretty popular collision detection library for VRML.
Literature is very scattered as the domain "Visual Programming" is pretty broad. There are general-purpose languages on one hand that really try hard to provide all the tools to build complex systems and domain-specific languages for ... well specific domains.
The general-purpose ones did pretty bad (at least I don't know of any complex system tools - say kernels - implemented in them), but there are some niches were some people seem to like them.
- LabVIEW for control system prototyping
- Shader-Languages for image processing (games via Unreal Engine and rendering pipelines like Blender)
- Model-Editors for simulations and in engineering
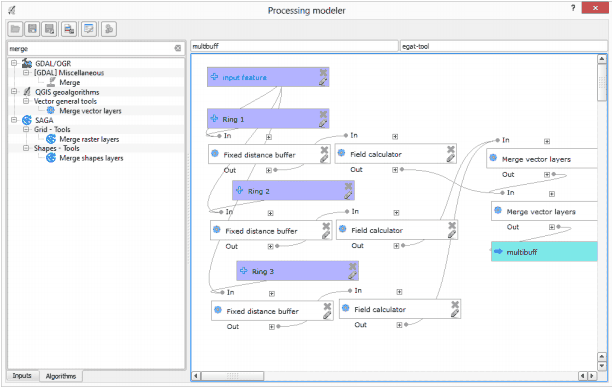
E.g. in the GIS domain people often process digital aerial imagery via pipelines that can be represented in a similar fashion than this Show HN proposes (for example the model editors in QGis and ArcGIS). Here is an image of a model builder to process some geo-information: http://3.bp.blogspot.com/-9iOyUC8RHXs/UrM2ML5Qe9I/AAAAAAAABx... I am not sure if building this chain via this editor is actually simpler than learning some command line tools or basic Python to accomplish the same thing.
It makes sense that domain-specific ones do better, as they don't have to provide tools for stuff, which is uncommon. It is also easier to implement fold-like structures (say function f: A -> B) that process data with clear input and output than programs that do more IO (say f: A -> IO B). If you do complex IO, you have to introduce some concept of order and time in your system and it is not clear how to do this via the graph approach (example: while-loop), or just can be misinterpreted (edges/connections may symbolize ordering on one hand and data-flow on the other hand).
Assuming one should be able to program general-purpose systems (like all the tools we love: operating systems, databases, interpreters, web-servises, etc.), the solution might be not trivial, but I suppose it is more like the interactive notebooks than the graph approach.
Furthermore I think it makes sense to always have a semantically identically text-based language, as this just makes tooling simpler.
"I've" is not normally used where it is spoken as "I have". This is similar to people using "an" in front of a word starting with "h" where the "h" is pronounced. Not sure why people do this.
I think the distinction sidegrid was making is not actually about pronunciation but about the two uses of have as an auxiliary verb and as a verb indicating possession.
My impression is that standard American English only contracts the auxiliary verb ("I've biked up Mount Tamalpais") and not the possession verb (?"I've a pair of prescription sunglasses"). Hence "I've been diagnosed with bronchitis" (auxiliary) but not ?"I've a case of bronchitis" (possession).
However, I think this rule is different in Commonwealth English, so we might just be witnessing a difference in English varieties.
As a Commonwealth English speaker, I am not aware of a rule preventing contraction of the possessive verb "to have." Maybe there is, and I'd be interested to learn about it.
Having said that, commonly I wouldn't say, "I've a case of bronchitis," rather just "I've bronchitis." It feels more natural to say "I have a case of bronchitis." However, this may just be personal preference.
Node.js-based with a Pipes-like visual wiring interface. It's quite popular with the Raspberry Pi and Arduino crowd. Lot's of input and output plugins, and you can drop into Node scripting when necessary. I quite like it.
They do a fraction of the data manipulation options available from pipes and they require connectors being custom developed, plus they limit you on result delivery, which cannot be pulled.
No those don't do at all what pipe did. First of all, everything needs development. Secondly, webhooks and all that stuff are push only.
The real value of pipes was to pull data out from any compatible client. Wonderful for processing data and have it pulled from a feed reader, not so as a trigger engine, for that zapier abd ifttt are better, but to straight out pulling data from a reader processing websites on demand, none of those could replace pipes.
I'm interested in the answer to this questions myself :) For me, this is about the ease of use of the visual programming interface, and the focus on feeds to enable the pipe concept. I do not see this in the same space as Zapier and IFTTT, but I might be wrong!
I'd be interested to know which blocks and functionality is missing to support the use cases you used Yahoo Pipes for! And of course general feedback is always welcome.
Nice. It's not very clear that you need to link the pipeline to the right-hand side. (I can't remember if you had to do that on Yahoo, it's been so long!). It's particularly a problem on a wide screen because the eye starts on the left, and I built my pipeline on the left and it took me a while to figure that out.
But well done on scratching an itch that lots of people have had!
> I can't remember if you had to do that on Yahoo, it's been so long!
I have a screenshot on my disk: https://imgur.com/a/TExPX - it had a bigger pipe output block at the bottom. I can see how the red circle alone is not enough, thanks!
Nice. Anyone else here ever use Ab Initio? It's an ETL tool for transferring data between databases and manipulating in the process. Seems very similar.
I've always wanted to recreate something with those ideas because it was a very efficient cross between visualizing code and writing it. This looks pretty similar although for different data sources.
This discussion is very interesting to us, as we are building a workflow system for collaborative learning (students might do an activity individually, the output of that activity is aggregated and transformed, students are grouped based on an algorithm that processes data from the previous activity, output from one activity is redistributed to another activity, etc). (quick demo: https://www.youtube.com/watch?v=HQ9AyzLOn3Q)
So this discussion about visual languages, data transformation etc, is very relevant to us. One thing we're working on is how to make data transformation more intuitive... Right now we are using JSONPath to enable selection of one field to aggregate on (ie. you have a form where people input ideas, and another activity that takes a list of ideas, so you can input a JSONPath for the field to get aggregated). However, looking at JMESPath (http://jmespath.org/examples.html), it looks much more powerful. Has anyone seen any examples of graphical interfaces for going from one data representation to another, with preview, selecting fields, aggregation etc?
Unrelated to pipes specifically but along the same lines, I feel like app developers ought to conform to a pre-defined standard like schema.org for their respective content so that everything can be inter-operable in theory. That way if I'm using Microsoft Todo or Google Keep or whatever, the potential for Google Assistant or Siri or Cortana to add to whichever Todo App I'm using is already there.
What are the drawbacks behind something like this?
No incentive. If your service is used through something else then you are easily replaceable and users don't spend time in your app.
edit: Just to be clear, I'd love that too. Hopefully it will start happening when everything is driven more by micropayments rather than ads. I'd imagine you'll have "gui companies" and "service companies".
It's also really hard to do. I mean, imagine how one would achieve interoperability for a project like this. Placing blocks via an API from another service? The language/spec supporting that and everything else would be too complex.
But thankfully we have RSS for the data representation, which is a related idea, just the output side. The core of that idea is what enables this site in the first place.
I used to use yahoo pipes for a few twitter bots I had. There was an rss to twitter webapp that I hooked up and it was fully automated for years before it stopped working.
I didn't see the thin red circle on the right, which I now understand to be the output. I almost gave up before realizing my mistake.
Using yahoo! pipes I created a lifestream application[0] some years ago that won an honorable mention for the 10k javascript challenge. It was nice to have a dynamic site that required no server work on my part.
Updating it for this would probably be a neat way to test out the RSS feed usage.
Very interesting, I do think that visual programming tends to work better when constrained to a small niche of computing, that's the hypothesis behind https://github.com/AlvarBer/persimmon
I've made something[1] that used "jq for everything" in the past.
RequestHub was initially a way to connect webhooks from one service to API calls to another services, using jq scripting for all the customization.
Later I realized it could be used for processing anything (even text!), not only webhooks, but it was too late. Maybe someday I'll do a Yahoo Pipes revival that will just use jq for scripting inside the boxes.
I think Zapier and the likes fill this need pretty well. I wonder if there's still a niche for more lower-level hosted service for plumbing webhooks though. It might be a rather small niche unless you figure out a way to offer better value than those guys.
One thing that definitely makes it hard is the chicken&egg situation. I can't imagine many people paying for a service (or even using it for free), unless it has a solid reputation and is highly available. Otherwise, they'll either host something on their own, or use one of the bigger players.
If I understand you correctly, you want to be able to join the results of multiple sources? You can do something like that with a library I wrote, riko [1]. A simple example would look something like this:
I plan on enabling filtering via xpath, and in parts jq is like xpath for json. But I'm not sure whether you mean something more with "then combine it with RSS or other JSON or what have you"? Merging generic input into a feed at a chosen element?
Side remark: Pipes uses https://github.com/feedparser/feedparser to normalize atom and rss feeds, and that gem just got support for the jsonfeed format. Untested, but worth a shot if you are looking for json input.
You connect and configure various compontents (Input, Output and Manipulation) to achieve you desired dataflow.
It's compiled to Java and really Vera versatile.
You can check out my library riko [1, 2]. While it doesn't have a slick GUI, it does support most of the original yahoo pipes (including xpath [3] and regex [4]).
I'm not sure. There are a couple of existing services that do that already, and which give you a rss feed you could then import here. But if it gets requested I would look whether it is doable in the constraints of this system - at least I remember yahoo pipes supported it, that's a plus.
>I remember yahoo pipes supported it, that's a plus.
Yup, pretty much why I used pipes to begin with. I think being able to scrape/manipulate/output data, while being able to keep it private, would be a fantastic service. Looks good so far!
I added a block to download a page (instead of a feed), another block for extracting content via css selector or xpath, and a feed builder block to later combine those (but the extract block already creates a feed one could use as pipe output). If more is needed please say so, I am now convinced this fits well to this page.
Yo, good stuff on the added features. I'm currently using Huginn to scrape data, use a portion of that data to format a post request, and then combine the results of the post request with the scraped data, finally output as rss. Maybe some features to consider: ability to format get/post/put/delete request, ability to correctly (in order) merge objects (I haven't had the chance to try out your merge block yet). The merge, in my opinion, would be the biggest consideration as I have to use a custom agent to merge my Huginn events, and it's really a pain. Great start to the service man, keep up the good work!
edit: I just tried the download agent on a site (http://www.plndr.com) and it's throwing parse errors, and clicking the [x] won't close the output box, but the red portion works.
I now understand the issue with the red portion and the [x]. That will be fixed soon.
For the page, there was a bug with get params, those killed the output inspector. I fixed those now, it should be better able to fetch pages like http://www.plndr.com/product/browse?a=34714&catId=0&version=.... I was able to extract the product names from there in an example page, just a download block and an extract block selecting `.product-cell .product-title`. If you still have problems, would you please comment again, open a bug on https://github.com/pipes-digital/pipes/issues or send me a mail? Kind of crucial to iron the kinks out.
The parse errors are annoying, but I failed silencing them so far. The XML parser is throwing them regardless of try-catch, I don't know why. But they will be just ignored later on: 'View output' should show the pure html (instead of parsed and highlighted XML) instead. That seemed to work fine so far (but might fail in a different browser than those tested...).
Sure, I'd be happy to help. On viewing the html, I'm not sure what software stack you're using, but maybe check out the riko[1] library, which was recommended in a parent comment.
Pipes is a Ruby stack, with sinatra at its core. But viewing the HTML is actually all client side, meaning javascript. When the block output view gets more complicated I'll probably move it to the server.
For now I added some code to detect the different formatted parse errors in webkit browsers, maybe that catches also yours?
But I'm not very happy with just showing the HTML (though it goes through a formatter at least) in that error case. In the long term the extract block should get a visual element picker to create selectors, then it will matter less, but that's something for later.
Every pipe is a recursive list of blocks, like a tree. Basically, a pipe has a starting block that produces the pipe output. To do that it calls the process function of its input block, which again run their input blocks, ..., the feed blocks serve as tree leaves.
Cool product, and great to see this get traction! My new company is very much inspired by Yahoo pipes and making something similar. Would love to chat about your approach!
I really loved Yahoo Pipes - Was ahead of its time if you ask me..Built some very cool automations on top of this. Basically was IFTTT and Zapier well before them.
So far you need to log in to save the pipe and then see the output.
Shoot me a mail to admin@pipes.digital (or to the one in my HN profile) if you want to try to sort out the non-arriving email. Or if you have a gmail address, log in with that, portier (the login system) supports the OIDC flow for gmail.
How do you like NiFi? I work at Alteryx (we have a closed source visual data integration tool targeted at business analysts and data scientists), but was actually investigating NiFi quite heavily before I joined my current company. It didn't appear to me to have much adoption, but that was over a year ago. It certainly looked extremely compelling as a tool targeted at advanced users.
So I would agree that its not intended to be a tool that you could use like yahoo pipes. To the extent that it requires programming, I guess I would agree it requires an advanced user.
Putting that aside, I would say the Nifi is easy to work with, performant with large datasets, and I personally love the notifications I get when tasks get screwed up, etc. I would not suggest using this to expose data flow to your user as its UI is not really geared towards folks who are programming averse (to a certain extent).
{kind=link}
{kind=link}
{kind=link}
This does not mean that text is the only way to implement programs (and even if you connect nodes, you're still programming), but maybe a good local optimum is in-between, e.g. interactive shells like Jupyter's Notebook and the Mathematica interface. I know there is LabView, the Blender-Editor and AFAIK some Unreal-Engine tool that uses this model, but bigger programs seem really incomprehensible to me.
It's always easy to show-case 5 programs in these node-&-edge editors, but I do not think it is the best approach for visual languages, as one should not under-estimate the layout problems and how to represent information in boxes.
So, I am all for new ideas in visual programming, but I am not sure if the "free canvas" approach works.