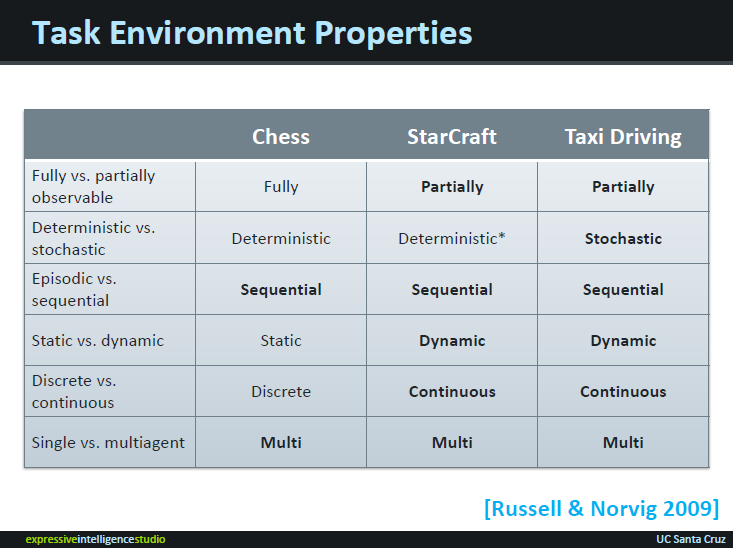
I believe we are witnessing the Cambrian explosion of intelligences. The techniques behind Libratus (abstraction algorithm and game theory [1]) appear to be qualitatively distinct from those behind AlphaGo (deep reinforcement learning and MCMC) and DeepBlue (search and heuristics).
An ecology of Artificial Intelligences, unbounded by our evolutionary history and neural architecture, could evolve to suit each particular task more effectively than our brains can.
Chess, Go, Poker... All feel like variations on the same theme. While it's obvious there is innovation being done, I want to see something more challenging. Something with more dimensionality and integration of several types of input.
How about a machine that can beat someone at Smash Bros, a game with varied characters, complex comboing mechanics, and a nontrivial computer vision task?
Or--more difficult by a few orders of magnitude--what about a robot that can beat someone at tennis? Or a team of robots that can best a professional basketball team?
When do you suppose we'll begin to see these sorts of things? Within our lifetime, I hope?
Check out https://github.com/vladfi1/Phillip. It's a Super Smash Bros bot that can beat the top players in the world and is run by a tensorflow model that can be created by playing against it for a few days.
>Something with more dimensionality and integration of several types of input.
like using a few degrees of freedom and little strength to chop onions and some vegetable, crack eggs, whisking them, pour a bit of oil into a pan and lighting a stove, pour the omelette, flip it onto the plate, throw the eggshells in the trash unless it's too full (and take the trash out if it is) and wash the chopping board and pan with a sponge (adding a little dish soap) and not too much water, then rinse them thoroughly but without too much water. Which poses no challenge to most adult humans who take just a bit of time to learn (if you never learned to make an omelette and you're an average adult, by Wednesday you can make a perfect omelette every time.) Even though objectively humans have very weak hands, see things very, very slowly compared with machines, and cannot do any single mechanical action as reliably and predictably as robots.
computers might be able to find and count all the primes between one and a million before I can count the ones up to ten[1], but they can't even scrub my bathtub with a sponge given a whole afternoon to do it - not without a lot of specialized robotics anyway.
We make up for hand weakness with hand dexterity, slow vision processing with incredibly rich feature sets and powerful cameras, and reliable actions with previsioning and prediction on every task.
Yes, this is the kind of task computers should "compete with" - using weak and semireliable motor functions and cheap cameras (no infrared or laser vision etc) and making up for it with "smarts" - the way humans do.
This is not really a good example. That bot is massively cheating and if you played against him a few times you would find very simple patterns that always beat him.
(I don't even think the base AI can actually see your location in the air very well, and it has no air DI itself so it really could not win for long.)
This one is a better example - https://github.com/vladfi1/phillip. It does not have such perfect reactions and can be trained on a tensorflow model that you can build in a few hours/days by playing against it. Although it plays weird, it plays a lot more like a human than the other bot. And yes, it is very very good - it can pretty easily beat top 50 players.
Poker is somewhat different due to incomplete information and its highly stochastic nature. It's easy to infer incorrect action-payoff relationships from observing hundreds or even thousands of hands. Like the stock market, the cards can stay irrational longer than you can stay solvent.
There are no fundamental algorithmic differences between chess and poker. The incomplete information aspect of it only increases the size of the nodes in a game tree, as each node must now track all possible private states for each public state. Beyond that, there are no fundamental algorithmic differences. There are algorithms that have been devised to handle such large game trees to speed convergence (regret minimization for example), but beyond that it's just a bigger game.
The fundamental difference is the way poker is played repeatedly, tracking winnings over a long period. Winning a single hand is meaningless.
Chess can be modeled with each game serving as a single observation. Poker must consider each player's entire lifetime as a single observation. Not simply a hand, but all hands that player has ever played, including what that player knew about all opponents ever faced. This quantitative increase in data creates a qualitative difference.
Poker is less like chess and more like repeated rock-paper-scissors.
This does not apply to solutions which are Nash equilibriums. You are discussing exploitative strategies, something which the CMU team did not attempt to create. They created a game theory optimal strategy.
Optimal strategy might not be a Nash equilibrium. I'm not sure why you think game theory ignores that possibility. The Alberta team wrote some good papers about it.
You misunderstood "a solution" to mean the only optimal solution. Also, note that Nash equilibrium assumes the opponent does not change strategy. Once you relax that assumption, especially with the idea that you can induce change, another strategy becomes viable.
Check out the "Occurrence" section in the article you linked to.
A Nash equilibrium strategy does not assume that an opponents strategy never changes. A Nash equilibrium has the property that if the opponents strategy deviates from a Nash equilibrium, then the opponent will lose.
That's neither my memory of the phrase from school nor my reading of the Wikipedia article.
Nash equilibrium may not exist if one of the players follows, say, a Markov switching process. If that process causes the opponent to stop seeking equilibrium or to settle into a false equilibrium, then the switching process may have been a better strategy than seeking equilibrium.
> what about a robot that can beat someone at tennis?
I think robotic and A.I. are not the same and shouldn't be compare. IMO, the only missing part in beating someone at tennis is having a robot that can compete with any athlete.
Check out https://github.com/vladfi1/Phillip. It is a Super Smash Bros bot that can beat most anyone and is trained with a tensorflow model that you can build yourself by playing it for a few days.
I tend to disagree that this represents an explosion of approaches. For example, AlphaGo and DeepBlue are more similar than they may at first seem. AlphaGo used MCTS (a search algorithm), and value and policy networks as heuristics to evaluate board positions and search order. AlphaGo scored a couple of big wins by showing that you don't need exhaustive search (in fact, AlphaGo evaluates orders of magnitude fewer nodes in the game tree than previous state-of-the art MCTS Go agents, and Go is notorious for such a high branching factor that minimax, et. al., are straight out), and that the heuristic can be learned through reinforcement learning.
Collapse of the current economic and political system as increased consumption can no longer compete with increased efficiencies.
For once. But back when we were thinking about the perils of the internet we didn't correctly anticipate homogenization of media consumption and filter bubbles. People rather thought that it would be the other way around, everyone would have access to high quality information and enjoy diverse (long tail) media content. So we're likely to be wrong about the precise perils here, too.
It's important to note that last time, the poker players beat CMU's AI by around 500k chips as well and they had the gall to declare it a "statistical tie". Yet if they win by chip they will claim to have "won".
which is: "If after 120,000 hands either Libratus or the humans are one standard deviation above break-even, they will have won the competition with “statistical significance.”"
(I'm a professor at CMU, but I have nothing to do with this research or competition.)
we mostly mean by the media. Story if they barely lose "Poker bot statistically ties pros". Story if they are one chip up: "Poker bot leads/beats pros"
also important to note they made the players play thousands of hands over weeks and many said how they played in a way to shorten the time they had to play. thereby not necessarily showing their "true" skill.
> also important to note they made the players play thousands of hands over weeks
To your point, I wonder how they account for mental and physical fatigue. To a computer it makes no difference to play thousands of hands over such a long period of time or hundreds of hands over the course of a single day. Humans on the other hand don't have the same attention span as a computer.
I played poker part time heads up (one against one) previously and the amount of study and analyses players have to do is huge to only get to a reasonable level.
This challenge is very unfair to players so I wouldn't say it won, players have a massive disadvantage, every professional player has tracking software and a database to analyse every decisions that has been made.
This is of course extremely important because you can model your strategy to exploit the suboptimal decisions made by your opponent, yet players have no access to any of these tools, so the bot adjusts it's play based on their human opponents but humans cannot do the same and are left with a guessing game.
If they want to make a proper challenge then players need to have access to the tools they usually use playing in the Internet.
>o the bot adjusts it's play based on their human opponents but humans cannot do the same and are left with a guessing game
Do we know if it actually does it? I imagine it's much simpler to build a bot that plays a balanced profitable strategy rather than one that tries to build a model of their opponent and exploit it.
It's stated in the article. During a day's play, the AI suggests plays based on its current knowledge. At night, the day's events are fed into the system for it to learn on for the next day.
I assume there are probably papers that specify what form of learning is taking place, but the article didn't go into that level of detail and I haven't tried to track it down.
Trying to play GTO is an interesting (and very profitable) approach but ultimately it's not the most profitable approach. It makes sense for the AI to be constructed that way because the matches it's likely to play are against good opponents. Most profit in poker comes from playing against not so great opponents though. Against those you usually play extremely exploitable on purpose.
That being said, the AI seems pretty impressive. Not sure how they picked the players I could think of a few HUNL players I'd rather see but they might not be interested in a 200k freeroll.
It's tough to decide what skill in poker really means. Is it that the AI can win against a good player or that the AI can earn money from bad players faster than other good players?
I wonder if the players tried colluding: coordinate their bets to fake a weakness so the AI start to adopt a poor strategy, then up the bets and stop the feign. I don't see how the AI can protect itself against that.
The aim of the AI isn't to adopt to poor strategies, rather to play an approximate optimal strategy itself. It's aiming to be unexploitable, the further the other players deviate from optimal, the more it wins. It's EV (expected value) comes from the other players not playing optimally, it doesn't care about exploiting individual weaknesses.
If you define a 'not very good' strategy as losing at a maximum of 0, then sure. Playing optimally means the worst case scenario against any opponent would be breaking even. It doesn't have to be trained on individual playing styles, it is simply playing each spot theoretically correctly.
An example, say the humans are getting to a river situation with too many bluffs for a given betsize, an exploit for the AI would be to always call. The opposite is also true, if they are bluffing too little it should always fold. The players notice that the AI has adjusted, and adjust their frequencies - now exploiting the AI. By taking an exploitative approach the AI leaves itself open to be exploited, this is not the goal.
If this were rock paper scissors, the AI is doing the equivalent of always throwing each at 1/3 - even when it's opponent throws rock every time. It could switch to paper, but a thinking opponent will now switch to scissors, this will continue until we are back at equilibrium. The AI aims to play poker in this same fashion, having the correct frequencies of actions for a given range in every spot.
A better AI should be able to fool the opponent into thinking it has thrown rock (metaphorically) so that the opponent throws paper while the AI instead throws scissors.
Poker isn't about equilibrium, it's about misdirection and exploitation. When the table gets cold, you liven it up by convincing everyone to do a round of straddle.
Heads up poker is precisely about equilibrium. Your straddle reference is also irrelevant, this is not live multiway poker.
"Tricking an opponent into thinking it has metaphorically thrown rock" extrapolated into a poker example would be betting larger/smaller, calling more/less, folding more/less than is optimal in a given scenario in the hope that your opponent makes a (bigger) mistake. You're simply hoping he makes more errors than you, the AI instead choses to just make zero mistakes and let the opponents do the rest. You can see this in action for yourself in Heads up limit holdem by playing Cepheus (http://poker-play.srv.ualberta.ca)
You're still thinking one hand at a time. It may be possible to confuse the opponent into permanently shifting strategy.
I agree that would not happen if two equilibrium-seeking computers played each other. Since the human strategy is unknown, it is possible that equilibrium may not exist or be optimal. Even if it's two computers, if one of the computers has the possibility of choosing a non-equilibrium strategy, then again the optimal strategy may not be to seek equilibrium.
AI's aim is not to adopt poor strategies. It seeks to optimize, but the point is you can lead it to believe a point is global optimum, when in fact it is only local optimum.
As to your point about the EV, this is why collusion can work. By colluding over a long enough horizon, the AI can believe that the average expected value to be something that it is not. If only one individual feign a weakness and the rest do not, then the strategy doesn't work.
You can't lead it to believe a point is an optimum, it's just responded to a bet size/check in isolation given the information it has. If you 'feign weakness' in a given spot it will just respond as optimally as possible to the bet size.
For example attempting to feign weakness by betting small in a spot where your entire range should bet large is not tricking the AI, it's just passing up on EV for the players, good players are not going to play poorly in hope of tricking the bot for future mythical EV gain.
This is a multi-day competition. Players may coordinate in each round, but I mean to coordinate in each day. If you only coordinate over a short horizon then the complexity of your deception is lower. So for example, all players adopt a common feigned weakness on a given day, and let the computer believe those behaviors is part of a pattern to exploit. Then on the second day, up the bets and stop the feign.
This happens in algorithmic trading, where traders would make a large number of low-valued, bad bets to mislead the algo. Then bet big and go the other direction.
Libratus biggest edge is probably grinding away at their blunders & tendencies (eg. Don never check raise bluffs in this spot, so I can safely value bet). It would be really interesting if they published the bots results vs. a mythical generic player. The difference would be a nice estimate as to how big an edge it derives from backtesting it's personalization strategies.
Yes it does. The Libratus bot uses a conterfactual regret minimization algorithm variant of the CMUs teams' own design to calculate endgame strategy. The inputs to that algorithm explicitly takes into account previous player behavior.
That is very unconvincing as 49k hands is really nothing and not enough to iron out variance unless the edge is really big (which doesn't seem to be the case). Any serious poker player will tell you that.
They should play 1-10 million hands (depending on the edge) in order to get a decent idea of where this is going.
Yes, I'm wondering if anyone is tracking the relative strength of each player's hands. In the end, the bot should be declared the "winner" only if its winnings were disproportionately high in relation to the strength of its hands.
The usual way they reduce variance in these man vs. machine poker showdowns is to do "pairs" play. You have two humans playing simultaneously in isolated locations. The decks for both humans are the same, but player 1 and 2 are swapped for one human. That way, the bot strategy has to play both hands.
It does totally eliminate variance, but they also take that into account and correct for it when looking at final outcomes usually. Right now the bot is up by something like 800K over 60K (out of 120K) hands. If that rate continues, it will win by around 1.6M or 400K per human. The blinds are 50/100, so that would equate to roughly 33 millibets (thousandths of a big blind per hand). That isn't too far off from standard win rates in bot vs. bot tournaments [1].
I'd say it's likely that the results of this tournament will be a statistically significant win for the bot.
That trick doesn't change the variance at all if decks are the same.
Typical winrates in human vs human are between 1-5ptbb/100 where 1ptbb = two big blinds. At 1ptbb the variance is pretty big and north of 1million hands are probably necessary to establish an edge, whereas at 5ptbb the variance is much smaller and 100k hands are usually enough to converge to the expected value
How would someone with no knowledge of the game learn to play poker? Any good books that stress the mathematical/probabilistic(/game theoretic...?) side of things?
Poker enthusiasts hang out at the TwoPlusTwo forums[1]. After reading up on combinatorics and learning the rules for numerous poker variants, diving into the forum posts will give you better insight into how players view the game, the situations they get into, and how they learn to analyze and read hands and other players.
Unless things have changed significantly from the previous version (Claudico), this is not really no limit hold'em, as the stack sizes are reset every hand.
One of the distinctive traits of no limit tournament is that on any given hand a player can be knocked out the game with a big enough bet, which affects how players are likely to play (as might one player amassing a large chip lead ove another if neither player opts to go all in on early hands)
Of course it also makes games shorter and introduces a lot more variance, which isn't so good for assessing how well a computer plays.
This isn't a tournament though, it's more like playing a very long cash game where the stacks are reset on each hand. Whoever has the profit at the end of the cash game will be the winner.
In no limit, if you lose a hand you have fewer chips, which changes the applicable strategy. There is no version of no limit where every hand is played with the same number of chips.
It is akin to only playing the first 10 moves of a chess game, then resetting.
This is indeed a version of no limit. What defines it as no limit is that there is "no limit" on the bet sizes. The fact that the chips are reset each hand doesn't mean it isn't no limit.
The chess analogy would be more akin to resetting after the flop.
On the contrary, no limit is never played where you reset the game after every hand. The fact that this is happening indicates that the strategy is not in fact complete. I expect the strategy would lose a heads up tournament nearly every time.
Not at all. Their strategy has almost no practical level in any existing poker game. They've come up with a solution to a variant of poker that no one actually plays.
It's a great solution, and at that stack size, I'm sure it's better than nearly every human competitor. But until they solve all stack sizes down to one big blind, their strategy is practically incomplete.
You do realize that the deeper the effective stacks are the harder the game is to solve? It is far easier to approach GTO the closer we get to push fold games, and thus your suggestion is akin to acknowledging that they have landed on the moon, but how about they climb this tree over here. If your username suggests you are who you are, this is a bit bizarre to me that an apparently intelligent engineering manager who has played poker before can be so woefully misinformed. If you want to learn more I suggest posting your thoughts on 2+2, they will gladly explain why your thesis makes no sense.
Yes, I am who I am, and I've done a little more than "play poker before".
While it is true that solving a smaller stack size is cheaper, you have to solve many stack sizes from 1 to N to get good coverage across the space of all play.
I've been following this work for over 15 years, and they certainly deserve credit for what they did. But what they have done falls short of the banner headline.
Honestly, this doesn't look to be a true test of who is better at poker. Poker is not like chess - a lot of emotions are involved in reading another players' cues (if he is touching his face, whether he is talking nervously, how quickly does he call all in etc.). Making all this computerized seems to take the spirit of poker away. It is like playing online poker which is an entirely different ball game vs. real poker.
I'm not a great poker player, but I read a lot about them. And most great poker players say reading peoples emotions/cues/or tells isn't reliable or a big deal.
So in that sense , online poker is very similar to live poker, the strategy doesn't change very much
Acting is a good strategy against weak opponents. I would never try to "Hollywood" against a good opponent, but then I'd never get involved in a big hand against one either.
Against a fish, yeah, I'll ham it up and they eat that stuff. If they're on the edge of a decision, some good acting can push them the direction you want.
I guess I'm agreeing with you -- a pro would never pay attention to my "tells".
i'm very into poker. you're right about the tells but what is important is knowing the other players. you can tell what type of players and how aggressive or "soft" they tend to be. you know if they would tend to call or raise a weak hand in certain situations.. etc. it definitely matters
Well a human would know those players by playing against them or watching replays of their games, I am pretty sure AI can do the same and will have a better memory of what are the habits of each individual player it played against or saw their game replays.
Physical tells are almost entirely Hollywood nonsense. When a professional player talks about getting a read on someone, they are talking about probabilities combined with the opponent's position at the table and a history (even a short history) of that player's betting/play patterns.
> Physical tells are almost entirely Hollywood nonsense
That's true for most any level of serious player, but I see it often in casual games in peoples kitchens with casual players who don't play often or are just starting. Even I can't control myself sometimes when the adrenaline starts pumping. I'd rather say lack of self control is just one of the most amateur things you can do in poker, and what's nonsense is the idea that it's a meaningful aspect of any kind of serious poker game.
This is not true at all. If you play online vs live then yes. But physical tells are absolutely still thing, and Im not talking the way you crack an oreo.
Those physical cues are such a small small part of poker. There's a reason the top players are all online players. Poker is a game of math first and foremost.
If it's unfair in any regard (and I disagree with GP that it's unfair on the merit of physical reads), it's that humans get fatigued and computers do not. Having played poker for stretches of 16+ hours I know that the number of mistakes I make late in the day drastically outnumber the ones I make when I am fresh. And breaks only do so much to counter this fatigue.
I'd have to say that playing poker for long stretches of time is at least as, and possibly more so, than grinding for 12-16 hours writing code.
Even still, it's a stretch to call it unfair. It is brains vs. AI, after all, and that will always be true of brains no matter the task - fatigue is a factor, and this is where AI will have important advantages in the future.
It's not that it's unfair, it's just a considerably different game than human vs. human poker. It would, however, be very interesting to see if the software can reveal exploitable tendencies in the players' behavior that even other top players would be unlikely to discover.
> Making all this computerized seems to take the spirit of poker away. It is like playing online poker which is an entirely different ball game vs. real poker.
Maybe, but it seems like impressive performance nonetheless.
Very very long. First of all, this bot was capably only of analysing heads up play. At the WSOP there can be maximum 10 players at the table, and with each extra player, the number of combinations to analyse grows exponentially.
Second, in the WSOP it is key to exploit weaker opponents. This bot was able to find almost perfect play against expert opponents but exploiting weak play is a different ballgame, especially if you are facing a mix of strong and weak players at a multi handed table.
Really long. It will still have to get lucky, or at least avoid being unlucky. This is why amateurs routinely crash the final table instead of just pros.
And tanking for 1+ mins on turn and river decisions (it would time out in real online poker). And $10M in computer resources. But impressive nonetheless.
First of all, that's not true. Most players play several tables at the same time against the same player, up to four heads-up. That's something like 600 hands an hour in HU.
There's little heads-up play in live games, other than at the end of the tournament, and the stack sizes are completely different. These are not tournament players, they're heads-up specialists. They most assuredly play online the majority of the time.
Second of all, the computer doesn't read the human players, why would it matter? It's all up to actual strategies at that point.
Not really. Online poker is much more popular. Plus the computer doesn't have a camera either. You have to deduce if your opponent is bluffing through the plays he/it is making.
{kind=link}
An ecology of Artificial Intelligences, unbounded by our evolutionary history and neural architecture, could evolve to suit each particular task more effectively than our brains can.
Promises and perils abound.
[1] http://www.cs.cmu.edu/~sandholm/ section "Algorithms and complexity of solving games"