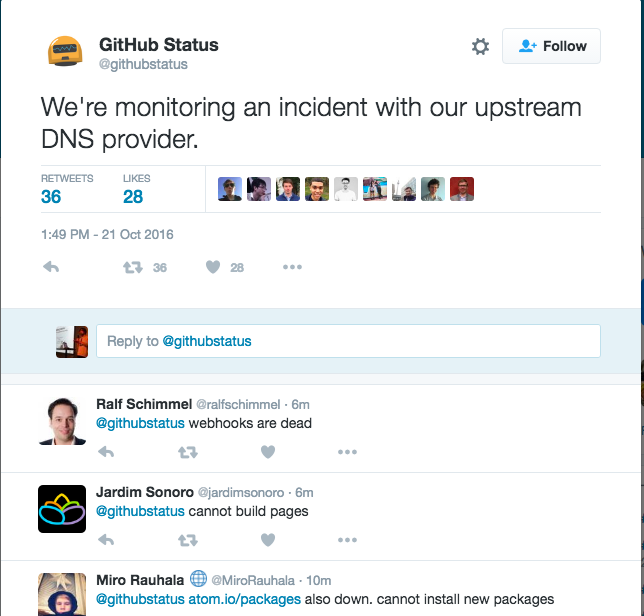
Sites down:
- DYN
- Twitter
- Etsy
- Github
- soundcloud
- spotify
- heroku
- pagerduty
- shopify
- intercom (app, not landing page)
Note that if these sites seem to be up to you, it's likely that your machine has cached the DNS response for these sites.
Some of these sites seem to work when using a UK VPN
{kind=link}