Yes, the methods here have been seen before, but there were some tricks that I haven't come across earlier. Avoiding the stencil buffer (why?) with additive blending in color buffer is something I haven't heard of before. Similarly, the implementation details of the antialiasing using color buffer seem like original work to me.
I think that this was partially motivated by limitations in WebGL. More modern graphics APIs would allow better control over the render target (no need to hassle with RGBA8 using arithmetic tricks, just use integers if you need) and multisampling (gl_SampleMask for MSAA'd "discard" of fragments).
I was familiar with the Loop-Blinn stencil-then-cover trick (and I've worked with GPU path rendering before) but there were some interesting tidbits in this article regardless.
GPUs and all drivers do not support independent stencil buffer. If you need a stencil buffer, then you need to make a Depth=24, Stencil=8 buffer, also called D24S8.
If you have floating-point 32 bit depth format, sorry, no stencil buffers.
If you don’t have depth at all, stencil buffer would take 4 times more VRAM: for color buffer, having just single component is fine, e.g. GL_R8UI or DXGI_FORMAT_R8_UINT.
Yeah, D24S8 is the typical depth-stencil buffer format. That's also the most common format to have in your "default" framebuffer in OpenGL apps, but in this case there might be some WebGL-specific limitations that the author wants to avoid.
WebGL is still based on GLES 2.0 and if you go by the book, you probably need to account for a 16 bit D16 depth buffer without a stencil present. That's probably not a very common case in practice (except old mobiles), though....
Is there any reference to where this technique originated?
I think it is much more elegant than the traditional point-in-poly ray-cast rasterization technique.
> I think it is much more elegant than the traditional point-in-poly ray-cast rasterization technique.
This is pretty similar to the point-in-poly raycasting (this is especially clear if you use the stencil buffer, but for some reason the author actively avoids that). You might also see some similarities with stencil shadow volumes (as seen in Doom 3).
There's two tricks used here: stencil-then-cover for the "bulk" of the shape and the Loop-Blinn method for doing quadratic Bezier curves in a triangle. You can find plenty of resources on both.
Agreed, but my cg education (many moons ago), usually covered point in poly with a specific section of code to do ray intersection with segments. None that I can recall used the stencil trick, which is so much more clever and simple than solving line equations. I am just wondering... who came up with that first?
I looked for the original Warnock paper online, but it is behind the ACM paywall. That would at least tell me if they knew of that in the mid 80's.
I will check out the Doom 3 stuff. I had that on my reading list from a while back.
You should understand that conceptually stencil-then-cover is the point-in-poly algorithm using line segment intersections. It's just that the GPU triangle rasterizer solves the line equations (or half plane equations) and accumulates the per-pixel result in the stencil buffer.
The Doom 3 shadow volume algorithm is just the same, extended into 3d and using a little bit of depth buffer and front/back face culling to make some edge cases work (self-shadowing, shadow volume caps).
If you want to go read the original paper (please share a link!), you can circumvent the paywall with sci-hub.io if you don't mind a little piracy.
What I like most about this technique as opposed to other "draw a font as curves in a shader" approaches is that it's actually very fillrate friendly. Instead of drawing a quad and calculating curves (or curve segments) over all of those pixels/fragments, you draw the font outline in polygons which restricts where pixel processing occurs. The whole thing actually reminds me of Carmack's Reverse stencil shadow technique (which grave nice crisp edged shadows but also stopped pixel processing for shadowed regions).
"The code is open source on GitHub in case it’s useful as a reference"
Thank you!
"it’s written in the Skew programming language"
:-(
Thankfully the shader code is in GLSL as you would expect/hope.
Well, I'm a bit confused as to how this is fill-rate friendlier than something like [1]: if you are drawing and checking the winding rule via the stencil buffer or color buffer, then you're going to overdraw a lot. A technique like [1], on the other hand, only paints each pixel once.
I would think that, compared to the LUT texture approach, this technique is lighter in FS load but more expensive in terms of fill rate/ROP.
Stencil check rejections based on overdraw don't hurt as much as you'd think. Liken it to a clip() (or discard), which is a single instruction. The GPU pipeline optimizes for this.
The approach you linked too is very well thought out but each font still does pixel processing for a bezier curve, which is many orders more expensive than a clip(). Never mind the addition of a dependent read via the LUT and the tracing step.
The Skew language compiles to Javascript, C#, and C++ (which is still a work in progress). So if you don't like that it's in Skew, you might have the option to switch it to one of those languages. It probably won't work for the more system-dependent parts of the code, but you might get something out of it.
You've misread; Evan says that he based his calculations on a Microsoft paper. Not that he works for Microsoft or that this is Microsoft Research or anything like that.
This is some of the most clear, easy to following writing I've seen when talking about graphics programming. The illustrations are excellent too - good stuff!
I don't get why zooming up the subpixel antialiased image and looking at the color fringes makes sense [1]. Why would you want to remove color fringes from here? That's not what you see, you see [2]. I don't see color fringes in [2].
One downside to this vs SDF is that you would have to distribute font with your application. With that you have to license/buy that font properly. With SDF you're creating an image out of which you derive fonts and for that you don't need to license the font for distribution.
This approach uses much less memory, gives a render that is exact instead of approximate (it doesn't suffer from corner clipping or grid resolution issues as you zoom in), and is quicker to do an initial render because there's no CPU-side preprocessing involved. I haven't profiled both techniques side-by-side though so I'm not sure which technique is ultimately faster.
> Most anti-aliasing techniques do boundary smoothing by treating each pixel as a little square and visualizing the fraction of the pixel area that is contained inside the outline.
That essay is written from a particular perspective and pretends that it is the clearly right perspective. Whether it's valid to consider pixels to be little squares depends on whether we're talking about display pixels or image sensor pixels and whether we're trying to resample or interpolate photographic data or trying to create data (pixel art, fonts) for a specific display medium. Sometimes there simply isn't an underlying continuous field to be point-sampled from. You'll never devise a good way to render text on an LCD with that article's mindset (not too surprising, since it's from 1995).
The paper is old, but it's actually a fairly trivial application of signal processing techniques that have been well-understood since the 40s. For sub-pixel anti-aliasing, the approach would be to
1. Construct the underlying continuous field. This is just a function f(x,y) that returns one if the point is within the text and 0 otherwise.
2. Convolve f with an anti-aliasing filter. The filter could be tall and skinny to account for the fact that the horizontal resolution is 3x the vertical resolution.
3. Sample the resulting image at sub-pixel positions to produce the red, green, and blue values.
In the special case where the anti-aliasing filter is a box filter, this is exactly the same as computing the average for each subpixel. For the technique proposed in the article, the filter kernel would be the sum of six shifted impulses (Dirac deltas).
Anyways, I liked the article and wasn't trying to be critical of it. The convolution approach described above is of theoretical interest, but implementing it with any non-trivial kernel in real-time is almost certainly intractable. What I meant was that every implementation of anti-aliased vector graphics is a kludge, and it's pretty easy to coerce aliasing artifacts out of all of them using zone plates as inputs.
I certainly didn't mean to imply that the signal processing perspective was untenable with the modern world of actually-rectangular pixels, but what you describe is really a post-hoc shoehorning of square-pixel thinking into the signal processing framework. And you still haven't accounted for pixel-oriented font hinting or pixel-first design of bitmap fonts and graphics that gives leeway to the underlying shapes in order to maximize legibility when rendered onto a pixel grid. The signal processing perspective can offer some valuable insight, but it's a pretty bad choice as an overriding mode of thought for computer graphics.
Sure, for bitmaps fonts or pixel hinting the signal processing framework doesn't provide much insight. However, the word aliasing itself refers to a concept from signal processing, and in my opinion, it's easiest to think of anti-aliasing from the signal processing perspective.
For example, look at the images in [1] (also a rather old paper). The box filter results (i.e. where the pixel value is set to the average of covered area) are less than ideal.
For what it's worth, you can find a nice detailed description of Microsoft's approach to sub-pixel anti-aliasing in "Optimal Filtering for Patterned Displays" [1]. There is also a follow-on, "Displaced Filtering for Patterned Displays" [2].
Interestingly, both papers feature an aliased zone plate. :-)
Sensor pixels and display pixels also aren’t little squares, and treating them as such (whether for font rendering, photo capture, rendering line drawings, or any other purpose) is pretty much always worse than treating pixels as a discrete approximation of a continuous image. Unfortunately 2D approximation is inherently more complex than 1D approximation, so you inevitably get some artifacts even when you do fancy computationally expensive math, and the choice is about which type of artifacts to privilege.
If you want to get really fancy, you could base all your calculations on the precise region (with a kinda fuzzy boundary) where light is collected by a sensor pixel or emitted by a display pixel, but the advantage over pretending the pixel is a jinc function or whatever [cf. https://en.wikipedia.org/wiki/Sombrero_function] is going to be marginal.
> Sensor pixels and display pixels also aren’t little squares [...]
They're pretty damn close, modulo the Bayer pattern for most sensors and RGB stripe arrangement for most displays. Calling an LCD's subpixels rectangles is certainly an approximation that's valid on the scale of the distance from one pixel to the next.
> [...] and treating them as such (whether for font rendering, photo capture, rendering line drawings, or any other purpose) is pretty much always worse than treating pixels as a discrete approximation of a continuous image.
Whether treating those pixels as rectangles or points is worse depends as much on the software/analytic approach you're using as on the physical reality of their rectangular geometry.
> Unfortunately 2D approximation is inherently more complex than 1D approximation, so you inevitably get some artifacts even when you do fancy computationally expensive math, and the choice is about which type of artifacts to privilege.
True, if you're unjustifiably constraining yourself to treating computer graphics only with the methods of a generic signal processing problem. Bresenham's algorithm is radically simpler than anything involving Bessel functions and also happens to work very well in the real world both in terms of speed and visual quality. Adding antialiasing to it leaves you with something that's still extremely simple and is easy to explain in terms of pixels. An exhortation to never treat pixels as little squares is just plain wrong.
Bresenham’s line algorithm works pretty well for how simple it is (especially assuming you are rendering on a CPU, circa 1970 – with GPUs available on every device it’s an anachronism which only persists through historical inertia), but rendering lines using supersampling on some not-so-rectangular grid and then using a high-quality antialiasing filter to integrate the samples looks strictly better every time, especially if you have a large number of thin lines. If you’re just rendering a couple simple shapes it probably doesn’t matter too much. If you’re trying to render a map or something then using better techniques makes a big difference.
[Unfortunately, even in the best case antialiased slightly diagonal straight lines look pretty shitty on a pixel display, regardless of what technique you use, up until you get to a pretty high resolution. Just an inherent issue with pixel grids.]
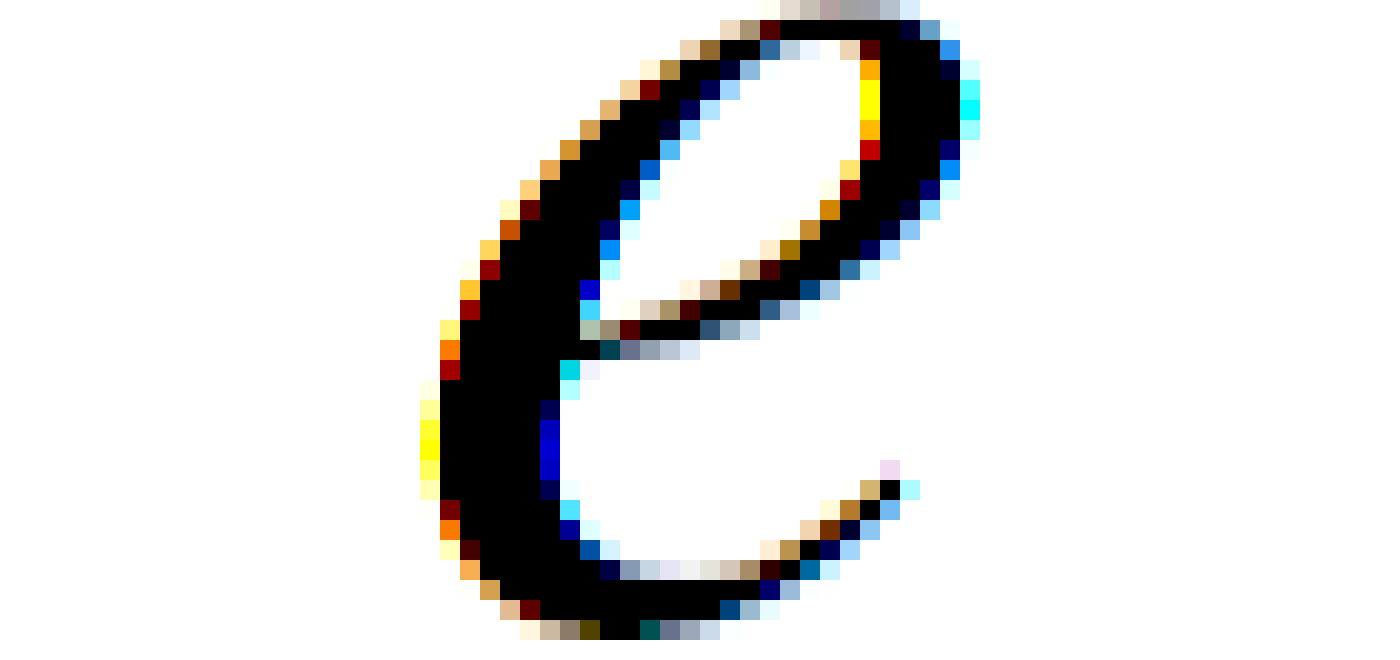{kind=link}
{kind=link}
{kind=link}