I want to point out one other thing about this project, if only to assuage my guilt. And this community of hackers and entrepreneurs seems as good a place as any to clear the air.
There is a necessary abridgement that happens in media like this, wherein a few individuals in lead roles act as a vignette for the entire effort. In particular, on the software team, James and I are highlighted here, and it would be easy to assume we did this whole thing ourselves. Especially given very generous phrasing at times like "Turner rebuilt Magic Pocket in an entirely different programming language".
The full picture is James and I were very fortunate to work with a team of more than a dozen amazing engineers on this project, that lead designs and implementations of key parts of it, and that stayed just as late at the office as we did during crunch time. In particular, the contributions of the SREs didn't make it into the article. And managing more than half a million disks without an incredible SRE team is basically impossible.
One of the things that's not immediately apparent in an initiative like this is the huge amount of effort required to provision, deploy and manage a system of this scale, across a whole bunch of different teams. We couldn't have done any of this without a tremendous group of SREs with the wisdom to invest heavily in automation, in addition to all the hard work.
We'll follow up in a week or two with a blog post highlighting some of the work here. I think the framework for disk remediation (automatically detecting failures, re-provisioning, etc) is particularly interesting.
Nice of you to call this out. I think everyone understands that not all of the people involved will get mentioned by name in a Wired article. A project like this clearly isn't a four person operation, and hopefully most people realize there are always a bunch of people working behind the scenes.
My only disappointment is that by trying to set a PR friendly narrative, Dropbox greatly compressed the time spent on the project from inception to completion, and that erases a lot of people's involvement. As someone who worked on MP when it actually was a four person project, it's a little frustrating to finally be able to talk about it after all this time while at the same time the public perception is that the project began after I left the company.
Very classy to be this transparent about what constitutes a team effort. The common narratives that focus on one or a very small number of visible people has a self-reinforcing effect where those key people get more name recognition and in turn that leads to them being even more visible the next time the team accomplishes something. It's rare for team leaders to step forward and to acknowledge the fact that it really was a team effort.
I assume Site Reliability Engineer from the last time I looked at their openings. I didn't look at the description, but I assume it's a more formal description for devops?
One thing I'll grant Agile is that there's a great deal more standardized technical topics and standards meaning expectations when using the term. With devops, there's a massive difference between how big companies (old, archaic companies by tech company standards) perceive of it compared to how smaller companies do.
My current role was sold to me as a "devops" role with the usual jargon of automation - I can't think of how this role has actually prepared me to pass a serious interview as an SRE at Google, Dropbox, Yahoo, or other tech companies. What really has happened after looking at all the recruiter spam and some of the interviews I've taken on a lark is that the term has become another way of marketing to engineers with modernized skillsets when they can't retain good ones for more than maybe two months (during which time the engineer is interviewing for another role almost certainly) because good engineers tend to run away from these companies for many legitimately founded reasons.
> Measuring only one-and-half-feet by three-and-half-feet by six inches, each Diskotech box holds as much as a petabyte of data
This number is very interesting. Basically Diskotech stores 1PB in 18" × 6" × 42" = 4,536 cubic inch volume, which is 10% bigger than standard 7U (17" × 12.2" × 19.8" = 4,107 cubic inch).
124 days ago Dropbox Storage Engineer jamwt posted here (https://news.ycombinator.com/item?id=10541052) stating that Dropbox is "packing up to an order of magnitude more storage into 4U" compared to Backblaze Storage Pod 5.0, which is 180TB in 4U (assuming it's the deeper 4U at 19" × 7" × 26.4" = 3,511 cubic inch). Many doubted what jamwt claimed is physically possible, but doing the math reveals that Dropbox is basically packing 793TB in 4U if we naively scale linearly (of coz it's not that simple in practice). Not exactly an order of magnitude more but still.
Put it another way, Diskotech is about 30% bigger in volume than Storage Pod 5.0 but with 470% more storage capacity.
Yev from Backblaze here -> Yup! It's pretty entertaining! Granted we only store 180TB b/c we use primarily 4TB drives and it's inexpensive for us to do so. If we had 10TB drives in there we'd be pushing up to 450TB per pod, but the price for us would increase dramatically. Pod 6.0 will be a bit more dense!
To be fair to Backblaze this level of storage density is really only possible with recent advances in disk technology (higher densities, SMR storage, etc).
Also not everyone wants to be packing a petabyte into a box. At that level of density you need to invest a lot of effort in replication strategies, tooling, network fabric etc to handle failures with high levels of availability/durability.
I'm tempted to get one and set it up as some kind of cache in my NAS. I'm already in silly territory with it now, anyway. 1GB/s of writes sounds crazy though - I haven't got anything that can write to it that fast!
I have a PCIe NVMe card (with a Samsung 950 pro M.2 in it) in my home server, which serves as an L2arc device for a ZFS pool. It is pretty nice. Runs a bit warm though.
I think that a home nas would have a lot of async writes and very few/none sync writes. So a ZIL dedicated device (the SLOG) is not really useful/helpful. I'm not sure even if you really need an L2ARC device, just slap 8/16Gb of RAM on it and you will be happy...
Obviously if you are playing seriously with VMs and databases and whatever else both of those (SLOG/L2ARC) may become important for you, I'm going for the "i'm just using this to store my raw-format photos, backups for the taxes and other big files" kind of usage here. :)
We have been primarily using Intel NVMe storage for our database servers since fall of 2014 with no major complaints. Our high end desktop/laptop systems are also using the latest Samsung NVMe M.2 drives which are screaming fast.
We do want to minimize that--compute costs money, and storage is irreducible. But you can only reduce aggressively if your larger distributed system is great at repairs, since the failure of a single box kicks off 1PB of repair activity!
Not sure what is more amazing, the project of this scale (love the disk drawers!) or that infrastructure for managing the fleet of drives gets top billing!
Did you build your own centers? Running our hosting we had far more constraints on our power than anything else. Even though we only had 20U of equipment we ended up taking a 44u rack. Our disk arrays being the largest consumers. This made the case for moving to SSDs even stronger.
That was the problem I always had in my pre-cloud days. We were usually running racks half-full because of power restrictions in the DC. It was convenient because you could keep you cold spares and tools in your expensive space, but it always seemed like you should be putting more useful stuff in the racks.
Is dropbox using SMR? (I never used dropbox. Do they offer incremental backup? Otherwise I would have thought they would need to be able to do random writes, unless SMR is so cheap that it is economical to keep some dead data when a user uploads a new version of a file)
There was a post a while back here from a Dropbox employee explaining how they manage SMR disks manually via a direct HBM card and basically doing what the firmware would do otherwise. I can't find the post but it was talking about working around the architectural deficiencies of SMR while still getting to use more disk space.
Magic Pocket is a block storage system, and all storage in it is append only. We'll go into more detail on the on-disk format in a blog post. But, yes, we use the SMR disks on an HBA, and we directly address the disk on a LBA (and zone) basis.
10 TB drives can be gotten off the shelf -- http://www.hgst.com/products/hard-drives/ultrastar-he10 -- and 14 TB drives are probably in the state of availability for large customers; it's not unusual for drive makers to make available drives coming down the pipe to certain customers.
True, it's just that they also tend to shout about upcoming drives and boast that they are previewing to select customers. Case in point, HGST marketing is in full swing on that He10 but good luck finding any stock in a mainstream retailer.
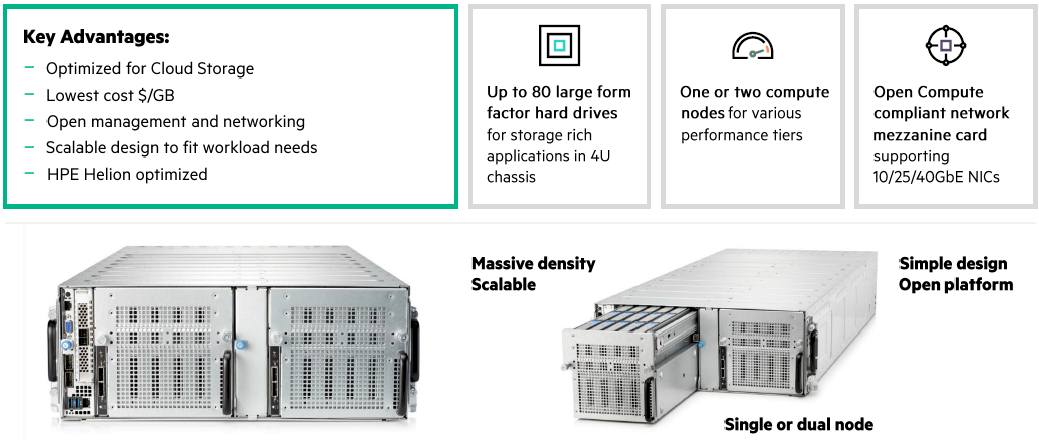
Not to knock Dropbox's engineering, because it is sexy, but there are off the shelf enclosures right now that will fit 90 drives in a 4u case. Given that said enclosures have full rack rails and all, and are narrower, I don't doubt that a more densely designed server is feasible in the least with dropbox's design.
There are other concerns to keep in mind, eg. the upgradability of storage to use next gen cards that use 3d nand, etc. I'm sure they thought through a list of concerns before going this route.
The article makes a brief mention of Go causing issues with RAM usage. Was this due to large heap usage, or was it a problem of GC pressure/throughput/latency? If the former, what were some of the core problems that could not be further optimized in Go? If the latter, I've heard recent versions have had some significant improvements -- has your team looked at that and thought that you would have been OK if you just waited, or was there a fundamental gap that GC improvements couldn't close?
Could you comment more generally on what advantages Rust offered and where your team would like to see improvement? Are there portions of the Dropbox codebase where you'd love to use Rust but can't until <feature> RFCs/lands/hits stable? Are there portions where the decision to use Rust caused complications or problems?
Good questions, let me try to tackle them one by one.
> The article makes a brief mention of Go causing issues with RAM usage. Was this due to large heap usage, or was it a problem of GC pressure/throughput/latency? If the former, what were some of the core problems that could not be further optimized in Go?
The reasons for using rust were many, but memory was one of them.
Primarily, for this particular project, the heap size is the issue. One of the games in this project is optimizing how little memory and compute you can use to manage 1GB (or 1PB) of data. We utilize lots of tricks like perfect hash tables, extensive bit-packing, etc. Lots of odd, custom, inline and cache-friendly data structures. We also keeps lots of things on the stack when we can to take pressure off the VM system. We do some lockfree object pooling stuff for big byte vectors, which are common allocations in a block storage system.
It's much easier to do these particular kinds of optimizations using C++ or Rust.
In addition to basic memory reasons, saving a bit of CPU was a useful secondary goal, and that goal has been achieved. The project also has a fair amount of FFI work with various C libraries, and a kernel component. Rust makes it very easy and zero-cost to work closely with those libraries/environments.
For this project, pause times were not an issue. This isn't a particularly latency-sensitive service. We do have some other services where latency does matter, though, and we're considering Rust for those in the future.
> Could you comment more generally on what advantages Rust offered and where your team would like to see improvement?
The advantages of Rust are many. Really powerful abstractions, no null, no segfaults, no leaks, yet C-like performance and control over memory and you can use that whole C/C++ bag of optimization tricks.
On the improvements side, we're in close contact with the Rust core team--they visit the office regularly and keep tabs on what we're doing. So no, we don't have a ton of things we need. They've been really great about helping us out when those things have sprung up.
Our big ask right now is the same as everyone else's--improve compile times!
> Are there portions where the decision to use Rust caused complications or problems?
Well, Dropbox is mostly a golang shop on the backend, so Rust is a pretty different animal than everyone was used to. We also have a huge number of good libraries in golang that our small team had to create minimal equivalents for in Rust. So, the biggest challenge in using Rust at Dropbox has been that we were the first project! So we had a lot to do just to get started...
The other complication is that there is a ton of good stuff that we want to use that's still being debated by the Rust team, and therefore marked unstable. As each release goes on, they stabilize these APIs, but it's sometimes a pain working around useful APIs that are marked unstable just because the dust hasn't settled yet within the core team. Having said that, we totally understand that they're being thoughtful about all this, because backwards compatibility implies a very serious long-term commitment to these decisions.
> On the improvements side, we're in close contact with the Rust core team
One small note here: this is something that we (Rust core team) are interested in doing generally, not just for Dropbox. If you use Rust in production, we want to hear from you! We're very interested in supporting production users.
Thanks very much for the detailed and thoughtful answers!
I've read before (somewhere, I think) that Dropbox effectively maintains a large internal "standard library" rather than relying on external open source efforts. How much does Magic Pocket rely on Rust's standard library and the crates.io ecosystem? Could you elaborate on how you ended up going in whichever direction you chose with regards to third-party open source code?
We use 3rd parties for the "obvious" stuff. Like, we're not going to reinvent json serialization. But we typically don't use any 3rd party frameworks on the backend. So things like service management/discovery, rpc, error handling, monitoring, metadata storage, etc etc, are a big in-house stack.
So, we use quite a few crates for the things it makes no sense to specialize in Dropbox-specific ways.
Cool. This might be getting into the weeds a bit, but are you still on rustc-serialize for json or are you trying to keep up with serde/serde_json? If you're using serde, are you on nightly? From your comment above I got the impression that only using stable features was very important, so I'm curious how your codebase implements/derives the serde traits.
We're on rustc-serialize. JSON is not really a part of our data pipeline, just our metrics pipeline. So the performance of the library is not especially critical.
We have an in-house futures-based framework (inspired by Finagle) built on mio (non-blocking libevent like thing for rust). All I/O is async, but application work is often done on thread pools. Those threads are freed as soon as possible, though, so that I/O streams can be handled purely by "the reactor", and we keep the pools as small as possible.
From a parallel conversation[0] on the Rust subreddit:
>Are you going to open source anything?
>Probably. We have an in-house futures-based I/O framework. We're going to collaborate with the rust team and Carl Lerche to see if there's something there we can clean up and contribute.
Did you guys use a custom allocator for rust? And if so how did it differ from jemalloc and how could it be compared to C++ allocators like tbb::scalable_allocator?
Yep we're going to get at least a few actual technical blog posts online in the coming month. We haven't got around to writing them yet tho so feel free to surface any requests :)
Will most likely start with the following:
1. Overall architecture and internals.
2. Verification and projection mechanisms, how we keep data safe.
3. How we manage a large amount of hardware (hundreds of thousands of disks) with a small team, how we automatically deal with alerts etc.
4. A deep-dive into the Diskotech architecture and how we changed our storage layer to support SMR disks.
Hopefully these will be of a sufficient level of detail. We certainly won't be getting into any details on cost but we're pretty open from a technical perspective.
(Lemme just take a moment to say how great Backblaze's tech blog posts are btw.)
> Yep we're going to get at least a few actual technical blog posts online in the coming month. We haven't got around to writing them yet tho so feel free to surface any requests :)
Here's a request, how did you migrate all that data. Are you going to be open-sourcing any of the tools that you built up? We'd be interesting in hearing about that process. A lot of folks using B2 right now are trying to do this exact thing (or making copies if not actual migrations). Cheers! ;-)
I would be especially interested to hear how a focus on actual customer experience was maintained during all of this deep technology work.
One of the ways tech companies wrong is by putting the tech first and the users second. I think Dropbox's early competitive advantage was putting the user experience first. Everybody else had weird, complex systems; you folks just had a magic folder that was always correct. User focus like that is easier to pull off when it's just a few people. But once you break the customer problem up into enough pieces that hundreds of engineers can get involved, sometimes the tail starts wagging the dog and technically-oriented decisions start harming the user experience.
Do you know what Amazon is going to do with their excess 500PB of capacity? Are they scaling up fast enough that it isn't a big deal? Is Glacier selling your vacated storage?
You must have left a large hole in AWS' revenue stream. I assume their fees for transferring your data out of their system helped cover that short-term, but 500PB of data is a lot of storage capacity to sell.
Your other answers indicate your separation with AWS was very amicable, much more amicable than I would have expected. Either "its just business" or they have plans to backfill the hole you left.
One of the AWS people at Re:Invent mentioned that Amazon is storing 8EB across all storage services (S3, Glacier etc.)
So 500PB is ~6% of that... Although I'm sure Amazon would have liked to keep Dropbox as a customer it's probably a pretty small percentage of their revenue. Also, if you assume that AWS is growing at ~50% year over year then 6% of S3 is only about one or two months worth of growth.
With storage you're constantly mothballing and replacing old iron behind the scenes, so Amazon might just ditch a bunch of old depreciated drives without hard feelings. AWS being on the up and up for SMEs, they are probably not crying over losing one large but very demanding customer -- and DB are still on AWS for European customers anyway.
Who's part of your security team over there? Most of the big cloud companies have people I trust working for them and I've been pretty comfortable telling most of my clients that cloud services are often going to have a better security team than they will. :)
But now that you've moved away from AWS, have you expanded your security team to help make up for the fact that you need folks to cover all your infrastructure security needs now too? Have you made the hires you needed to deal with the low level security issues in hw and kernel? How have you all been dealing with this so far?
I ask, because I help people make sense of their security issues and my clients explicitly ask me about your company. So keeping track of what you all are doing there is pretty relevant!
We have several dozen very, very good engineers working on a few discrete teams--infrastructure security, product security, etc. I don't feel comfortable getting any more specific than that; we keep security information pretty close to the vest.
To be honest, that response is less than comforting. But I understand how that'd be your answer given your position in the organization. Hopefully someone else at Dropbox feels like sharing more at some point and being more forthright about your company's practices in protecting data others entrust to them.
Feel free to refer others to this thread if you think it'd be helpful.
That's disingenious. The awesome sec teams at AWS or Google are not going to review and maintain your internet-facing VM network config, which is where the real threats are. Sure, their firewalls might be a bit more robust (you don't really know, you can't see them), but anything behind them is just as insecure as you configure it yourself, and that's where penetration happens in real life. Threats at hw or kernel level in a hypervisor are extremely hard to exploit, by the time you get close to that stack you can usually see much easier and juicier targets to harvest.
Sure. So your point is they've always needed a good security team? I'd agree with that. Either way, they should still be open about their security practices and have good answers to the questions I asked.
I'm curious what your inter-language interop situation looks like. Do you have any Go code calling directly into Rust code (or vice versa)? Are they segregated into standalone programs? If so, are they doing communication via some form of IPC?
We use a variant on Reed-Solomon coding that's optimized for lower reconstruction cost. This is similar to Local Reconstruction Codes but a design/implementation of our own.
The data placement isn't RAID. We encode aggregated extents of data in "volumes" that are placed on a random set of storage nodes (with sufficient physical diversity and various other constraints). Each storage node might hold a few thousand volumes, but the placement for each volume is independent of the others on the disk. If one disk fails we can thus reconstruct those volumes from hundreds of other disks simultaneously, unlike in RAID where you'd be limited in IOPS and network bandwidth to a fixed set of disks in the RAID array.
That probably sounded confusing but it's a good topic for a blog post once we get around to it.
You might be interested in a paper Microsoft published a few years ago, entitled "Erasure Coding in Windows Azure Storage", which describes some similar concepts in greater detail:
Hey that is cool. I worked on the first commercial disk array at Thinking Machines Corporation in 1988. We used Reed-Solomon encoding because we didn't trust that the drives would catch all the errors (they did). Good work solving some of those bandwidth constraints in rebuilding the data.
John (Smitty) Hayes
What's it like working with Rust full-time? Is it similar to using any other language for a job? Do you find yourself enjoying coding more? Do you get unnecessarily caught up in micro-optimizations for things you wouldn't blink at in Go/Java?
It's only covering a few use cases and doesn't go into too much detail and shows example code but it seems like using TLA+ has been beneficial for them.
> If a bunch of people shared some files via Dropbox, the company stored the files on Amazon’s Simple Storage Service, or S3, while housing all the metadata related to those files—who they belonged to, who was allowed to download them, and more—on its own machines inside its own data center space.
I'm surprised at this. I would have expected the opposite: using AWS for the application and metadata but managing your own storage infrastructure. Much like how Netflix runs on AWS but streams video through its self-managed CDN. Can you shed some light on why it was designed this way?
Not related to Magic Pocket, but when the article talks about Dropbox in house cloud, are they saying that you have your own instance of some minimal cloud-computing services? If you're permitted to disclose, I would love to know whether its based off OpenStack.
No filesystem - the rust codebase directly handles the disk layout and scheduling.
Our previous version of the storage layer ran on top of XFS which was probably a bad choice since we ran into a few XFS bugs along the way, but nothing serious.
Lazy answer but we'll blog about this in the next month.
On a high level it's variable-sized blocks packed into 1GB extents, which are then aggregated into volumes and erasure coded across a set of disks on different machines/racks/rows/etc. We also replicate cross-country in addition to this. Live writes are written into non-erasure-coded volumes and encoded in the background.
The volume metadata on the disks contains enough information to be self-describing (as a safety precaution), but we also have a two-level index that maps blocks to volumes and volumes to disks.
Live writes are written out with 4x redundancy in the local zone, then asynchronously replicated out to the remote zone. Some time later, it is erasure coded into a more space-efficient format, independently in each zone.
The word "cloud" loses all meaning in this article.
"The irony is that in fleeing the cloud, Dropbox is showing why the cloud is so powerful. It too is building infrastructure so that others don’t have to. It too is, well, a cloud company."
Wait ... so using AWS is "cloud", having your own servers is "cloud" too. Everything is cloudy!
Was discussing "in the cloud" with my wife yesterday, and I said "It just means on some company's servers." Which suddenly de-mystified the whole concept for her.
Dropbox is clearly a cloud company to its users. Whether or not they use a generic cloud, or maintain their own systems, is an implementation detail to users of the service.
As someone who works for a company whose main business is IoT/M2M/Connected Devices/Embedded Stuff on the Internet, it already has been and it almost meaningless.
It is true that there are two concepts conflated in "the cloud". The first, and by far the most important from a technology standpoint, is the ability to grow and shrink pools of storage, servers, databases, etc. simply by plugging and unplugging hardware. Robust failover, dynamic data replication, all these things are necessary before you can begin having cloud services, and in fact, Google and others had this well before there was such a thing as a cloud.
The second aspect is paying on an incremental basis for someone else to provide the pools developed in the first part. But that's more or less a trivial extension once you've got the first.
What they probably mean is that Dropbox has its own cloud. I'm assuming that they do have some kind of system similar to amazon ec2 to start and kill vms at will, and other similar basic cloud services.
So, just for fun. The video quotes "over 1PB" of storage per box.
I count 6 columns of 15 rows/drives. Might be 7 columns even, there's some panels that aren't fully open on the video.
So, 90-105 drives. I'm guessing they are using 10TB drives, although maybe they can get bigger unannounced drives? Roughly, the math seems to check out.
Quite impressive. Guess the Backblaze guys need a Storage Pod 6.0 soon :P (I know, I know, different requirements/constraints)
Yea :D Though if we used 10TB drives we could get about 450TB in one pod, it would just be hilariously expensive for us to do so. Granted that's not 1PB per pod, but we'd imagine our costs are lower. But yes, different use-cases, and we're working on 6.0 ;-)
Unrelated to the content of the article--I've never seen the oft talked about "anti-adblocker interstitial" before. I was surprised to find that the website blocks viewing of the article entirely because I'm running Adblock.
It's an interesting subject. I'll never click on or be persuaded by ads, so they're not really gaining anything by showing me ads. I'm essentially worthless traffic to them no matter how they cut it.
I do understand the problem they're trying to solve, and I would like to pay for content that I find worthwhile. A convenient microtransaction protocol where I _don't have to sign in or interact in any way_ would be nice. (I don't want to waste time interacting with their bespoke account system / sign-on, even if it is "frictionless".)
"and I typically form negative opinions of the things I see in ads."
Sure, until it's something that fits your world view, and then you don't.
Look, I'm usually the first to (excessively) qualify sweeping generalizations I make with 'generally', 'statistically speaking', 'ceteris paribus' and other weasel words. Yet in the context of pervasive marketing, I don't need to - everybody is swayed by some form of advertising, whether you realize it or want to admit it or not; 50 years of research and billions of dollars spend on that research tell us so unequivocally. But if you don't, it's better you start admitting it to yourself - if only because it gives you better insight into your own internal psychological processes.
Then again who am I to give unsolicited paternalizing advice to strangers.
So the ads have an impression on you... dun dun dun.
I saw a comment about the north korea pics earlier yesterday. It was referring to propaganda. Apparently the purpose of censored speech and propaganda wasnt so much to sway opinion and be cloaked as truth, rather it was an irresistable pleasure for rebels to decry and thereby reveal themselves. You might think that a deliberate attitude toward advertising can defeat it but the subconscious does not answer to your control :-)
Yeah this stuff is getting annoying, my organization's firewall blocks ads as they consider them security risk so there's really nothing I can do about it. I guess I should just get back to work sigh
Disappointing that you can't even view it with "Disconnect" enabled. I'm ok with seeing ads, but not ok with sites sending my data off to 15 different advertising companies every time I load a page.
According to disconnect that one page sends data to 15 different advertising sites, 15 different analytics services and many other content services. So much for fighting for their readers privacy online.
How do you know you are never influenced by the ads you see?
Also, Google Contributor network let's you block any DoubleClick ad, while still paying the publisher for the page view, so that might get what you want.
Now that Golang is making headways at Dropbox, I guess Python codebase will diminish in its importance...
I wonder how Guido Van Rossum feels about it. First he was at Google but they created Go and he left to Dropbox which was a large Python shop, now they are moving to Go too.
I probably wasn't sufficiently clear in my other message re Golang:
- Python is our primary development language for most stuff at Dropbox.
- Mobile development and UI code use whatever is appropriate for each platform.
- Go is the primary language for Infrastructure, meaning fairly deep-backend stuff: databases, storage systems, message pipelines, search indices etc.
- Rust is used on Magic Pocket (which is within Infrastructure).
- We still have a bit of C++ code floating around but there's not much new development in C++ within Infrastructure. C/C++ are still used for common libraries for mobile development however.
Its an amazing remarkable feat indeed to move all those bits live to another location ! But seems contrary to what Netflix did (move everything to AWS ! - http://www.eweek.com/cloud/netflix-now-running-its-movies-ex...) I guess they have their specific usage and reasons ?
Both companies control the technology that most impacts their business.
Dropbox stores quite a bit more data than Netflix. Data storage is our business. Ergo, we control storage hardware.
On the other hand, Netflix pushes quite a bit more bandwidth than almost everyone, including us. Ergo, Netflix tightly manages their CDN. That's where they really focus their technical work. Their storage footprint is smaller and less important to optimize to the extreme.
The open-source alternatives to S3 have a long way to go, especially since AWS S3 is so simple and reliable. I ran Openstack swift in production once upon a time and I remember the entire system coming down because the the rsyslog hostname did not resolve. Ouch. I'll let somebody else work out those bugs.
Some requests for the DropBox Diskotech tech blog series:
For which datacenter cooling system are the Diskotech storage pods designed? Hot aisle cold aisle? How evenly can the disks inside the Diskotech be cooled? With this question I try to ask, how good is it in keeping all drives cool? For example for the theoretical case where all disks in the Diskotech are dissipating identical heat, how much variation is there in drive temperature at roughly 25ºC intake temperature? How much power is consumed for cooling (despite that it will be fractionally low compared to what the disks will consume)? Is there any drive idle optimization done or is the expectance that not any disk will reach its idle (non-rotating) state ever? Is there any optimization done inside a Diskotech to reduce the (inrush) current surge when connecting the machine to power?
I'm a recent Dropbox Pro subscriber -- I've been a user for many years.
Really glad to see what's been going on from behind the scenes, and I'm looking forward to seeing what the future will bring to the front end of Dropbox.
Q: Did the Dropbox devs working on the second version of Magic Pocket encounter any language stability issues with Rust? Did updates to the core language ever break existing code?
We probably "pulled forward" every two months or so. Back in early 2015, sometimes we'd have breakages that took a bit of work to remedy. But post 1.0, the language has been very stable.
As usual, we actually have more challenges pulling the libraries forward than the language.
From a business sense, this is a great move. Amazon's cloud storage offerings are pretty expensive, even with various deduping strategies in place, Dropbox needed both store and move in and out massive amounts of traffic. If DB had reached the point where they could staff the extra over head of doing it themselves, and figure out how to spread the hardware cost out well, it will give them more pricing flexibility in the near future.
Yev from Backblaze here -> we'd be curious to hear how! A lot of folks are looking for quick migration assistants for our B2 service, that's pretty fast!
We have a big fleet of what we call "backfill nodes" which handle the transfer but the most difficult component of the transfer is just the network capacity. We worked pretty closely with Amazon here since we have a long-standing relationship and a lot of data transfer between the two companies.
We might blog about it, these particular tools probably aren't very amenable to open sourcing. They've heavily dependent on in-house Dropbox infrastructure.
Btw. that was a typo, I meant over "half" a terabit of data transfer. You get into bigger numbers than this when you start talking about aggregate traffic.
If you are moving bits from $External_DC to AWS, your best bet is to colo inside Equinix (or equivalent) and use their cross-connect to AWS service. If you have 100 fiber interconnects between you and AWS, you can move a lot of data (it becomes an interesting programming problem to figure out how to saturate that much fiber consistently).
In terms of your customers getting data to you, again, fiber interconnects inside the DC are your best bet. Colo'ing is the fastest way to move bits because it relies on arteries, not capillaries, for moving bits from place to place (no last mile problem).
I am curious to know, with so many disks densely packed in a 4U configuration, I am guessing there is definitely increased heat generation and not to mention vibration. How do you handle these? Also, does it have any effect on MTBF?
Yeah, our hardware teams put a lot of qualification time into hardware profiles before we buy in bulk. And part of what we test is power utilization, heat, etc, under normal software loads vs extreme loads, to make sure we don't exceed power budget, don't spin everything up at the same time, etc. This process can take months.
A lot of the system design is about talking closely to vendors about MTBF for specific loads, and we use a lot of metric data to characterize our loads accurately in those calculations. Then, of course, we measure once we're in the field to make sure we were on target, so the next round of estimations is better.
It is indeed scary to watch a storage node pull 1.5-2 kW at power-on. I think my eyes popped out the first time I watched the PDU load dance around like that.
I'm done with Wired: cancelled its subscription a couple months ago (after many years), now they demand I login to read their web site because I use ad blockers.
Done!
> So, in the middle of this two-and-half-year project, they switched to Rust on the Diskotech machines. And that’s what Dropbox is now pushing into its data centers.
1. Dropbox moved from AWS to its own datacenters after 8 months of rigourous testing. They didn't exactly build a S3 clone, but something tailored to their needs, they named it Magic Pocket.
2. Dropbox still uses AWS for its European customers.
3. Dropbox hired a bunch of engineers from Facebook to build its own hardware heavily customised for data-storage and IOPS (naturally) viz. Diskotech. Some 8 Diskotech servers can store everything that humanity has ever written down.
4. Dropbox rewrote Magic Pocket in Golang, and then rewrote it again in Rust, to fit on their custom built machines.
6. Reminds people of Zynga... They did the same, and when the business plummeted, they went back to AWS.
7. Not a political move (in response to AWS' WorkDocs or CloudDrive), but purely an engineering one: Google and then Facebook succeeded by building their own data centers.
> Dropbox rewrote Magic Pocket in Golang, and then rewrote it again in Rust, to fit on their custom built machines.
Actually, full disclosure, we really just rewrote a couple of components in Rust. Most of Magic Pocket (the distributed storage system) is still written in golang.
> No word on perf improvements, cost savings, stability, total number of servers, amount of data stored, or how the data was moved.
Performance is 3-5x better at tail latencies. Cost savings is.. dramatic. I can't be more specific there. Stability? S3 is very reliable, Magic Pocket is very reliable. I don't know if we can claim to have exceeded anything there yet, just because the project is so young, and S3s track record is long. But so far so good. Size? Exabytes of raw storage. Migration? Moving the data online was very tricky! Maybe we'll write a tech blog post at some point in the future about the migration.
Yup, Dropbox Infra is mostly a Go shop. It's our primary development language and we don't plan to switch off any time soon.
We're always about the right tool for the job tho, and there are definitely use cases where Rust makes a lot of sense. We've been really happy with it so far.
At a high level it's really a memory thing. There are a lot of great things about Rust but we're also mostly happy with Go's performance. Rust gave us some really big reductions in memory consumption (-> cheaper hardware) and was a good fit for our storage nodes where we're right down in the stack talking to the hardware.
Most of the storage system is written in Go and the only two components currently implemented in Rust are the code that runs on the storage boxes (we call this the OSD - Object Storage Device) and the "volume manager" processes which are the daemons that handle erasure coding for us and bulk data transfers. These are big components tho.
The really big deal is memory management. There's no GC, and there's pretty precise memory control, and it's not the Shub-Niggurath that dealing with C++ is.
In fact, just think of Rust as C++ for mortals. :)
We still have a ton of Python. James is referring to the infrastructure software layer--storage services, monitoring, etc. That particular part of Dropbox is mostly Go.
But our web controller code, for example, is millions of lines of Python. And we use Python in lots of other places as well.
I had to count carefully, but it appears you're claiming 12 9's of durability for magic pocket, which seems like a subtle jab at S3's 11 9's.
I think both durability numbers would be fine for customers, but I've also wondered about the math behind AWS S3 durability for a while, and how you would prove statistically that 11 9's was even possible.
I'd imagine that if Backblaze is realizing great cost savings building their own storage pods from commodity off the shelf components, Dropbox's costs we're even lower per GB. Well done.
Yev here -> One of the reasons we started opening up about our Backblaze Pods and Hard Drive stats was so others would do so. We approve this message :D
> Dropbox still uses AWS for its European customers.
We haven't publicly launched EU storage yet but will be doing so later in the year.
> Dropbox hired a bunch of engineers from Facebook to build its own hardware heavily customised for data-storage and IOPS (naturally)
Facebook and Google and startup folks and people from random other places.
Our IOPS demands are reasonably modest on a per-disk basis which is why we skew heavily towards storage density. This is a different workload than you'd find at some of the other big players, hence a fairly custom solution.
> Not a political move
Definitely. AWS are great, we love working with them and will continue to do so.
How much of your cost savings was due to the lower IOPS requirement?
Also, was the S3 "infrequent access" tier a response to customers like you or was your special bulk pricing already taking into account your low IOPS demands?
At the end of the blog post, they mention that they're working on creating the ability for European companies to store data in Germany if requested. This is interesting as the implication is that European businesses don't see the US as a safe place to store their data anymore.
It's not about safety, it's about EU privacy laws and Safe Harbor. It is desirable to store the data in-country to avoid the hassle of requiring/finding a provider with an EU approved Data Protection Agreement.
It would seem to me that if you're primarily in the business of storage, you should go down the stack as far as you can. Outsourcing to AWS leaves you at parity to anyone else who can do the same.
If Box is in the "Business Services" business, then perhaps it's different.
Oh dear I didn't realise Dropbox had invested all of that time and money moving into their own data centre. From my perspective the future of Dropbox looks bleak. Mass storage with Amazon is much cheaper [edit: from a consumer perspective]. I know Dropbox has superior software that works (as opposed to the poor apps by Amazon and Google) but I imagine a lot of people are like me i.e. Store most of the stuff at the cheapest location and use Dropbox just for docs that you want to sync on multiple devices. Total income from consumers like me equals 0.
Dropbox also had that email app didn't they that they recently announced was closing down - mailbox if I recall correctly.
Can anyone convince me that this move by Dropbox isn't going to end very badly for them?
EDIT: downvoters - is HN unable to have a debate about whether this was a smart move or not.
> downvoters - is HN unable to have a debate about whether this was a smart move or not
I doubt the downvotes are in opposition to discussing it. I think it's your poor framing of it. You basically say, "these guys are doomed because I imagine things". It's not other people's job to argue you out of your errors.
If you'd actually like to start a discussion, try saying something like, "I don't understand why X" or "How will Dropbox overcome factor Y". When you come out swinging, you start an oppositional dynamic, and downvotes are a common response to an aggressive opening that isn't so compellingly put that people feel it's worth responding to.
> I imagine a lot of people are like me i.e. Store most of the stuff at the cheapest location and use Dropbox just for docs that you want to sync on multiple devices
I don't believe that's a correct intuition. You're describing optimizer behavior, but for most things people are saticficers [1].
I happily pay Dropbox $100 a year to make a problem go away. Is it the best deal? I don't care. I'm not going to mess around over $0.27 per day. For me it's magic syncing and backup for all my important stuff. Using Dropbox may not be cash-optimal, as I'm currently paying something like $4 per GB/year. But for this I'm not an optimizer, I'm a satisficer, and as long as Dropbox maintains my experience of perfect reliability, I'll keep paying them.
It is hard enough to get staff to use DropBox at all, let alone optimise the spend.
Most of the world is not HN readers, it is McDonalds workers (gross generalisation for affect, not accuracy). Dropbox is the greatest tool ever when dealing with the vast majority of workers, because it just WORKS, without a lot of explanation. Work in this folder always or get written up. DropBox is still my favourite SAAS service, and every time a co-worker loses a file I just want to punch them.
> Oh dear I didn't realise Dropbox had invested all of that time and money moving into their own data centre.
We've had our own datacenters for a very long time; this project just represents moving "blob storage" into our own datacenter rather than just metadata.
> Mass storage with Amazon is much cheaper
As the article says, in Dropbox's particular case this is very untrue. Although I agree with your general point that, absent having something like Dropbox's scale/resources, just using S3 is probably your best bet.
> Can anyone convince me that this move by Dropbox isn't going to end very badly for them?
So, wrt "ending badly", the project has already happened. It's more efficient, faster, more flexible, etc. So I can say with some confidence it won't end badly. :-)
Sorry I think you misunderstand me. Technically it sounds like a great achievement. Well done! Ending badly I mean that in 5 years time Dropbox will be left with a load of servers and a business model in tatters. It's the economics I think will end badly
Also I am sure the in house data centre looks cheaper to Dropbox - but now they have their own hardware on the balance sheet. But I meant cheaper from a consumer point of view - I get unlimited storage at Amazon for $60 a year.
The vast majority of businesses around the world have "assets". It is a universal practice to depreciate those assets over their expected lifetime. The difference between purchase price and resale value is then treated as a normal business expense over the course of those years. So when the servers lifetime is up there are no "load of servers" to worry about. You throw them out (or re-task them) and get new ones.
These costs are known and planned for. Dropbox wouldn't do this without running the numbers through vast herds of accountants.
Now here is the kicker. Amazon does this too (but slightly less due to economies of scale) and then makes sure their billing covers this.
> but now they have their own hardware on the balance sheet
i don't know if this is true or not, but it isn't at all necessary.
you can just buy everything on an operating lease for a fraction of what amazon or any other provider charges and write the payment off without any sort of depreciation schedule or hit to your cash or unnecessarily grow the balance sheet/liabilities.
how do you think it's possible that you can easily get a $15/month dedicated server?
I don't understand your concern. Fundamentally, if you have large enough consistent need for storage/VMs/Any non proprietary resource then AWS is not the lowest cost option by a long shot. This is not at all a controversial statement.
Even taking into account depreciation, administration, maintenance etc, if you have a large enough consistent need amazon is not the lowest cost option by a significant margin. This isn't a controversial statement.
But presumably Amazon benefits (saves money) from making more use of hardware resources. It has to have some spare, but not as much spare as a comparable group of non-AWS users would have in total....
Also, presumably, not all the AWS users are awake at the same time ;-)
That doesn't have to be true. Amazon or one of their competitors could provide a discount by locking into multi year discounts (e.g. reserved pricing).
The cloud providers are in a cut throat business (mitigated somewhat by value added services), so the price will bob along near cost (though they may eak out more profit on some work loads compared to others).
>in 5 years time Dropbox will be left with a load of servers and a business model in tatters. It's the economics I think will end badly
Your main argument seems to be that Amazon, Microsoft etc will undercut Dropbox on price which is fair enough. However Dropbox has done well so far offering better service and I can see that continuing. The better service thing is mostly about the people running the services and Dropbox seem good.
To see how they are moving away from commodity storage check this out:
That doesn't matter, they have gained a good foothold in SMEs which is where the real money is.
> Dropbox also had that email app
That was a peculiar acquisition, I guess more of a acquihire for a team that made some waves in UI design. They would have folded anyway, Google has caught up with the "swiping todo" concept.
> Can anyone convince me that this move by Dropbox isn't going to end very badly for them?
A company on that size has many metrics they can use to define success. Owning your metal is a big investment, but it also brings a level of control and performance that you will never get from outsourced infrastructure. Google became Google without AWS ever entering the picture, after all.
I think these are the first moves in a wave of "de-cloudification" by the fields' own pioneers. The longer you've been on the cloud, the more you're intimately aware of its limits and its costs. No technology is a silver bullet.
Their service is primarily for consumers and many large companies won't use them, favoring an in-house solution or an offering from a specialized company. That's a dangerous position to be in, as consumers are fickle and are liable to drop the service at a moment's notice.
Dropbox is probably trying to position themselves as a secure data storage solution for larger organizations. Being on Amazon scares away a lot of people. I'm sure we'll hear about some new paid services from them which will be compliant with all manner of regulations. This will open them up to huge multi-million dollar contracts and they'll get baked into some big companies for years to come.
> Dropbox is probably trying to position themselves as a secure data storage solution for larger organizations. Being on Amazon scares away a lot of people.
I don't think the people scared by Amazon would not be scared by a company with Condoleeza Rice on the board. Amazon is already compliant with all those regulations you speak of -- they host large swaths of USGov infrastructure, after all.
More likely, DB people have simply come to the realization that, at their scale, AWS is extremely expensive for what it delivers. Being a technology company, they are not scared by the thought of building and maintaining their own iron in order to make substantial savings. Their core business is storage, after all.
"Dropbox is probably trying to position themselves as a secure data storage solution for larger organizations. Being on Amazon scares away a lot of people. I'm sure we'll hear about some new paid services from them which will be compliant with all manner of regulations. This will open them up to huge multi-million dollar contracts and they'll get baked into some big companies for years to come."
And provided your management costs are lower than Amazon's profit on S3.
There's an infection point somewhere at which owning your own hardware and paying someone to acquire, build, manage, and maintain it becomes cheaper than renting from someone who does the same thing at scale and makes a profit off of it.
Dropbox is probably there, but many small web apps are not.
Keep in mind that that doesn't just result in more costs : it results in limits on scaling.
Suppose you are on S3 and you can serve a customer x Mb/$. Now you're limited to products that you can charge more for. Suppose you get data served to customers on dedicated at x/10 Mb/$ (easily doable, and compared to S3 I bet x/50 would be doable).
Isn't this how products like facebook video, vimeo (and thousands of porn sites) survive ? If you calculate how much it would cost to serve 20 Mb out from EC2, you would never ever be able to pay that using advertising revenue, even if you got as much as TV gets.
So that reduction in price that comes from not using the cloud doesn't just go into your pocket : it enables new business models that just aren't accessible to you otherwise.
Also can we stop pretending that the alternative to the cloud is buying servers from HP and colocate them ? That's simply not true. There's any number of projects that would enable you to slowly scale up that aren't EC2. It's more work, certainly. But it's worth it at quite small scales.
And in some ways (e.g. geographic reach) clouds simply don't match existing dedicated offerings. Not now, and at a 20% yearly price reduction it'll take them decades to match dedicated server rental.
Obviously I'm not claiming clouds don't have advantages. But you're paying quite a high price for them atm.
Currently, S3 will provide bandwidth out for 300TB/month at ~$21,000.
At our web host the same bandwidth would cost $1800.
At our CDN, the same bandwidth would cost $3585 to $4791 depending on the number of points of presence you'd require (6 vs 17).
S3 and its extreme availability profile is nice, but its not cost effective when the difference between pricing vs the lowest-priced option is almost $20,000 a month.
To me, the main alure of S3 was never amazon's architecture or HA, but that you no longer had to manage your storage servers and add capacity in a stepwise process. 7 years ago, to do this you were stuck with GlusterFS or even MongoFS.
Today we have OpenStack, Ceph, RiakCS and others providing battle-tested open-source solutions that anyone can run so there's much less of a reason to go S3.
I like to compare Amazon to Akamai with the statement of "yes, they're the best or close to it; but do we need the best?"
it's entirely dependent on whether or not you know what the hell you're doing in a datacenter. if you don't know what you're doing, you'll never hit any such point.
Having done the math on this project in a previous life, I would also add that having to run app logic on EC2 instances and the outbound network costs are the true financial killers for S3.
S3 raw price-per-gig is somewhat competitive with what Dropbox built, but the ancillary things around it are not remotely competitive.
No normal consumer is writing directly to S3, so the entire premise of your debate is kind of moot, that's why you're being downvoted.
You're missing something here, which is that DropBox are probably now spending roughly 10-20% of what they were paying Amazon on an annual basis. The savings probably grow as DropBox grows. Those savings over your hypothetical 5 years could probably keep DropBox on life support for another 5 years.
Buying off the shelf hardware providing an s3 style API saves us a significant amount of money, and while our scale is large, it isn't a fraction of what Dropbox is.
I think this is only true at mid sized usage. Too small to negotiate with AWS (and have an impact on their numbers) and still big enough to matter to your budget. Dropbox should have been able to get a better deal.
Why would you reinvent a piece of technology offered by various cloud providers? It doesn't make any sense, what a waste of engineering resources (fun exercise though). They should have been able to reach some middle ground with AWS about pricing.
I really doubt their in-house storage backend will be cheaper compared to the lowest rate they can get from one of the cloud providers.
Because having your entire business model depend on the pricing whims of another business (which in the grand scheme of things is a competitor, btw) is unsustainable. Getting out of AWS is exactly the right move for Dropbox's long term health.
There are many cloud hosting providers and they are competing intensely.
AWS marginal cost increase for supporting Dropbox is far below the cost of Dropbox building and maintaining their own solution.
Given these facts they should be able to negotiate a far better price/cost than their current solution of building it in-house.
There is nothing unique about their requirements which justify this move. It's a really weird decision. Probably we're missing something here. This must be part of some larger strategy they are executing.
As jamwt mentioned above, storage is simply the most critical element of their business, so it makes sense to control it as tightly as possible , similar to what Netflix does with their CDN.
The cloud is for stuff you don't care too much about.
{kind=link}
{kind=link}
There is a necessary abridgement that happens in media like this, wherein a few individuals in lead roles act as a vignette for the entire effort. In particular, on the software team, James and I are highlighted here, and it would be easy to assume we did this whole thing ourselves. Especially given very generous phrasing at times like "Turner rebuilt Magic Pocket in an entirely different programming language".
The full picture is James and I were very fortunate to work with a team of more than a dozen amazing engineers on this project, that lead designs and implementations of key parts of it, and that stayed just as late at the office as we did during crunch time. In particular, the contributions of the SREs didn't make it into the article. And managing more than half a million disks without an incredible SRE team is basically impossible.