I'm always surprised by how thoroughly uninterested the Haskell and Rust communities are in learning from the Ada/High Integrity Software community.
Here you have people who are actually doing what you purport to be interested in (creating defect-free code) who have a great deal of experience and a great many insights from actually putting their code into avionics bays knowing that thousands of lives are depending upon it.
But they're not valley programmers. They skew older. Heck most of them don't even live in California. And they don't "get" what's so amazing about category theory as a programming paradigm so obviously they're morons. Plus they seem to be process-obsessed and that process ain't agile.
Maybe eventually the valley bros will rediscover most of what the Ada programmers already know.
Hm, I find this to be a pretty mischaracterizing view of Rust. Nobody on the core team lives in California. We never talk about category theory. Our average age is mid-30s. And in general, we love hearing about other languages, including Ada.
We're using Rust in building safety-critical runtime software for autonomous vehicles precisely because we do care about these kinds of things for non-R&D products.
We have many experiments showing how trivially easy it is to write MISRA compliant C, that normally passes muster for "safety-critical" in automotive, which is horribly unsafe, but for which analogous Rust fails to even compile.
We're also working to go many steps beyond ISO 26262 in terms of process and process verification. To the point that we're going to attempt to have a formally verified development lifecycle in addition to as much of the software that comes out of it being formally verified as well.
We're not stopping at formal verification for the software or process either due to fairly glaring gaps/shortcomings in the methods available today.
If we are talking about the community of users, the experiences of Ada programmers are likely of no little help to someone working with Haskell. Ada is an imperative language with explicit declarations and mutation everywhere. Its mechanims to help out with safety basically have to do with managing side effects.
> I'm always surprised by how thoroughly uninterested the Haskell and Rust communities are in learning from the Ada/High Integrity Software community.
If you read the paper you would find that the VAST majority of issues were human communication or understanding of the problem. No programming language can fix that.
Rust was started with one overriding goal: make programming on Firefox manageable. And they identified a primary problem: uncontrolled sharing. And they killed it: Rust disallows sharing by default. Everything else in Rust stems from that. "category theory" or any other academic CS is used when it helps the primary mission--otherwise it gets deferred.
> Maybe eventually the valley bros will rediscover most of what the Ada programmers already know.
And yet Ada exists practically nowhere that requires timely deliverables. Funny that.
Much like Lisp, if Ada were such a force multiplier, there would be someone who would use it to make lots of money.
A few years ago, AdaCore's Robert Dewar observed that nobody has ever been killed by a flaw in Avonics software. That's perhaps not a good elevator pitch for a hockey stick startup but it's a good testament to the capabilities and skills of the people in the High Integrity community.
It's true that High Integrity development is not compatible with deadline or budget driven projects.
But there is a lot to learn from the High Integrity community and I think it's a shame that people who claim to be interested in making software more reliable ignore a community with decades of experience doing just that.
> A few years ago, AdaCore's Robert Dewar observed that nobody has ever been killed by a flaw in Avonics software.
While that may be technically correct, I would consider the crash of Air France Flight 447 to be partially an avionics software failure.
Responding to an inconsistent airspeed measurement by disconnecting the autopilot and then dropping into a weird, modal operating state (alternate law) and throwing control over to the very surprised humans counts as a software failure in my book. Having a stall warning that tells you to do the wrong thing is a software failure in my book (the stall warning turned off when inputs were invalid, but then turned back on when the pilots actually made the correct maneuvers because the inputs weren't invalid anymore).
While ultimately the failure for that flight was human error, a smart reaction by the software at any point would have prevented that tragedy. The biggest "smart reaction" would have been to flag the invalid airspeed to humans but don't change anything.
Whoever thought that dropping a suddenly dynamic system into the hands of surprised humans was a useful action should be shot. In reality, nobody thought it. Each individual subsystem had their own failure procedures, and nobody ever tested what happened when they interacted.
> partially an avionics software failure... Responding to an inconsistent airspeed measurement by disconnecting the autopilot and then dropping into a weird, modal operating state
You could write that software in rust to do exactly the same thing.
> If you read the paper you would find that the VAST majority of issues were human communication or understanding of the problem. No programming language can fix that.
At no point did I argue that Rust would have prevented the Air France Flight 447 kind of failure. However, neither would Ada have prevented this kind of failure.
I WAS however taking issue with the quoted "nobody has ever been killed by a flaw in Avonics software".
Ada exists where killing people is not an option for sloppy programming.
The moment software companies start to actually pay heavy fines and are forced to do refunds for sloppy software like in other industries, the situation will change.
Nietzsche's aphoristic style was actually pretty effective. Taleb has this tendency to throw aphorisms out there and wait for his followers to get confused by them, at which point he revises them (or just explains them). It's hard to imagine most authors operating that way.
That's fine, but you're not going to change social mores overnight (perhaps ever). The fact that ride sharing apps are helping is a huge plus in my book.
Bad estimation techniques - eg. guesses without a basis in historical data (most developers don't collect historical data) - are usually wrong. No one would argue this point.
If you do iterative development with intelligent planning and collect some historical data to use in estimates the game changes. First, most of the examples of "unexpected complexity" you gave can now be identified early and factored into your estimates. That leaves the 1% of truly unexpected stuff that you can then deal with as it comes up and factor into your future thinking in a post-mortem. Second, since you now identify risks earlier and can factor them into estimates, most of your work becomes estimable, and with historical data your estimates will improve.
There's even multiple process products around this idea already, but they're mostly used in the "safety critical" industry, see [1] [2].
The SEI work has been around a long time and it has had very limited success outside of academic or very controlled settings. It had its heyday in the late 90s but never really caught on broadly because it is impractical to collect the level of detail necessary, with consistent teams, languages, environments, and practices in a fast moving computing environment.
Personally, I think empowering individuals to control their own lives is an inherent good, so within my personal definition of morality, it makes the world a better place from the start.
However, I'm well aware of the tradeoffs--en masse, individuals will collectively make some pretty stupid decisions (i.e. continuing the destruction of the planet) that might make the world a worse place. We need more than programs that allow personal choice to make the world better--we need education, social change, better laws, funding, etc.
The fact is, there's nobody running the show who could coordinate all of this to ensure that programs that enable personal choice are a net positive. We can only do our part and hope that people in other areas of expertise do their part.
The goal here is to make you happier and more fulfilled as an individual. But beyond that, a happy person imparts more positive energy on those around them, and is often more productive as well. If enough people were able to use such an app to better align their lives with their moral compasses, it's reasonable to expect a net positive impact on society, even if the granular goals vary widely from person to person.
So the interesting thing here is the "majority assent" phrase. All the polls I saw included < 15% of Ethereum stakeholders / hashing power. Some included < 5%, but were taking by many (who already had a chosen outcome in mind) as definitive proof of community preference.
Really this shows that a small group of people plus a core team already leaning in one direction are probably enough to fork the network.
Once we passed the fork block, we had a vote by 100% of the mining power.
The ether vote had the percentages you mentioned, but all elections are decided by the people who show up. Generally we consider elections fair if everyone has the opportunity to vote; whether they actually do is up to them.
that's fine. Those figures just say that many people are ok with whatever. Ultimately: If you don't like it, then you can leave. And if you aren't paying attention, then, well, you obviously don't care enough about that asset.
As the parent poster said, there was a majority consent. Much more than 50% considered that this was okay, they also "joined the fork", so the things that these <15% did were done with majority not objecting.
And also it's quite plausible that if the same number of people, the same people would implement a technically identical hard fork with the same process but with a different "socioeconomic" result and justification, then they wouldn't have gotten the same majority consent that they did in this case.
Perhaps offering some sort of crowdsourced funding mechanism and a reputation system would go a long way toward correcting some of these incentives?
For example, giving authors / organizations a Bitcoin address where they can receive funds from individuals / organizations who want to support their research.
Also, awarding reputation to authors based on the level of peer review their research has successfully undergone (number of peers, level of rigor, etc.), and conversely awarding reputation and funding to those who perform peer reviews. Allowing users to contribute to a peer review fund for individual articles or in general.
All that to say this is very exciting and opens up a lot of new possibilities.
> For example, giving authors / organizations a Bitcoin address where they can receive funds from individuals / organizations who want to support their research.
That's a fantastic idea. Maybe we could call this "depository" of money to conduct research something like, hmmm, what's a good word… a grant?
> Also, awarding reputation to authors based on the level of peer review their research has successfully undergone (number of peers, level of rigor, etc.), and conversely awarding reputation and funding to those who perform peer reviews.
Sounds fantastic as well! Maybe these authors could create like, a website or curriculum vitae where they could list their accomplishment to establish their reputation. You know, they could have a section in their medium of choice that could be titled something like selected peer reviewed articles where they'll list their publications along with their coauthors and the journal it appeared in. Maybe these journals could devise some kind of ranking to measure reputation. Maybe they could call it something like… amount of impact or maybe just impact factor for short. I think this could work really well.
> Allowing users to contribute to a peer review fund for individual articles or in general.
Maybe a general fund should be created to support science! Maybe a national science fund or something, governed by a so-called national science foundation who can vote scientists, engineers, and the like onto their board to steer the allocation of funding.
I really think you're onto something very good here!
> Maybe we could call this "depository" of money to conduct research something like, hmmm, what's a good word… a grant?
Nah, that word is already in use for stagnant allocations of academic welfare to work on bullshit instead of transformative techniques (e.g. CAR T-cells, which NIH refused to fund for years). Need a new word to signify "money that is actually intended to produce results" instead of "a pension for irrelevant tenured senior PIs to pay non-English-speakers below-minimum-wage to work on topics that became irrelevant a decade ago".
> Maybe they could call it something like… amount of impact or maybe just impact factor for short. I think this could work really well.
Ah yes, impact factor is such an amazing tool. It allows "executive" "leadership" types to predict (very poorly, but who cares?) how many citations a paper might receive if it survives the months or years between submission and publication in a major journal. Trouble is, JIF is massively massaged and the COI that Thompson Reuters has in equitably enforcing it is ridiculous.
WARNING: Non-peer-reviewed work ahead! If you're not careful, you might have to apply critical thinking to it!
> Maybe a general fund should be created to support science!
That's a great theory. Perhaps it can be as well executed as the CIHR fund (where study section has given way to "ignore everyone who doesn't suck my dick directly") or NSF (whose yearly funding is dwarfed by the R&D funding at a single company). This approach is working out very well!
You know, if I didn't know better, I might think you were the sort of researcher that fails to look at the details and just submits your most fashionable bullshit to whateve journal at which your pals happen to be editors. I might get the impression that you're the cancer which is killing grant-funded science, which prizes large labs over large numbers of R01 projects, which believes that O&A is an entitlement to take out mortgages on new buildings instead of to pay for the costs of disbursing and administering a grant. But, since the evidence isn't before me, I won't.
It would be nice if you thought a little more carefully about what you wrote. The devil is in the details.
> or NSF (whose yearly funding is dwarfed by the R&D funding at a single company)
If the worst thing you can say about the NSF is that they need more money, that makes it sound like GP has come up with a nice way to allocate the available funding towards particular research projects.
> It would be nice if you thought a little more carefully about what you wrote. The devil is in the details.
Details like how to get "crowdfunding" to put up enough money that "independent scientist" can be a full time job and not just a hobby for the odd few who somehow already have most of the needed lab facilities/equipment?
Also: I still haven't heard (from either you or the previous parent poster) how journal impact factor can possibly be justifiable as a metric for relevance.
Anyone surveying the actual citation distributions at major journals will immediately note that a metric assuming near-normality cannot possibly summarize non-normal distributions of citations. The latter describes nearly all journals, thus even if JIF were not manipulable by stacking, self-citation, and negotiated exclusion of items to decrease the denominator, it would still suck.
Look carefully at the details! This metric is among the most frequently emphasized by researchers who comprise study sections, and it is objectively terrible.
I'm not whining "just because" -- many of the lines in my CV end with NEJM, Nature, or Cell (no Science paper yet). I'm saying that at least one of the commonly accepted metrics for individual investigators is broken. That sort of detail corrupts the entire rest of the system.
I'm also not saying that a direct public-facing system wouldn't have huge potential problems (although it is nice to see attempts like experiment.com seemingly doing OK, and the funders realizing, hey, there are a lot of shades of gray between "utter bullshit" and "exactly the right experimental design for the question being asked").
One of the nice things about talking directly with folks at NIH, for example, is that they recognize there are serious issues with the incentives in place. If they are willing to collect the data and evaluate (publicly, e.g. in Chalk Talk postings) the findings, doesn't that suggest room for the current system to improve?
I take it you're not familiar with "crowdfunding" sources like the AACR, LLS, ASCO, or other professional societies?
As someone who is funded by several of the above, and who noted that their review processes were substantially less bullshit-intensive yet no less rigorous than NIH review (which has many benefits, efficiency not among them), I'm going to go out on a limb and suggest that it's possible.
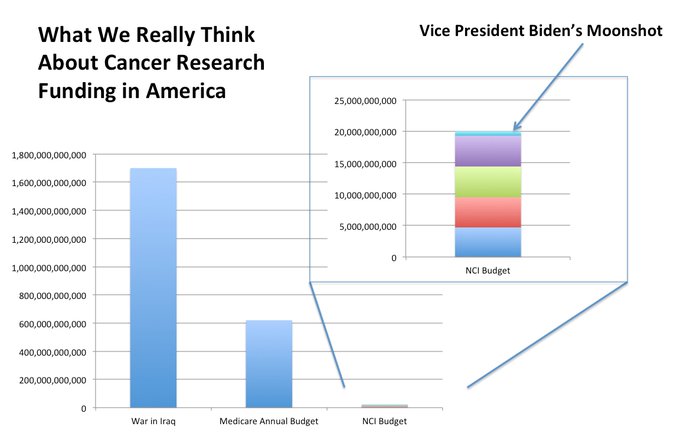
As far as the NSF, they do a good job with what they have, but what they have is not commensurate with what we as a society could stand to spent on science. Even NCI is a far cry from that: https://pbs.twimg.com/media/CmLJzKQWkAAl372.jpg:small
Distributions are similar for various other avenues of funding, and it is quite clear that the overhead & administrative costs requested by many recipient instutions are far out of proportion to actual needs, so the impact of the funding allocations is further reduced.
Thus it appears that a direct conduit from potential patrons to researchers is, in fact, desirable. Otherwise, services like experiment.com would not exist. They're not at the level of an NIH study section (duh?) but they have consistently produced a small stream of usable results that belie their supposed irrelevance. Once upon a time, the Royal Society existed for just such matchmaking: find a rich patron and a promising young scientist and line them up. You've likely noticed that many if not most major universities and "centers of excellence" rely upon exactly this model, supplemented with NIH or NSF grants, to exist. Further modularizing the model so that an administrative hand yanking out bloated "indirects" at every turn is not mandated might not be the worst thing, or (alternatively) being more transparent with said O&A requests, might at least bring some of the bullshit under control.
The public clearly wants accountability. The masses may be asses, but if we want their money, we really ought to be transparent about what we're doing with it.
The difference between professional societies and crowdfunding is that professionals, not the crowd who donate directly, decides which projects to fund. In this sense, I do not see a great qualitative different to government funding agencies --- if you do, please elaborate.
EDIT: And to clarify, in the societies I know, general members do not directly take part in grant decision processes. Rather, the decisions are made by a small panel, possibly together with external reviewers. This is fairly different from crowdsourcing.
It's different from crowdsourcing, but the source and sink for the funds also tend to be more closely related. Ultimately I don't really believe that major initiatives (eg P01-level grants) can be adequately reviewed by anything other than genuine peers.
But by the same token, an exploratory study requesting $30k for field work or sample processing could very well be evaluated by less skilled peers. Actually, I think I'm going to try and shop this to a friend at NIH. I'll fail, most likely, but at least I won't just be whining.
For example, pharma and big donors use the LLS review system as a "study section lite" to hand out grants larger than a typical R01. The paperwork and BS isn't really necessary at that level and just gets in the way. If something like this existed for "lark" projects, inside or outside of NIH/NSF, perhaps more diverse and potentially diversifying proposals would be worth submitting.
To some (fairly large, in the case of ASCO or ASH or AACR, perhaps smaller for LLS or AHA) degree, the dues-paying professionals in these societies are the crowd. I would say they are a middle ground between something like an experiment.com or similar at one extreme, and NIH (which has inordinate purely political input -- ask your program officer!) at the other.
We shan't discuss scams like Komen here, but genuine research foundations can exist along a continuum.
The paperwork burden for an NIH grant (relative to a society grant) is often a large scalar multiple. The accountability is often on a par with, or less than, the typical society grant. It mystifies me why this should be so.
I feel like those fields with highest facility needs / costs would come last if at all. There are many fields that require pretty small amounts of resources for example: Computer Science (I did most of my research on a personal laptop, with other equipment costs <$5,000), Mathematics, Philosophy, Economics, Psychology.
All of these seem very possible to crowdfund with the ultimate goal of unhooking them from perverse incentive systems of typical universities.
at least three of the above are in fact supported by experiment.com backers, although largely as a "bridge" to more traditional scholarly outlets. That said, if you go out and get extramural funding for your work, generally that is the definining characteristic of a successful PI, so...
I wasn't saying the current system is great, there's a lot wrong with it yes I agree. The impact factor thing is also a pretty silly metric to me as well, I agree with you there. The point I was trying to make, albeit sarcastically, was that the system the guy proposed is what we have today just without the extra hoops to jump through. Like I have absolutely no interest in maintaining a Bitcoin wallet or whatever nor do I want anything to do with them. I'll take my funding in dollars or euros or something real and tangible please.
Mostly agreed, although I did consider using an HPC allocation to mine bitcoins & hire work study students. But then it turned out that if you study interesting stuff and write the ad correctly, you'll have to beat them away with a stick. For good measure, I convinced one of our corporate patrons that they ought to pay for one of the students.
As far as extra hoops, it's not clear to me whether endless NIH paperwork bloat and ICMJE declarations are more or less onerous than crowdsourcing type stuff. I tend to think there must be a happy medium, but I could just be naive.
Oooo sarcasm. You're probably right though, the old system seems to be working out pretty well. Besides, science is all about never questioning existing institutions right?
{kind=link}