I'd never heard of this. For those who are time-pressed it's "Cultural materialism as a literary critical practice—this article will not address its anthropological namesake—is a Marxist-inspired and mostly British approach to in particular Shakespeare and early modern English literature that emerged and became prominent in the 1980s. Its emphasis on the historical and material conditions of the production and reception of texts has remained influential, even if its political commitment and interventionist purposes have largely been abandoned and increasingly ignored."
https://www.oxfordbibliographies.com/display/document/obo-97...
Thus far, I have only found LLMs to be as good as StackExchange.
Heck, maybe a little better than that.
There's still some untapped potential.
But, if I try to replace coding with an LLM, I find that, eventually, my directions become more and more specific until it becomes meaningless, if not outright counterproductive to use the LLM compared to just coding things myself.
It's a good learning tool. But, that's where I stop.
What about something like sql queries or Google sheets formulas with odd edge cases. I remember searching Google for 5 - 20 minutes for how to do that specific thing in SQL while with ChatGPT I can almost get the answer immediately. In even stronger constrast Google Sheets formulas. Also Regex etc.
I know SQL well enough to understand whether it looks correct, and I can immediately test it, but queries with different joins, aggregates, group bys can become difficult.
Main productivity boost is of course copilot auto complete. I usually know what I need to write, but copilot just does it faster for me. Doesn't make any off by 1 errors accidentally etc.
E.g. I know I have to write a for loop to do something with an entity, aggregate some data, I know exactly what I should write, but it's just that copilot does these 12 lines of code in 2 seconds, compared to me typing it out. And doesn't make weird typos or errors.
I do backend and frontend, even things like starting to write a component, it is able to fill in a lot of boilerplate to React code.
I start writing useEff --- and it will know what I likely want to do, will fill in rest of the 12 lines of code.
It's an enormous productivity multiplier to me.
I start writing an API endpoint, it usually knows how to do the whole endpoint based on what I name the route, and how other endpoints have been filled immediately.
All of this is quite amazing to me. Especially with side projects, I feel like I can dish out so much more.
Yeah, mind you I do full stack dev with popular frameworks, libraries, I think it works very well under those circumstances. If it was something like game dev with obscure libraries or libraries where API constantly gets changed with each version, it might be worse, but funny thing is that it can also reduce need for using those libraries if you just need simple functions, you might be holding them in your codebase what copilot generated, e.g. leftpad fn. It is easier now to do function leftPa... and let it finish than install the library.
So in theory if you keep fns like leftPad in your repo and it's so easy to do, it would be more future proof, secure, and flexible for the future.
You know you can write "export function le" in TypeScript
and it will give you
Although this here is imperfect since it didn't add types, so still room for improvement. It didn't add types maybe because it wasn't passed the context about being in the .ts file
But I don't have to context switch to Google, or install the library just for this fn.
Or "export function capi..."
Would go to
export function capitalize(value: string) {
return value.charAt(0).toUpperCase() +
value.slice(1);
}
Any CRUD related boilerplate, like let's say I want to do notes,
I start typing type Note = ... It will autofill the usual fields/types for me, which I can then edit to my use-case.
I find that mathematicians tend to have the smallest egos -- eccentric as they may be. I think it's because the difficulty of mathematics reminds one of their fallibility.
In school, I typically found the math and physics teachers to be humbler than the others. Not always, but, I couldn't help but notice that trend.
1. They definitely have self-perception to the extent necessary to "know they're adopting a behavior" if there is something there to "do" the "knowing." They ingest their own outputs as a normal matter of operation.
2. We don't know if there's something conscious there to do the knowing
3. Ego doesn't seem necessary either to being conscious or for self-perception
I suspect you're right, but we don't understand nearly enough about consciousness to be confident about any of these questions.
So... Can I worship an LLM and start my own religion? Because we really don't know if consciousness requires X, Y or Z let alone what a a superior all knowing almighty's consciousness consists of.
To me, LLMs look so superior in some ways and maybe they are the gods now that they have manifested themselves as large blobs of floating point numbers when humanity is mature enough to receive them.
And, after taking a class and watching a whole bunch of RISC vs CISC videos, I still don't know 'why' Apple Silicon is faster at a lower power consumption than Intel's chips.
Lots of reasons, but RISC vs CISC has little to do with it.
Apple have access to the newest and best fabbing processes from TSMC. That alone can put a chip a generation ahead in terms of efficiency. Intel foundries have been struggling for years and AMD only get TSMC's scraps a few years later.
Increasing clock speed is the easiest way to increase performance, but power increases quadratically with clock speed so it's very inefficient. Apple clock their processors pretty low and instead focused on increasing instructions-per-clock, which is generally more efficient but requires more die area. As an example, a lot of noise was made about the M1's 8-wide decoder, twice as wide as contemporary x86 chips, which is an important bottleneck for IPC.
Increasing instructions-per-clock requires much bigger CPU cores, and the dies Apple use for their SoCs are famously enormous. While other chip manufacturers are very conscious of performance/$, Apple's vertical integration gives them wider margins and their customers are much less sensitive to value. So Apple can afford to spend a lot more on bigger chips that are on par in performance but have much greater efficiency.
> Increasing instructions-per-clock requires much bigger CPU cores, and the dies Apple use for their SoCs are famously enormous. While other chip manufacturers are very conscious of performance/$, Apple's vertical integration gives them wider margins and their customers are much less sensitive to value. So Apple can afford to spend a lot more on bigger chips that are on par in performance but have much greater efficiency.
This is the money shot. Margins on Android phones are often in the single digit percentages, they have even had periods where they’re negative. Qualcomm or Mediatek could easily make phat chips but there would be almost no market for them.
I am very curious what the actual performance of the Snapdragon X is going to be. Laptop margins are often just as thin, so it can’t be too expensive a chip either..
Apparently[1] Snapdragon X is cost-competitive with Intel. That article discusses Raptor Lake on Intel 7, which is known to have razor thin margins, but Meteor Lake is reportedly expensive too. Intel's uncompetitive foundries continue to be an millstone around their neck.
I'm sceptical of Snapdragon X's real world performance until these things actually ship. There's a lot of big promises made. Intel promises big too.
Power Performance Area. Area is how much wafer area each chip and the features within a chip use. Apple optimizes for the first two and sacrifices the third. Because they mark up their products a lot, are vertically integrated, and they move millions of devices they can sink a lot of $ into bigger chips made on bleeding edge lithography. More area means bigger caches, higher instruction level parallelism. Hiring lots of top chip designers gets better results too.
They're only large compared to other ARM cores, and Cortex-X4 is pretty close nowadays. AMD and especially Intel have a significantly larger per-core area budget; they have to in order to clock past 5 GHz.
No (less) legacy (smaller chip die area, faster and easier decoder). Paying prime prices for TSMCs newest nodes, one node ahead of everyone else. Bigger (more expensive) caches. Faster memory interface.
Nothing magic.
But the deep integration with better margins and higher end product prices allows Apple to have more expensive CPUs than the competition.
3% is 3% - IPC gains for Ryzen would not be 15% but 18%.
But I do think the benefits are in a faster and easier decoder, and easier memory interfaces etc.
Not a hardware engineer, from a software engineer dropping legacy code makes development of new features easier and more cost efficient, so I can concentrate on other things. But as I've said, I'm no hardware engineer.
A big factor is that Apple buys out all of TSMC's capacity for new process nodes, so they get the smallest transistors that run at lower power and higher speeds.
Notably, Lunar Lake and Apple M4 are made on the same TSMC N3E process and have similar specs so we can perform an apples to apples comparison (sorry not sorry).
People say this, but it’s a trite trivialization of the architectural choices made beyond just the ISA.
When AMD/intel have moved to the same or comparable nodes, they’re not catching up for perf/watt. Lunar Lake will be on the same N3E as M4, so we’ll have to see how it compares.
> When AMD/intel have moved to the same or comparable nodes, they’re not catching up for perf/watt.
They are though? If you compare the Apple and AMD processors that are both on e.g. TSMC 5nm, the AMD ones have if anything better performance per watt. Compare the 7945HX3D to any Apple CPU on the same 5nm process with a similar TDP and the 7945HX3D will generally have similar if not better performance.
But people keep doing comparisons right after Apple is the first to release a CPU on a new TSMC process, and naturally if you don't compare like with like, the newer process is more efficient.
Another reason people keep getting confused is that AMD isn't afraid to go back and release updated models of older cores on their original process nodes. So for example the 7730U is from 2023, it's just a year old, but it's Zen 3 on the 7nm process they've been using since 2019. Meanwhile the "real" 2023 release was Zen 4 on 4nm (e.g. 7840U), but don't pick the wrong one to do your comparison.
"Compare the 7945HX3D to any Apple CPU on the same 5nm process with a similar TDP and the 7945HX3D will generally have similar if not better performance."
Sounds interesting, do you have numbers - s I get this argument often, that on the same node, Apple is so much better.
So here's each vendor's first CPU on TSMC 5nm. This is actually the only process they've both used, and AMD only used it for a couple of models -- they tend to use all the ones Apple doesn't (7nm, 6nm, 4nm vs. 5nm and 3nm), which makes direct comparisons rare. But this is one:
You have to be careful of citing spec-sheet TDPs because AMD allows their CPUs to boost way above the configured TDP where for apple it’s normally obeyed, and usually not reached unless it’s a mixed cpu-gpu load like gaming.
Pointing to TDP as if it meant anything compared to actual power measurements is usually a mistake. It doesn’t mean anything anymore. I really hate it as much as anyone else, I love architectural comparisons/etc... but you have to look at actual measurements from actual devices in a particular workload. Which, again, is very unfortunate since most reviewers don't do that, certainly not for more than one or two workloads.
Cinebench R23 is also not a particularly great test compared to SPEC2017, Geekbench 6, or Cinebench 2024, and most vendors still haven’t switched over even to the newer CB2024. Generally the older tests tend to give x86 a bit of a boost because of the very simple test scenes/lack of workload diversity.
(I was looking at this when M3 Max MBPs came out and 7840HS was the current x86 hotness etc... just very few reviewers with direct CB2024 numbers yet and fewer with actual power measurements, let alone anyone having any other workload benched... geekerwan and notebookcheck seem to be the leaders in doing the actual science these days... save us, Chips And Cheese...)
> You have to be careful of citing spec-sheet TDPs because AMD allows their CPUs to boost way above the configured TDP where for apple it’s normally obeyed
This is more Intel than AMD. AMD will generally stick to the rated TDP unless you manually reconfigure something.
> and usually not reached unless it’s a mixed cpu-gpu load like gaming.
For mobile chips you'll generally hit the rated TDP on anything compute-bound in any way, simply because the rated TDP is low enough for a single core at max boost to hit it. And you'll pretty much always hit the rated TDP on a multi-threaded workload regardless of if the GPU is involved because power/heat is the limit on how high the cores can clock in that context, outside of maybe some outliers like very low core count CPUs with relaxed (i.e. high) TDPs.
> you have to look at actual measurements from actual devices in a particular workload.
But then as you point out, nobody really does that. Combined with the relative scarcity of parts made on the same process, direct comparisons of that kind may not even exist. Implying that the people saying the Apple processors are more efficient on the same process are doing so with no real evidence.
> This is more Intel than AMD. AMD will generally stick to the rated TDP unless you manually reconfigure something.
no, it's generally the opposite. Intel tends to exceed TDP substantially due to boost, and AMD actually exceeds it by greater margins than Intel.
This is consistent across both desktop and laptop, but AMD's mobile SKUs are actually allowed to exceed TDP by even larger margins than the desktop stuff.
I've done the measurement myself with an AC watt meter and CPUs generally hew pretty close to their TDP. 65W CPU under load with a full-system power consumption around 70-75W, with the balance presumably being things like the chipset/SSD and power supply inefficiency.
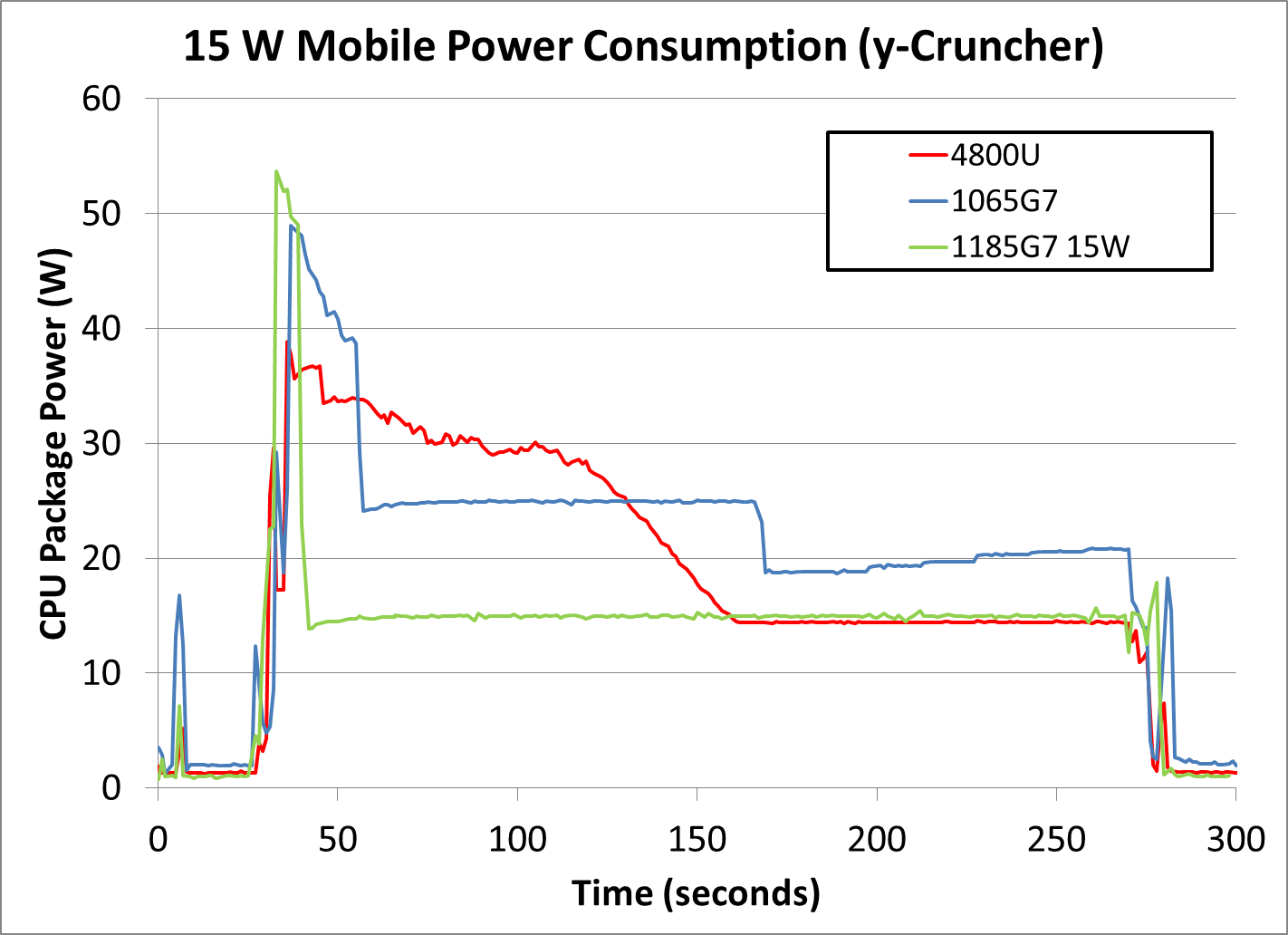
But the TDP is also configurable. It's one of the main differences between different model numbers with the same number of cores which are actually based on the same silicon. The difference between the 4800U and the 4900H is only the TDP and the resulting increase in clock speed. But the TDP on the 4900H goes up to 54W.
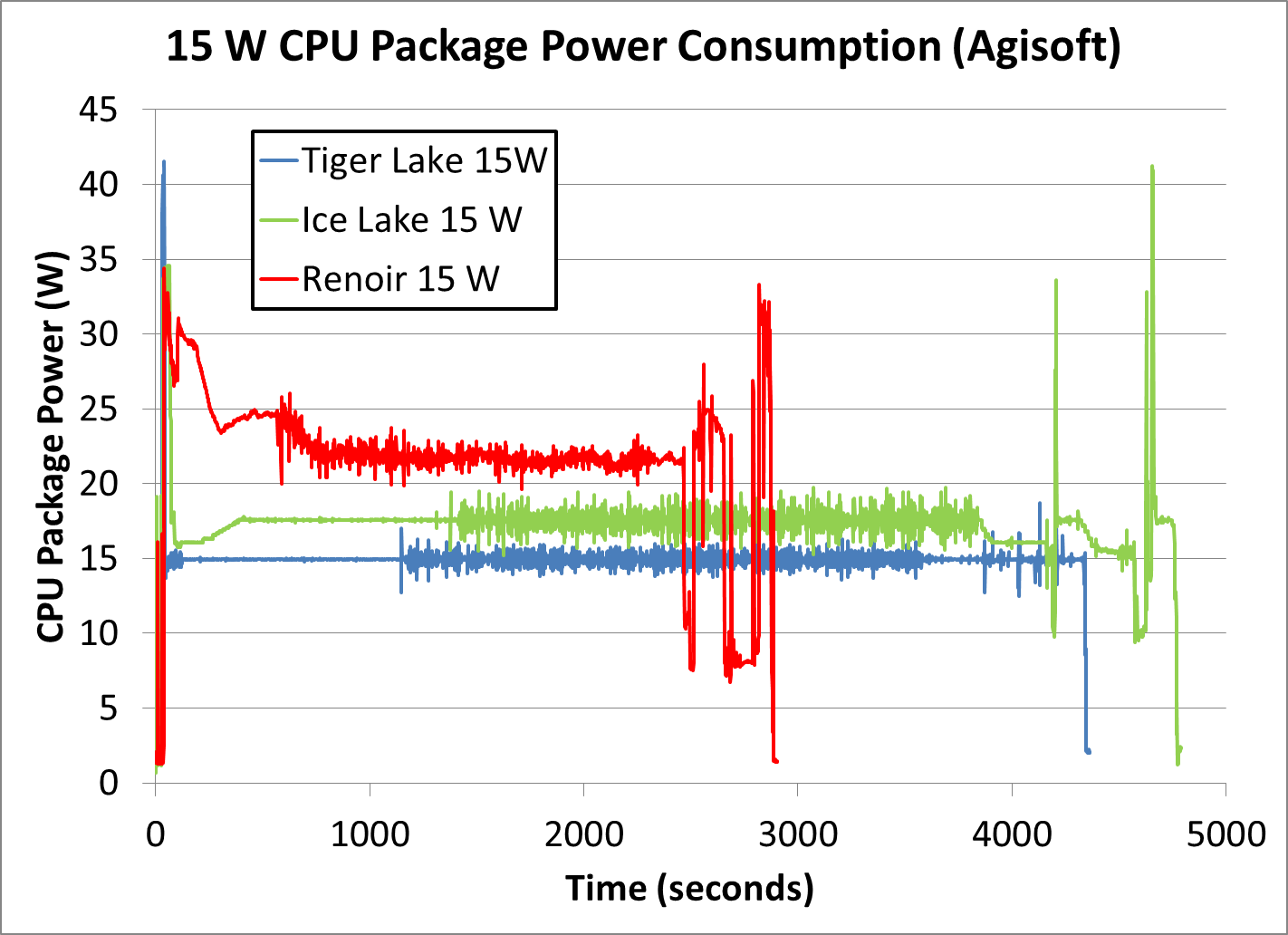
Whereas the TDP on the 4800U they tested there is configurable even within the same model, from 10-25W. And then we see it there using a sustained 20-25W, which is perfectly within spec depending on how the OEM configured it. And there is presumably a setting for "use up to max power as long as not thermally limited", which is apparently what they used, and then combined it with a 15W cooling solution. Which is what you see clearly in the first graph on the same page:
It uses more power until the thermal solution doesn't allow it to anymore.
In the second test it can sustain a higher power consumption, maybe because the test is using a different part of the chip which spreads the heat more evenly instead of creating a hot spot. But this is all down to how the OEM configured it, regardless of what they advertised. That CPU is rated for up to 25W and is only using 22. Obviously if the OEM configures it to use more, it will.
yes, but if the 7945HX3D is running at 112W (75W cTDP + AMD allows unlimited-duration boost at 50% above this) and the macbook is running at 50W cpu-only (70W TDP) then the macbook is actually substantially more efficient in this comparison.
That's why I said: you have to look at the actual power measurement and not just the box spec, because Apple generally undershoots the box-spec for cpu-only tasks, and AMD always exceeds it substantially due to boost. Obviously if you give the AMD processor twice the power it's going to be competitive, that's not even in question here. The claim was, more efficient than Apple - and you simply cannot assess that with the box TDPs, or even cTDPs, because x86 processors make a mockery of the entire concept of TDP nowadays.
(and it didn't use to be like that - 5820K and 6700K would boost to full turbo under an AVX2 all-core load within the rated TDP! The "boost power is not the same thing as TDP" didn't come around until Ryzen/Coffee Lake era - accompanied by ploppy like "electrical watts are not thermal watts" etc)
edit: notebookcheck has cinebench R15 at 36.7 pt/w for M3 Max and 33.2 pt/w for 7840HS, and 28 pt/w for Pro 7840HS (probably a higher-cTDP configuration). Obviously CB R15 is miserably old as a media benchmark, but perhaps ironically it might be old enough that it's actually flipped around to being more representative for non-avx workloads lol.
CB24 MT at 50% higher for M3 Max and CB R23 at 11% higher (shows the problem there with x86 processors on R23). Looking back at Anthony's review-aggregator thing... they're using the highest score for 7840HS I would assume (it's 1k points higher than median on notebookcheck) and also they're probably comparing box TDPs, which is where the inversion comes from here (from parity to a 10%-ish lead on efficiency). Because actual measurements of the M3 Max, from actual reviewers, have CB 2024 at around 51W all-core, and it almost doubles a 7840HS's score there.
And looking at it a little further even that nanoreview aggregator thing doesn't claim 7840HS is more efficient... they rate the M3 Max as being 16% more efficient. Seems that is a claim Anthony is imputing based on, as I said, box TDP...
edit: I’m also not even sure that nanoreview article has the right TDPs for either of them in the first place…
OT: I think it also shows the bad iGPU compared to Apples offerings, so too many x86 laptops have additional GPUs, which reduces battery life (we'll see what Strix brings)
Also both have 16 performance cores, but the Ryzen is faster in multicore. The Ryzen is one year later b/c due to node access/ costs. Doesn't look like "far behind".
There is nothing inherently inefficient about a discrete GPU. Discrete GPUs often have extremely good performance per watt. That's just not the same thing as having a low TDP. Performance per watt is higher when something is twice as power hungry but three times faster.
Not an electrical engineer, my GPU board has lots of additional chips and VRMs, and I do think those should take additional power. All of these are cooled which means they convert power into heat, so I would assume a discrete board draws more power than a SoC. But as I've said, not an electrical engineer (Just some electrical engineering exams at university).
In principle you can shut off anything when it's idle and get its power consumption arbitrarily close to zero.
Discrete GPUs obviously use more power because their use case is when the iGPU isn't fast enough. Hypothetically you can make a discrete GPU with the same performance as an iGPU and it would be no more power hungry. These have occasionally been available, basically monitor cards for CPUs without an iGPU etc. But the ones with a lot of fans and VRMs have them because they do indeed use a lot of power -- which isn't the same as having poor performance per watt, because they're also really fast.
Do you have benchmarks though? TDP is a poor metric for comparison because it varies significantly by manufacturer and doesn’t encapsulate the performance curve at all.
Sorry, I dropped a few words accidentally before submitting and it’s too late to edit it :-( my bad.
I meant to ask for benchmarks across the power spectrum (measured by actual pull not OEM TDP) and off charger. That’s where the x86 processors down clock heavily to keep power in check, and M series pulls ahead because it doesn’t follow suite.
The M series, even at launch, weren’t the king of outright perf, but they were for power to perf.
The M series at launch was already on TSMC 5nm when nothing else was yet.
The problem with asking for benchmarks that actually measure power draw is that somebody would have had to have done them, which hardly anybody does, and specifically on the few CPU models that were made on the same process. So if that's what you want to see, where are yours? Find a comparison that actually measures power draw between two CPUs with similar performance/TDP on the same process, like the M1 Ultra and the Ryzen 7945HX3D.
> That’s where the x86 processors down clock heavily to keep power in check, and M series pulls ahead because it doesn’t follow suite.
That's not really how either of them work. CPUs from any vendor will run at lower clocks under threaded workloads in order to meet their power budget. This is also why the high core count CPUs actually have the best performance per watt -- the cores are clocked lower which is more efficient but you still get the performance from having more of them. And then "race to sleep" etc.
Apple optimizes for IPC and power, that means wide architecture and large die area. The rest optimize for throughput and cost. That means small dies and higher power consumption.
AMD and Intel can do what Apple does and Apple can do what AMD and Intel do, but each company chooses the path they believe it makes more sense for them.
When first launched, the Apple CPUs did about 50% more work per clock cycle (i.e. more instructions executed simultaneously) than the best Intel and AMD CPUs, enabling a 3.2 GHz Apple CPU to have the same single-thread speed as a 4.8 GHz Intel or AMD CPU.
Because the power consumption grows at least quadratically with the clock frequency, having the same speed at a lower clock frequency provides better energy efficiency.
Meanwhile, the difference in IPC (instructions per clock cycle) between Apple and the others has been reduced, but Apple still has a healthy advantage.
The different microarchitecture explains the energy efficiency advantage for single-threaded tasks.
On the other hand, for multi-threaded tasks, the power consumption per chip area is limited by cooling and the energy required to do a quantity of useful work (which is done by switching a certain number of logic gates) is mainly determined by the parameters of the CMOS process used to make the CPU die (assuming that the CPU designers are not incompetent).
So for multi-threaded tasks the better energy efficiency of the Apple CPUs has been determined mostly by the fact that they have been the only company able to use the latest and greatest TSMC CMOS process.
Apple jumped onto the split-core train early on. High performance cores for being good in IPC and low performance cores for multi core workloads with overall low power usage.
Apple has the benefit of controlling the OS, so no scheduler problems.
Intel came later but seems to make good advances, if you look at e-Cores in Lunar Lake.
I predict AMD will go the same route (way bezond 5c), now that x86 also focuses on performance/watt and not peak performance (if you watch the announcements).
Apple jumped onto the split-core train early on, because it was the first having access to more advanced manufacturing processes.
CPUs with big and little cores were not useful for the old "14 nm" manufacturing processes used by Intel for Skylake and its derivatives, because in those processes the power consumption of a core and its speed could be varied in a very large range, e.g. for the extremes of the supply voltage, the clock frequency of a laptop CPU core could vary between 0.6 GHz and 4.5 GHz, corresponding to a variation of the power consumption per core of even 50 times.
Modern processes have more constrained ranges for the optimal operating parameters of the transistors, so it has become better to split the cores into several classes that are designed with different trade-offs between power consumption and performance, instead of attempting to use the same core both at very low and at very high power consumptions.
The decision to use 2 or more kinds of cores to cover the entire curve of performance vs. power consumption, when you can no longer cover it by varying the operating parameters of a single kind of core, is a no-brainer.
While for the CPUs with a small number of cores, like for smartphones, tablets and light laptops, the existence of multiple kinds of cores is needed for optimum energy efficiency, the CPUs for desktops or big laptops with a great number of medium-size cores, like Raptor Lake, have them for a different reason. The big Intel cores, in the quest for maximum single-thread performance, have poor performance per chip area. The medium-size cores have better performance per area, so in the same limited chip area you can put more cores, increasing the multi-threaded performance beyond what would be obtained by filling the same area with big cores.
Nevertheless, AMD has a better strategy than Intel, because their big cores with high single-thread performance and their "compact" cores with better performance per chip area are logically equivalent, avoiding the software incompatibility problems caused by Intel.
{kind=link}
{kind=link}
More than anything else, it has totally changed the way we think -- adversely, I think.
I'm a big believer in cultural materialism.