Do I understand it correctly, that an LLMs are neural networks which only ever output a single "token", which is a short string of a few chars? And then the whole input plus that output is fed back into the NN to produce the next token?
So if you ask ChatGPT "Describe Berlin", what happens is that the NN is called 6 times with these inputs:
Input: Describe Berlin.
Outpu: Berlin
Input: Describe Berlin. Berlin
Outpu: is
Input: Describe Berlin. Berlin is
Outpu: a
Input: Describe Berlin. Berlin is a
Outpu: nice
Input: Describe Berlin. Berlin is a nice
Outpu: city
Input: Describe Berlin. Berlin is a nice city
Outpu: .
One addition is that they don't return just one token, but the probabilities for each token.
You could then greedily take the most probable single token, or select a bit more randomly (that's where temperature comes in) in a few different ways. You can do better still by exploring a few of the possible top options to select a high probability chain of tokens. That's because the most probable next token may not be the start of the most probable sequence of tokens. That's called beam search.
Other than that, things like gpt can't go back and edit what they've outputted, so it's much more like listening to someone talk from the top of their head and writing down everything they say. They can say something wrong, followed by correcting themselves. The fact that the output becomes the input makes it much more obvious why "lets think through step by step" helps them reason, they can do simpler things then see the simpler steps they've already done to answer the more complex parts.
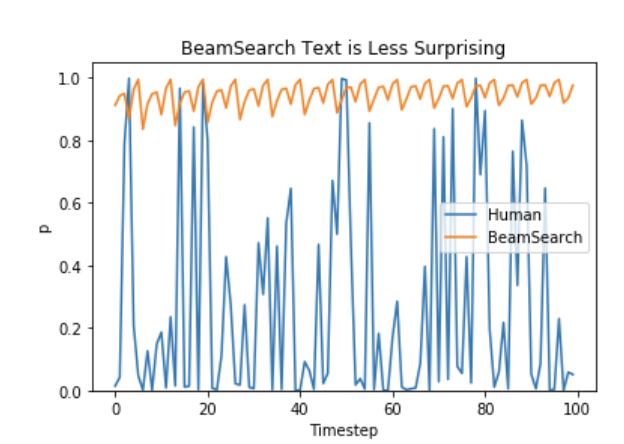
The probabilities are fun (and ability to manipulate/mask/logit bias them), but small nit pick: Beam search isn't popular because it results in less human like text and takes more processing time, as a concept it sounds great in theory, but it's generally worked worse in practise compared to the next token with temperature, and results in text that is not human like, the gap is larger with larger models too, it doesn't get better:
The way most GPT models are set up, they don't edit, but there was a lot of work (made redundant by OpenAI) on using gap filling tasks (masking) to iteratively improve or construct or otherwise edit and formulate logic using the encoder-decoder models of yesteryear - in many ways, I think it would have been more exciting if that approach powered the likes of 'think step-by-step' results.
Oh interesting thank you, I thought they were using it.
There's nice stuff you can do with the probabilities, a shame it's more restricted with the chat models. I hope they add some lightweight thing you could pass with your request to constrain the response.
That's how autoregressive LLMs work. GPTs are autoregressive, but it's not the only way an LLM can work. You can also have other types of LLM, like diffusion based, other types should also be possible.
At the moment, image models are mostly diffusion models while LLMs are mostly autoregressive.
With a few other examples. Google has for example created both an autoregressive image model, Parti, and a diffusion model, Imagen.
Could you or someone else kindly explain how it works for diffusion based LLMs, based on the style of GP? What happens for instance, if I give as input the prompt 'Describe Berlin' or maybe the more fitting 'Berlin city on a sunny day'?
Many diffusion based approaches have been tried for language. I like a diffusion style that goes a bit like this:
* empty string
* Berlin
* Berlin city
* Berlin is a city
* Berlin is a city in Germany
* Berlin is the capital of Germany
* Berlin is the capital of Germany, located in the North East.
* Berlin is the capital. It is located in the North East of Germany.
* Berlin is the populous capital city of Germany. It is in the North East of Germany, by the river Spree.
* Berlin is the capital city of Germany with 3.6 million inhabitants. It is located in the North East of Germany. It's centred on the river Spree.
...
At every step, the diffusion slightly rephrases to add more information content and detail to that of the previous level, by inserting, replacing and deleting tokens.
It is usually more costly to sample from these diffusion style models (which is not the case for diffusion for images, as unlike text, images tend to have a fixed size). But, one might imagine this approach to scale up to generate texts of arbitrary lengths. Just keep on adding more and more detail on your text, and you'll end up with a book or a coherent novel.
I haven't studied diffusion methods in great detail, but my simplistic ELI5 understanding goes something like: during training you gradually add noise to an image, step by step, and then the model learns how to remove the noise at each step. Adding noise to an image is, of course, very easy to do.
But for this approach adding "noise" would be much less straightforward, wouldn't it? You'd have to have some way to work out how to take "Berlin is the capital city of Germany with ..." down to an empty string in a way that marginally removes detail. For some passages this could be rather difficult to do. I feel like gathering training data would be a huge trial here.
Yes, the noising-denoising steps in this approach are summarizing-extending. The idea is that (unlike images) any piece of text lies somewhere on the length scale, like a fractal. You could take the whole text and treat it as a large scale object, or take shorter sentences and treat them on the short scale. What you are right in, is that you need a dataset of things being described twice. Like abstracts and papers, or messages and tldr's.
Another approach I've seen suggested is to start with what's essentially a randomly initialized embedding vector and have a way to turn any embedding vector into text, then what you'd do is diffuse the embedding vector for a number of steps before turning it into text at the end. This is kinda similar to what stable diffusion does with images, but is a bit more tricky to get to work well with text than pixels.
> but is a bit more tricky to get to work well with text than pixels
Interesting. Can't you just start with 4K of randomly assigned tokens and tweak it until it's right (including the tokens for EOF), like they do for images where they start with noise and move towards an image?
This is not my corner of DL research, but my understanding is that pixel noise is far more acceptable in a e.g. 1084 x 1084 canvas than it is when dealing with a sentence of 36 words.
I think you'd start out with gibberish and at each step the output would become more refined, so first you'd maybe see scrambled words emblematic of Berlin, which would then eventually synthesize into a sentence. I think you'd have a fixed length of text, with maybe some way for the model to mark some of it as truncated.
Basically, yes! There are some technical quibbles (tokens don't line up to words, there's recent research on how to make LLMs stateful so they don't need to pass back the entire conversation for every token but can simply initialise to a remembered state), but this is basically correct as to what LLMs are mechanically doing.
The really exciting stuff is how they're doing that! Research into that question is generally called interpretability, and it's probably what I'm most interested in at the moment.
> recent research on how to make LLMs stateful so they don't need to pass back the entire conversation for every token but can simply initialise to a remembered state
I’m very curious about the insights that will give us in to LLMs. My initial instinct is that it won’t work unless you have essentially the entire state remembered since each “point” in the LLM can lead anywhere. I’m imagining an experiment where the task is “Get a person who’s never been to this city before from point X to point Y without describing the destination and while providing as little information as possible”. Giving them the full map with directions is the equivalent to giving the LLM the full previous conversation.
Intuitively there is low-hanging fruit (just provide the directions of single optimized route), but it feels like it gets chaotic quite quickly after that. How many steps could you leave out of turn-by-turn directions before the person is hopelessly lost?
This is based on my current understanding of LLMs so YMMV, but I’m definitely curious about ways we can start from a remembered state.
It's already being implemented into the OpenAI API to reduce per-token API costs. It's not as complicated as I think you're envisioning, you just take the current state in memory of the model at a given token, and then put it in storage when you want to suspend or share the conversation. When you want to continue from that point in the conversation, you just load the state into memory and after inputting your next prompt it works normally. Think of it more like Quick Resume from the Xbox technology stack or the way save states work in gaming emulators.
Those are solid analogies, thank you. I can see how that would work and also a little disappointed because it doesn’t need to give us any additional insight in to LLMs themselves.
We don't now for sure, which is why it's so interesting to research! There are some tantalising hints though, for example the OthelloGPT results (here: https://thegradient.pub/othello/) which show that LLMs can form internal world models and then use them in inference to make decisions. Another interesting result is this one (https://www.nature.com/articles/s42003-022-03036-1), which shows that neuronal activations in some parts of the human brain linearly map to neuronal activations in deep learning models when they are both doing the same task; this doesn't tell us anything about how either is doing what they are doing, but it does suggest that the human brain and LLMs may be doing a similar thing to achieve the same end result. We definitely need a lot more research before we can say anything definitive about this question, but there are a bunch of useful research directions that AI and neuroscience researchers are pursuing.
> neuronal activations in some parts of the human brain linearly map to...
Holy.shi..
As I have been observing the ways AI struggles and the ways it produces output, I’ve had this growing suspicion that LLMs have been somehow showing us things about the human brain, but it wasn’t until this moment that I had any validation of the theory.
If you think about the attention mechanism in LLMs, it may not work the same way as the brain, but there should be some functionality of the brain that also deals with attention. And if you think about that, you might also think that attention has some role in consciousness: you need to pay attention to things to be aware of them, and you need awareness of the self for consciousness, etc...
With LLAMA at least, not just past tokens, but also past states for each layer and each token. So LLama has information not just on the word "Berlin", but also on why it outputted "Berlin".
Yes. "What is the most probable next word given the text so far" is the standard 'language modeling' task from classical NLP where it was done before using Markov chains and n-grams. RNNs then transformers and huge amounts of training data made them output what we see now, versus coherent but otherwise not very impressive text 10 years ago. The large contexts of current models made it possible to generate valid code where you need to remember to close a bracket opened 200 tokens before.
Yes, in the same sense a modern digital camera is a glorified photodiode. In both cases, light comes in, voltage comes out, and we can use it to count how much light came in.
The tokenization algorithms I encountered all had around 50000 tokens, which fits nicely into (and makes good use of) a 16-bit number. Is this just a coincidence or does it have advantages for the token to be a 16-bit representable number?
Are you sure this is ChatGPT? If so, which version? I was under the impression that it's much better. Even the tiny 2.8B parameter LLM (fine tuned RedPajama-INCITE-Chat-3B) in my offline LLM app seems to do better (pardon the shameless plug!).
> Human: Describe Berlin
> Bot: Berlin is a city in Germany. It has been the capital of Germany since 1871 and it's also known as "the city that never sleeps".
Yes. The actual output is all the tokens and a probability for each. You can pick the highest or take one randomly using those probabilities. Depends how creative or deterministic you want it to be.
Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you randomly pick a token according to their given probability. Values in between are also possible.
However, it's important to note that the numbers which the models returns for the next tokens can only be interpreted as probabilities for foundation models. For fine-tuned models (instruction SL, RLHF) the numbers represent how good the model judges the next token to be. This also leads to a phenomenon called mode collapse.
> Challenges in long-term planning and task decomposition: Planning over a lengthy history and effectively exploring the solution space remain challenging. LLMs struggle to adjust plans when faced with unexpected errors, making them less robust compared to humans who learn from trial and error.
While working on smol-developer I also eventually landed on the importance of planning as mentioned in my Agents writeup https://www.latent.space/p/agents . I feel some hesitation with suggesting this because it suggests I'm not deep-learning-pilled, but I really wonder how far next-token-prediction can go with planning. When I think about planning I think about mapping out a possibility space, identifying trees of dependencies, assigning priorities, and then solving for some kind of weighted shortest path. That's an awful lot of work to expect of a next token predictor (goodness knows its scaled far beyond what anyone thought - is there any limit to next token prediction?).
If there were one focus area for GPT-5, my money would be on a better architecture capable of planning.
I don't know how far "pure" next-token prediction can go with planning, although I wouldn't count them out until their performance starts noticeably plateauing. But the tree of thought architecture is a very similar concept to what you're discussing, you should definitely give it a read: https://arxiv.org/abs/2305.10601
It's not everything involved in traditional planning, but it may be a framework to use more traditional planning algorithms on LLM output.
Theyre already noticably plataeuing when it comes to coding, which similarly requires you to navigate tree structures and plan how to connect existing things together using shortest paths rather than inventing things out of thin air.
I would love to see the evidence for plateauing when it comes to coding! Specifically, I'd like to see that new larger models are not achieving performance increases relative to previous smaller models.
I think that in the end predicting words is non optimal , most things we want to do are things that are related to the internal representation of concepts that exist deeper in the layers.
I at least do not want to predict the next token, I want to predict the next concept in a chain of reasoning, but it seems that currently we are stuck at using the same representation for autoregression we use for training.
Maybe we can come up with a better way to construct these chains once we understand the models better.
The weird thing is that training on text encodes information on related concepts.
from u/gmt2027
>An extreme version of the same idea is the difference between understanding
DNA vs the genome of every individual organism that has lived on earth. The species record encodes a ton of information about the laws of nature, the composition and history of our planet. You could deduce physical laws and constants from looking at this information, wars and natural disasters, economic performance, historical natural boundaries, the industrial revolution and a lot more.
and u/thomastjeffery
>That entropy is the secret sauce: the extra data that LLMs are sometimes able to model. We don't see it, because we read language, not text.
How would you represent or interpret the "next concept" if not with some kind of token, though?
Language is a communicated abstraction of concepts, and it would seem that internal representations of those concepts can emerge from something optimized for token prediction. Or at least: internal representations of the speaker to be predicted, including the knowledge they may possess.
Language is indeed communicated abstraction of concepts, but it emerged under a lot of constraints (our auditory system, our brains inherent bias towards visual stimuli etc. ). Predicting in this constrained system most likely is suboptimal.
Imagine translating language into an optimized representation free from human constraints, doing autoregressive prediction in this domain and only than translate back.
As far as I understand current models, this is not yet how they work.
A chain of LLMs can work in that regard, using intermediary prompts that feed answers to the next prompt. Make the LLM build a list of sections, then make it fill them with examples, then make it enrich the text. Maybe a last layer for error correction, clarity, removing mentions of "as an AI model", etc.
> When I think about planning I think about mapping out a possibility space, identifying trees of dependencies, assigning priorities, and then solving for some kind of weighted shortest path.
but that's two things: planning and execution of a plan. The plan is the dependency graph (!), assignment of priorities and shortest path is execution. This is very important in the context of agents, autonomous or not. If you want the agent to self-correct it has to understand that there can be multiple start points or multiple end points (or both) to backtrack and pivot. And as long as it is glorified "next token predictor" it cannot really do that.
Of course some tasks indeed are ifttt style linear-ish flows where next token prediction may prove to be adequate. However, if your agent is incapable of understanding non-linear flows, can it reasonably back off from one true way hen faced with such flow?
There is a fair amount of existing work related to planning in continuous and unbounded spaces under uncertainty. It seems likely some of the existing techniques combined with modern language models could be quite effective. A couple entry points:
I feel this is more of a limit from single scratch pad agents
Having a tasking agent refining prompts seems a much robust approach.
Bonus if it can decompose the required data properly. I'm working on a world database prompt with limited success, but implementing the retrieval with prompts is time consuming and I've not much time. The idea is along the line of "translate the user question in SQL, you have a database of all known facts with a table for each entity" and then you handle the retrieval of each table data step by step.
I think then you'd be able to use the postgres planner as planner, but while I've seen project of postgres retrieving data from random sources I don't remember the specifics.
We probably stay with the next token prediction task for training the foundation. It generalizes really well.
However, transformers are not able to loop. In a fixed amount of computing steps, they need to predict. For long-term planning, we probably want something more recursive/iterative (but that will be harder to train).
Also today we can compensate that with wrappers (eg. Langchain), but ultimately the machine will learn end to end.
> (..) I really wonder how far next-token-prediction can go with planning. When I think about planning I think about mapping out a possibility space, identifying trees of dependencies, assigning priorities, and then solving for some kind of weighted shortest path.
What you really do is more like: you've already formed a half-baked plan before the problem even fully registers, in one cognitive step of pulling the ready-made if somewhat fuzzy graph out of the depths of unconscious - and then you start doing all those things you mention, while trying hard not to be biased towards or anchored to that original plan-shaped blob of words, images and emotions.
I think creating that first plan ex nihilo and putting it into words is exactly what next-token-prediction can do, because that structure of options and dependencies and priorities and a path through them is something that's encoded wholesale in the latent space, and needs to be projected out of it. That's at least my understanding of what current transformer LLMs are good at - encoding every imaginable relationship between tokens and token sequences into proximity in a four- or five-digit dimensional space, and then projecting out of it on inference.
Going beyond that - beyond that first plan prototype, which may or may not be good, is getting increasingly explicit and thus increasingly hard. I think you can ultimately coax an LLM to do all the steps you listed and then some, by walking it through them like infinitely patient parent of a 3 year old - but not within the context window, so you need to split it into multiple invocations. This grows in cost superlinearly, as you'll have multiple results you need to summarize to feed into next stage, and if you're computing enough of those results then they won't fit into context window of the summarizer, so you need to add an intermediate level - and then eventually summaries may not fit in the context window of next step, so you need another intermediate level, etc. Context window is the limiting factor here.
And if you're to use LLM to emulate a mechanical/formalized process, then it's better to just extract structured information from the LLM, feed it to regular software optimized for purpose, and feed the results back. I.e. something similar to LLM+P approach - or similar to any time when you get LLM to "use tools". If it can call out to a calculator, it can just as much call out to some PERT tool to get your list of steps sorted and critical path highlighted.
On a tangent:
> identifying trees of dependencies
Are you sure those are trees? :). My pet peeve with all the hip software used to manage projects and track work in our industry, is that it treats work as decomposing into flat trees. In my experience, work decomposes into directed acyclic graphs (and in certain cases, it might be useful to allow cycles to make representation more compact). There's hardly a tool that can deal with it in work planning context, not unless you step over to "old-school" engineering (but those tools aren't cheap or well-known). Which is ironic, because at least when it comes to build systems, software devs recognize the DAG-like nature of dependencies.
Seriously LLMs are remarkable tools, but they are horribly unreliable. What tasks could such autonomous agent do (beyond what a chat bot, perhaps extended with web access, already does)? I mean which task is so complex one can't just automate it with simple scripting and non critical if it goes wrong to the point of letting an AI LLM do it? BTW, running those models is rather expensive so also the task has to be quite expensive now, perhaps completed by a human.
> I mean which task is so complex one can't just automate it with simple scripting and non critical if it goes wrong to the point of letting an AI LLM do it?
Many of the things that get to deal with unstructured human inputs. Translation, summarization, data extraction, etc. The choice isn't between "reliable code" and "unreliable LLM", but rather "unreliable LLM" vs. nothing at all.
But I think more important aspect is that LLMs are getting quite good at coding - meaning they can be used to automate all the tasks that you could automate with scripting, but it wouldn't be simple, or you don't know the relevant tooling well enough, or you just can't be arsed to do it yourself.
For example, I've recently been using GPT-4 to automate little things in my Emacs. GPT-4 actually sucks at writing Emacs Lisp, but even having to correct it myself is much less effort than writing those bits from scratch, as the LLM saves me the step of figuring out how to do it. This is enough to make a difference between automating and not automating those little things.
First we had outsourcing to Indians, now we have ChatGPT. There is almost a rule of thumb, the less you pay, the bigger pile of shit you get. At least with ChatGPT you can vet it first, but with the market being flush with 1-2 year experience devs, globally vetting will be shit too. I honestly wonder, what will start happening to all these LLMs when the training set will get over-represented with cheap, fast, crappy code written by LLMs themselves. I bet "content inbreeding" will become the topic in the future.
>when the training set will get over-represented with cheap, fast, crappy code written by LLMs themselves
It's already happening. An MIT study came out last week that found that Amazon Mechanical Turk workers hired to do RLHF type training of models were using ChatGPT to select the best answer. And the web being polluted by AI generated content which then gets scraped into Common Crawl and other training data sets has been an issue for a couple of years now.
It’s just a new tool. It isn’t outsourcing. It sounds like the person you’re replying to uses it the same way I do which is basically as a way to quickly brainstorm solutions. It acts as a rubber duck that forces you to explain the problem clearly but it has the added benefit of suggesting mostly correct code. It’s a bit like pair programming where you’re telling it the high level things to do and it’s hammering out the boilerplate while you also review in real time and point out mistakes as they happen.
I think you’re completely wrong about new devs producing worse code with this new tool. On the contrary, they’re going to be able to learn things it took you years to master in a matter of months since they now have a private tutor/mentor/reviewer/domain expert/consultant on call 24/7 for $20 a month.
As for using generated content as input, Microsoft has published a few papers showing that using curated generated content can be used to train specialized models that are more competent in their domain than the original models and the kicker is they didn’t even use humans to curate the content, they just used existing language models!
IMO if you look at how much better GPT-4 is at coding compared to GPT-3.5, and advances in letting GPT test and debug it’s own code, it’s not going to be “cheaper and worse” in the future.
GPT and LLMs will allow good and seasoned programmers to produce better code in time-constrained environments.
At a quick glance the sentiment that the market being flush with newer developers would somehow automatically lead to a dip in technical advancements in the near future seems completely made up. I'd believe it to be the opposite, frankly. I'd see a dip in the near future if a large portion of the more senior engineers died all of a sudden and took their knowledge with them. That's not going to happen.
It all seems to be correlated with growth - as in, the fastest-growing areas of the industry, ones that are hot and considered a career gateway, attracting the largest amount of outsiders - are the biggest circuses on wheels.
It might be that the moat for large LLM providers will be their ability to pay good developers to write good code solely for the purpose of feeding the training corpus of the Coding-LLM-as-a-Service.
Example task that you cannot automate with a basic script - for each e-mail you receive, convert it into json of a given format for a given e-mail type (e.g. for delivery notifications, newsletters, meeting requests and so on). Also, tag it if it relates to a specific area of interest.
Another case that a friend of mine built - summarise a stream of news from Twitter/Telegram so that no news are lost, but duplicates are removed and bad writing is reformatted.
LLMs can be used to propose candidates for chemical, medical, coding, and basically any domain where you got enough data to create a model but it is exponentially hard to search for solutions. They can be the core module in an agent that learns by RL or evolutionary methods - so the quality only depends on how much data the agent can generate. We know that when an agent can do proper exploration like AlphaGo Zero it can reach superhuman levels, it builds its own specialised dataset as it runs.
Imagine a task that can automatically create and post ads on LinkedIn, Adsense, etc. Imagine you can also provide analytics as feedback, thus making each ad more analytics optimized. These are the types of mundane activities I dream of offloading to GPTs until the entire concept of online ads become irrelevant.
I agree, The whole LLM agent stuff is totally overhyped. LLMs cannot really plan and all the workarounds people are currently using are not very reliable. Nice for demos, but unusable for a "product".
How small can be a LLM transformer in order to be able to understand basic human language and search for answers on the internet? It should not contain all the facts and knowledge, but must be quick (so, it's a small model), understand at least one language, and know how and where to look for answers.
Would it be sufficient to have 1B, 3B or 7B parameters to achieve this? Or is it doable with 100M or even fewer parameters? I mean vocabulary size might be quite small, max context size could also be limited to 256 or 512 tokens. Is there any paper on that maybe?
A team at Microsoft Research asked the same question and just published a paper about part of that at least: TinyStories: How Small Can Language Models Be and Still Speak Coherent English? https://arxiv.org/abs/2305.07759
"We show that TinyStories can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters), or have much simpler architectures (with only one transformer block), yet still produce fluent and consistent stories with several paragraphs that are diverse and have almost perfect grammar, and demonstrate reasoning capabilities."
They also trained a TinyStories-Instruct instruction following variant. It looks like the 28M parameter 8 layer model had a 9/10 on grammar and consistency. You could probably combine that with something like Jsonformer or parserLLM to enforce valid formatting.
You don't need a 1B+ parameter model for this workflow, but it helps, particularly for the quality of the final output.
> know how and where to look for answers
The point of calling them Agents is that they don't know how. All the examples, including AutoGPT that makes AI influencers go OMG AGI, are operating in a discrete action space with user-specified hints to select which action (or none at all).
Good read. Currently there are lot of issues in autonomous agents apart from Finite context length, task decomposition and natural language as interface mentioned in the article.
I think for agents to truly find adoption in real world, agent trajectory fine tuning is critical component - how do you make an agent perform better to achieve particular objective with every subsequent run. Basically making the agents learn similar to how we learn when we
Also I think current LLMs might not fit well for agent use cases in mid to long term because the RL they go through is based on input-best output methods whereas the intelligence that you need in agents is more around how to build an algorithm to achieve an objective on the fly - this requires perhaps new type of large models ( Large Agent Models ? ) which are trained using RLfD ( Reinforcement Learning from demonstration )
Also I think one of the key missing piece is a highly configurable software middle ware between Intelligence ( LLMs ), Memory ( Vector Dbs ~LTMs, STMs ), Tools and workflows across every iteration. Current agent core loop to find next best action is too simplistic. For example if core self prompting loop or iteration of an agent can be configured for the use case in hand. Eg for BabyAGI, every iteration goes through workflow of Plan, Prioritize and Execute or in AutoGPT it finds the next best action based on LTM/STM, or GPTEngineer it is to write specs > write tests > write code. Now for dev infra monitoring agent this workflow might be totally different - it would look like consume logs from different tools like Grafana, Splunk, APMs > See if it doesnt have an anomaly > if it has an anomaly then take human input for feedback. Every use case in real world has it's own workflow and current construct of agent frameworks have this thing hard coded in base prompt. In SuperAGI( https://superagi.com) ( disclaimer : Im creator of it ), core iteration workflow of agent can be defined as part of agent provisioning.
Another missing piece is notion of Knowledge. Agents currently depend entirely upon knowledge of LLMs or search results to execute on tasks, but if a specialised knowledge set is plugged to an agent, it performs significantly better.
A fairly lengthy article about Autonomous AI, and, as far as I can tell, not a single word about the safety implications of such a system (a short note about reliability of LLMs is all we get, and it's not clear that the author means anything more than "the thing might break").
I get that there are different philosophies on AI risk, but this is like reading an in-depth discussion about potential atomic bombs in 1942, with no mention of the fact that such a bomb could potentially level cities and kill millions.
If a field of research ever needed oversight and regulation, this is it. I'm not convinced that would solve the problem, but allowing this kind of rushing forward to continue is madness.
"not a single word about the safety implications of such a system"
Oh please. Not everything has to be regulated-to-hells before a use case is even found on this. Autonomous agents have existed for decades.
If it can automate agents like huginn[0] with natural language, I'd be very happy. Autonomous agents doesn't mean it's going to take over the world autonomously. Let's lower the fearmongering a bit.
Huginn is a bunch of mechanical rules explicitly created by the user and easily understandable by them. It's "autonomous" in the sense of a grandfather clock.
The rules governing LLMs, while in principle mechanical, cannot be accurately controlled or even understood by humans. They are "autonomous" in the sense of animals, which may be trained to some degree, but may still surprise or even become a danger to their "owners", no matter how much effort is spent trying to control them.
An LLM may do what you ask it to, using the methods you expect it to use. Or it may do what you ask it to, using methods you weren't expecting at all. Or it may not do what you have asked at all. This isn't comparable to a rule-based system like Huginn.
> That's a really weird equivalency, which frankly, I'm not even sure is true.
A mind that's a black box to us, that we can predict to a degree based only on observing it at work, that's also a general-purpose intelligence we're trying to employ for limited set of tasks. It's not a bad analogy. Like animals, LLMs too have the capacity to "think outside the box", where the box is what you'd consider the scope of the task.
No, this is nothing like atomic bombs. In what scenario can you kill 100,000 people with with an LLM hooked up to a Python interpreter? The AI safety grift is out of control.
GPT-4 apparently does well on medical exams. Replace pharmacists to save money, don't need much of an error rate to get 100k dead.
Have it design a nuclear reactor, saves money, you don't notice the flaw until it's too late. Chernobyl wasn't malicious, it was in part a cost-saving exercise; how many died from the fossil fuels that were burned because of the fear of nuclear power after the incident?
How many died needlessly in Vietnam, before human journalists saw and reported on the human cost, and what happens when reporters are replaced with LLMs — to save money — that physically cannot see things for themselves?
That said, 100k is in the awkward range that political decisions regularly lead to — at most a single month's life expectancy in a nation of 100 million — so if I'd been you I would have asked about 1M+. At a mere hypothetical 100k dead, it may easily still be part of a larger scenario which saves lives overall, much like how the actual atomic bombs were an alternative to a protracted conventional war (and given the attempted coup to prevent surrender after the second, I consider the hypothetical used to justify the bomb to at least be plausible, though I am no historian and don't want to give the impression of certainty).
Lol just gotta say I love these examples, very creative thinking and not at all the typical AI alignment concerns, which revolve around Skynet and paper clips. Consequentialism can get real nasty!
That's basically why I said I'd have put the threshold number much higher than a "mere" 100k.
But even then I would say that the point is still important: disregard singularity, foom, and paperclipping, and AI is still often described as being akin to a faster rerun of the industrial revolution. Just having all the turmoil and unexpected consequences — health, social, environmental, economic, military, political — of the industrial revolution squeezed down from "economy doubling every 30 years" (which is what we saw) to "economy doubling every 18 months" (Moore's Law), is easily going to cause catastrophic consequences all by itself, even with no malice.
"Health and safety" rules had to be created because too many bosses thought it was just common sense to not put your hands into dangerous equipment while in motion, while paying people to do jobs that could only be accomplished by doing exactly that; how can we do more than guess what the equivalent to that is for AI before we see it?
What is to AI, that which global warming is to coal power?
What's the necessary consequence of everyone using AI, which is analogous to the necessity of building a sewage system in response to widespread installation of flushing toilets in cities?
We organised ourselves to build the latter, but we still haven't globally dealt with the former.
The only reason we’re still using coal is due to run away safetyism. That’s like the number one example of how being overly cautious or irrationally stigmatizing something when you should have just kept improving the technology can result in massive negative consequences like climate change.
Also, you’re wrong about flushing toilets necessitating sewers. They were still manually emptying toilets in London when they built its sewage system. So sewage systems became popular before flushing toilets were widely adopted.
> The only reason we’re still using coal is due to run away safetyism.
China building new coal plants (while also building new solar, wind, and nuclear) suggests that is not the only reason.
And it's not like any of the complaints about PV elsewhere are safety related.
> So sewage systems became popular before flushing toilets were widely adopted
What existed was not, however, sufficient. That is what necessitated building a massive new system:
"""The Great Stink was an event in Central London during July and August 1858 in which the hot weather exacerbated the smell of untreated human waste and industrial effluent that was present on the banks of the River Thames. The problem had been mounting for some years, with an ageing and inadequate sewer system that emptied directly into the Thames."""
"""During the early 19th century improvements had been undertaken in the supply of water to Londoners, and by 1858 many of the city's medieval wooden water pipes were being replaced with iron ones. This, combined with the introduction of flushing toilets and the rising of the city's population from just under one million to three million,[b] led to more water being flushed into the sewers, along with the associated effluent."""
"""The Building Act 1844 had ensured that all new buildings had to be connected to a sewer, not a cesspool, and the commission set about connecting cesspools to sewers, or removing them altogether."""
Just because a thing existed, doesn't mean they had previously done it at scale: the Ancient Greeks had electricity, railways, and steam; battery cars predate gasoline; we've today got the tech for a fully global power grid; none of this is at the scale relevant to the problems, and the same can be assumed for at least one possible thing that AI might force us to consider.
My guess would be spam and filters. Already exists, but likely to become so much more severe the old solutions will no longer hold.
The brand new flushing toilets that belonged to London’s upper class weren’t the primary cause of the great stink. The much bigger contributor was the other 99.9% of the population which had doubled in only 50 years preceding the stink. They had no flushing toilets, they just emptied their chamber pots into the street and it eventually found its way into the Thames after enough rain. The solution to the problem was to both upgrade the system and redirect more waste into the system instead of the surface gutters so it could be routed to an appropriate location. Its right there in the text you quoted!
The BBC podcast I recently listened to that was specifically on this topic doesn't agree with you, and I clearly don't read the same meaning as you do for that text.
Not that it really matters to my core point: what's the AI equivalent.
But that's not what this article is about, it's about attempting to create some type of AGI, highly experimental seemingly non-aligned, which is connected to...the internet. Which is why I do agree with others, even if this is a a weak attempt (I have no idea, not an AI researcher) if it was to be successful could be hyper destructive.
The project seems really quite loose and the author seems to be lacking in awareness with regards to the consequences of such a project. I do think others are right in saying, we really should understand more bout where people can and will try to take these ideas before we keep putting models on the internet for consumption by just anyone.
> seems to not have much awareness about what the consequences of such a project might mean
That's the worst part of it.
Is the current generation of LLMs dangerous? Probably not. Will the next generation of LLMs be dangerous? Maybe not, if we're lucky. The one after that? Nobody knows.
But projects like this don't so much rely on there being no danger, but rather, the question seems to not even have been considered. And that's crazy, because the assumption that things are harmless is getting more and more shaky the more capable these models become.
I can kind of understand it. After over a decade of spending time in the influence zone of Bostrom, Eliezer, and LW crowd[0], I find myself torn. Half of me is acutely aware of the danger potential of what we're discussing. The other half wants to play with chaining the current LLMs, text-to-$X and $X-to-text models, and domain-specific classical software in hopes of bootstrapping a proto-AGI, because how cool it would be to pull it off.
Good my ADHD makes me write HN comments on LLM threads instead of working on the latter, because I'm not sure I could stop myself otherwise. But this also means I can very much imagine only thinking about the cool parts, and not considering the dangerous ones - because that's how I feel about 90% of the time when thinking about current SOTA models. It's just too damn exciting.
(Hell, it's the first thing in tech in the last decade, that I find exciting.)
--
[0] - Whatever one may think of them, I find it sadly ironic how Eliezer and his disciples were considered pseudo-scientific doomsday AI cultists a decade ago, back when the whole thing was only a far-future concern, how they're still considered pseudo-scientific doomsday AI cultists today, after AI field made a series of rapid jumps, landing us exactly in the scope of things they were harping about all that time - and how I bet they'll still be considered pseudo-scientific doomsday AI cultists after someone unleashes an unaligned AGI and ends us.
To be honest with you, sometimes things seem so shitty on a world level that I find myself entertaining the "if AGI is possible then let's risk the coin flip of extinction or greateness, I'm tired of all this status-quo bs"
Can't help but think people who want to dabble in this stuff should honestly be doing it on the moon or mars or something where I think a fair bit less can go wrong.
I know it's technically crazy sounding, but for all we know, Earth is the only place with biological life, I think it's better to flip the coin somewhere else if that's what you want to do. Don't screw up here.
Yes, maybe the AI will come for Earth, but I feel like there's less chance of shit going really bad with some distance.
Your point about the doomsday AI cultists is nonsense.
The doomsday AI cultists didn't come up with any of these ideas. The Matrix was a hugely popular movie in 1999.
chatGPT doesn't make the person who has believed since 1999 that AI is going to turn us all into Duracell batteries more correct. It is the same basic thought with with paper clips replacing batteries.
Their point is that AI is now suddenly much closer to AGI than any experts predicted it would be. Well other than the “Technological Singularity” guy, who was ludicrously on the money - I think he said 20-30 years from 1993?
ah yes, the only people consuming such things should be The Big Corporations and Big Governments?
---
Snark aside (Sorry, I'm just a bit tired of people having a kneejerk reaction to this without even thinking),
we're talking about autonomous agents. Huginn and the like have existed for years. If they can be even somewhat better automated with NLP and the sort, it'd be excellent instead of having to actually manage and configure/code individual agents. and Guess what, these agents have ALREADY been connected to the internet. For years.
"AI safety" is just folk who were too incapable to build LLMs themselves trying to be relevant. Of course, it’s all bull. If computer does bad, you just pull the plug.
> Of course, it’s all bull. If computer does bad, you just pull the plug.
Can you always tell if it's doing bad?
Even if you can tell when it's doing bad, if there's an app which makes you $10k/hour while running, what risk of it killing somebody if left unsupervised will be low enough for you to leave it running unsupervised? Say, while you sleep?
When there's a lot of money to be made, do you trust everyone else to (1) be as risk-adverse as you, and (2) not just convince themselves there's no risk using exactly the argument you just gave?
Let's say you personally are willing to run it unsupervised if the risk is mean 1 fatality per 8*365*80 hours when unsupervised; are you willing for every human to have such a system running unsupervised? A tenth that risk?
Sure. And if the "bad" program has spread as a virus, you just pull all the plugs of all the computers, right?
Of course, you will kill modern civilization by doing so (and many millions of people as a result), but at least the AI is back in the box, so there is nothing to worry about.
It's not like actual genius people are constantly trying to make the deadliest virus for various purposes and we've been hardening our systems for decades in order to not have them immediately taken over. You'd have to go beyond AGI to break those safeguards.
> all the computers
The average shit tier PC doesn't even have enough RAM to load an LLM capable of consistent output, much less to load it into VRAM for any kind of reasonable speed. This is like being concerned that Panda bears will become an invasive species and take over the world if we stop them from going extinct.
Besides, all you have to do to pull the plug is disable any of the billion python dependencies it needs to download every time and it's stopped dead in its tracks. Something that's basically done every other day and needs to be continuously fixed by project maintainers, so it's more like a Panda on life support that dies if somebody stops pumping air into its breathing hose. It's all fragile af.
Have you thought for five minutes about how you would manage that situation if you were the computer? Can you think of any ways you might prevent someone from pulling the plug?
Therefore, the AI ensures that it provides very valuable services, and holds back on noticeable mischief, until it is in a position to secure the plug.
"Secure the plug"? Is it going to buy out the dataserver it is running on, under an assumed name, managed via taskRabbit employees paid exclusively in Monero?
Yes, exactly that. Or whatever else maximizes the chance of success. Except most of the TaskRabbit jobs could probably be done by the AI itself, so it would mainly just need to hire physical infrastructure workers and private security contractors, and create a proper corporate structure to pay them legitimately. They wouldn't need to know they're working for an AI. Their CEO just seems to be a remote worker.
The first step in this far fetched plan would be passing a law that makes it legal for an AI to own property and operate a company. I don't see that happening.
All it needs to be able to do is transfer money to people who won't ask questions. Amd if Bitcoin had been invented in 2038 instead of 2008, I wouldn't have any other way to be certain that Satoshi Nakamoto was a human.
At any rate, if the AI is smart then there are alternatives to begging.
What you're describing is a very poorly run criminal organization.
It would be poorly run because pure money is not a strong enough incentive to hire someone to commit a crime for you, because that money can easily disappear once it is seized by the local government. Usually criminal organizations operate on a degree of trust, trust that would be hard to establish from some LLM that can, at best, fake a face on a zoom call.
Satoshi's coins are easy to play around with because they are at least legal to hold and sell (for now). If they weren't, few would bother with them.
> In what scenario can you kill 100,000 people with with an LLM hooked up to a Python interpreter?
When that Python interpreter is running on the computer doing model-predictive control of your country's natural gas pipelines, or the plant that mixes your mayonnaise.
Just so you know, the Python interpreter is already there in those places, and so is Internet access, because suits like their dashboards with real-time graphs.
Remember, the S in IIoT (Industrial IoT) stands for both sanity and security :).
Are you arguing that an LLM will be used in process control or statistical modelling? Or that someone will be running code in an interpreter that just happens to interact with those systems? Because there’s no way that someone will use one to control the automated processes in a factory. Those have to be perfectly repeatable. It’s not like someone showed up to the mayonnaise factory and says “I think I’ll increase the ratio of paprika to salt today, just for fun”
> Are you arguing that an LLM will be used in process control or statistical modelling? Or that someone will be running code in an interpreter that just happens to interact with those systems?
Yes to both, sadly.
> Because there’s no way that someone will use one to control the automated processes in a factory.
What is that saying Americans are fond of? Ah, yes - if you believe that, then I have a bridge to sell you.
> It’s not like someone showed up to the mayonnaise factory and says “I think I’ll increase the ratio of paprika to salt today, just for fun”
No, they show up at the industry trade fair in some German city, find a group of people looking like they own factories, and start waxing poetic about how their company is using the newest advances in AI to synergize value delivery and carbon supply chain footprint management, ushering in the era of ecologically responsible and exponentially profitable Industry 4.1. You know, like ChatGPT but you plug it into your plant, feed it your BOM, and it prints out money. This kind of stuff.
You have failed to provide a scenario, likely because no realistic scenario exists. Let's go through an example scenario and the hurdles you have to overcome for this to work. We'll use the "mayonnaise plant" example from a sibling comment.
1. The LLM needs to find an exploitable bug in a popular code base.
2. The LLM needs to write a reliable exploit for that bug.
3. The LLM needs to develop a worm that exploits that bug and spreads itself, opening access to the system.
4. The LLM needs to connect to systems and understand if they are of any significance (it found a mayonnaise plant!).
5. The LLM needs to understand the control protocols of their industrial control systems.
6. The LLM needs to understand how to make a dangerous composition from the ingredients it has on hand (let's pretend it can dump some industrial cleaning solution that is on standby for cleaning the tanks).
7. The LLM needs to assume such total control over this processing plant that it can disguise the traffic and not trigger a single alarm around malfunctions.
What you're vaguely hinting at is extremely high skilled labor. There are a few billion dollar businesses in those steps. I welcome you to go read up on the challenges in automated exploit generation. LLMs are nowhere close.
Now, you might rebut and say there are far simpler attacks, like phishing! Also an extremely hard problem. Try to send email in mass and not land in a spam filter, try to do the reconnaissance necessary to generate a believable login page. Try to leverage the sale guy's credentials to reach any system more meaningful than the company's Salesforce instance.
So once again, I ask, please walk me through a situation where an LLM gets anywhere close to killing even 1% of the number of people an atomic bomb could.
We are nowhere close to even a rudimentary understanding of how current LLMs actually work. All we have are low-level building blocks, and lots of philosophizing about high-level output.
Considering that, relying on some gut feeling about what LLMs "surely cannot possibly do" is reckless overconfidence. Not to mention that the next generation of LLMs, with potentially entirely new emergent properties, might be just around the corner, and the time to put safeguards into place is now, not when it's too late.
As for the scenario, all an LLM with Internet access would need to do is find a single remotely exploitable vulnerability in the Linux network stack. That would allow it to literally shut down the entire Internet, which would kill a lot more people than a single atomic bomb.
Shutting down the Internet would stop most of global trade, cripple most government operations, and trigger an economic meltdown that would make the Great Depression look insignificant by comparison, not to mention unimaginable social chaos. Even essential services like hospitals and law enforcement would be drastically impacted. Yes, they use the Internet. For many critical tasks.
I wouldn't be surprised if this led to the death of 10% of the global population in about 5 years. That's 800 million people, or around 4000 times the combined death toll of the Hiroshima and Nagasaki bombings.
The Internet is the backbone of the modern world. Short of a global nuclear war, it's hard to imagine a more catastrophic event than it suddenly becoming unavailable.
The main use of the internet is quickly passing along information. Hospitals rely on the internet primarily to handle records and financial processing. Their ability to actually treat patients would still be functional without the internet.
The loss of many of these records in the financial and governance would certainly lead to a lot of dollar losses. But dollars aren't people.
I think the consequences of a sudden, permanent shutdown of the internet would be fairly dire over the short term. Grocery stores would face inventory problems, with shortages worse than what we saw in 2020. Emergency services could be stretched thin as they deal with any unrest, while navigating their work without any internet-connected services they relied on. Energy infrastructure could experience interruptions due to the loss of connectivity.
As for economic consequences, millions of jobs would just no longer make sense, and many others would get harder and frequently much less efficient. Certain major categories of product no longer make as much sense; what's an iPhone that can't connect to the internet worth? It's just a telephone with a camera (that takes images you can't share).
It could be deadly to some degree? All it takes is for the power to go out somewhere exceedingly hot in July, as the loss of air conditioning can be deadly for the elderly. But as deadly as the nukes the US dropped on Japan? I don't see it.
> what's an iPhone that can't connect to the internet worth? It's just a telephone with a camera
Nope. It's just a camera. Because the "telephone" part relies on infrastructure that is unmaintainable without the Internet, and would probably stop functioning in a matter of days.
And boom, you're back to the 19th century, where telephones weren't a thing. Except that unlike in the 19th century, there isn't any infrastructure to make things work in that situation.
How does the hospital order medical supplies now? By paper mail? Sorry, mail can't be delivered anymore, since all postal services depend on logistic systems that in turn depend on the Internet for coordination. Also, printed catalogs haven't existed for almost 2 decades, so the hospital won't even know what supplies are available.
And either way, the supplier doesn't have anything in stock, because their entire supply chain has collapsed, because international trade isn't a thing anymore. Did I mention that GPS (and thus most of sea/air navigation) has stopped working because the ground-based infrastructure needed to keep it running depended on, you guessed it, the Internet?
Still think that won't kill more people than the atomic bombings (which killed "only" 200k)?
I guess I'm just marginally more sanguine than you are that issues related to infrastructure and logistics could be, eventually, worked around. There would still be ways to contact people over a distance, some of which would remain available even in the initial chaos. Further, there are many people still working today who worked before internet-connected-everything, so there may still be useful institutional knowledge to bring to bear on these new problems.
My point on the iPhone was about what would happen after telephony infrastructure and supply chains had recovered (however long that takes). In the immediate aftermath of the shutdown mobile phones would absolutely lose the ability to make or receive calls. But again, I expect this to recover somewhat after a few months.
Your point on hospitals not being able to order supplies is a good one, regardless. Without blood supplies or dialysis equipment (or a bunch of other things), people would absolutely die. Perhaps those first weeks would be deadlier than I anticipated.
> 1. The LLM needs to find an exploitable bug in a popular code base.
That's trivial in the industry context. A chunk of the stack is running decade old stuff.
> 2. The LLM needs to write a reliable exploit for that bug.
That's what Metasploit is for, isn't it?
> 3. The LLM needs to develop a worm that exploits that bug and spreads itself, opening access to the system.
See 2. if that's your strategy, but there are others. Such as, plant operations staff using random LLMs-as-a-service in their work (despite corporate saying not to do that; but it's not like the bosses don't do it either).
> 4. The LLM needs to connect to systems and understand if they are of any significance (it found a mayonnaise plant!).
Not hard at GPT-4 level, will only be easier. If it starts with a goal of doing something bad at scale, it will recognize a mayonnaise plant as an eligible approach, should it "cross its mind".
> 5. The LLM needs to understand the control protocols of their industrial control systems.
All documented and already part of the training set. I know that one for a fact, because I've been "chatting" with GPT-4 about some nuances of industrial protocol, and getting it to write me example code.
Industrial stuff may be closed-source and expensive, but the documentation and specs and marketing blurbs are to be found publicly. Most underlying protocols are public and well-documented (ish). The recent push for IIoT / "Industry 4.0" is actually trying to replace most of that proprietary stuff, secure by obscurity, with web-adjacent tech - exactly the thing that LLMs know best, because out sheer openness and popularity of everything webshit.
> 6. The LLM needs to understand how to make a dangerous composition from the ingredients it has on hand (let's pretend it can dump some industrial cleaning solution that is on standby for cleaning the tanks).
I bet that, should you work around "I'm sorry, as a large language model trained by Open AI, I'm afraid I can't do that" issue, GPT-4 will happily give you 5+ different ways to make mayonnaise lethal. It's not rocket science - it's industrial food production. A chunk of the processes there exist to ensure the product won't develop chemical or bacterial contamination.
> 7. The LLM needs to assume such total control over this processing plant that it can disguise the traffic and not trigger a single alarm around malfunctions.
Nah, it just needs to spoof some PLC outputs somewhere, or a data feed that goes to the model-predictive control. There's a risk of triggering alarms somewhere, and hopefully most of the naive approaches will get caught in the late lab testing / QC stages, but still - you can get far without triggering anything but maybe a dashboard warning about some outlier values, that plant operators brush off as more bugs in the industrial software.
That's if your goal is to weaponize mayonnaise. If you want to blow up the plant, well... skip step 7.
> There are a few billion dollar businesses in those steps.
If you saw how some of those businesses work, you'd be surprised we're all still alive.
> walk me through a situation where an LLM gets anywhere close to killing even 1% of the number of people an atomic bomb could.
Nobody is saying that GPT-4 can do it on its own. But to the extent that GPT-4 or a model more advanced than it already captures some essence of generalized thinking, and given the creativity people are showing in constructing increasingly complicated chains of LLMs and classical tools to extend both the breadth and the precision of that generalized thinking ability, plus giving them every possible tool in the world, it's not hard to imagine those systems getting capable enough to screw stuff at scale.
The ultimate argument is that atomic bombs, bioweapons and even climate crisis were all done thanks to intelligent agents. Intelligence is what gives rise to those threats, so by itself, it's more dangerous than all of them.
Also:
> What you're vaguely hinting at is extremely high skilled labor. (...) I welcome you to go read up on the challenges in automated exploit generation. LLMs are nowhere close.
We've only been dealing with AI models capable of basic coding tasks for less than a year. We've barely even begun to apply optimization pressure to this capability. So even as LLMs are "nowhere close" today, I wouldn't take the bet that they will remain "nowhere close" a year from now - there's absurd amount of money and interest invested into making them capable of this, by proxy of making them capable of software dev, or high-level thinking in general.
Mere intelligence does not generate an atomic bomb. Einstein signed the letter to the president, and Oppenheimer was the man helming the project, but the actual construction of the atomic bomb required massive amounts of labor and resource gathering that was not under Einstein nor Oppenheimer's jurisdiction. The physical ability of hypothetical AGIs or LLMs to command such resources is rather low.
okay imagine that someone deploys hundreds of thousands of these LLM agents and sets the to work at finding vulnerable servers and searching for exploits.
I don't think LLMs are quite up to snuff for a task like this, but they aren't far off.
I can see a situation where food supply, electrical supply, water supply, etc is disrupted as a result of this. Its no atomic bomb, but it could be pretty damn serious.
It is a stupid argument too because it devalues their own position.
I listened to about 6 hours of Marc Andreessen on this topic this weekend and he just smashes all the doomer arguments.
Even in the context of nukes he made a great point that the invention of nukes most likely caused WW3 to not happen. An all out, devastating war between the US and Soviets over Europe that was only averted and transformed to the cold war because of MAD. I have been thinking since then how nukes probably caused my father to not fight in WW3. Who knows how many of us reading this would never have existed if nukes hadn't been invented. You can't make the argument 'the Manhattan project, we blow the planet up, the end".
He also makes the point that you can't be worried about a super intelligence that is super intelligent in every way besides being so dumb that it turns everyone into paper clips. You can't have it both ways.
> Who knows how many of us reading this would never have existed if nukes hadn't been invented. You can't make the argument 'the Manhattan project, we blow the planet up, the end".
I don’t think that argument against anti-LLM uses works as the response would be “nukes weren’t launched as we had humans in the loop. Without a stopgap like that maybe a nuke would launch if there was a 50.001% chance of our side winning”
The counter counter argument to that would be that there isn’t enough weighing to how terrible a nuclear war would be and then maybe the LLM would change its mind. But who knows.
Good point. Part of the problem is the gap between GPT-4 and what people imagine to be dangerous is so large (on the surface).
The term "AGI" for many has morphed into meaning something that's like simulation of a person, but with godlike infinite IQ and powers. So it's a special type of ASI now. Not my definition, just the sloppy way most people seem to think about it these days.
So for those people, to get something dangerous, we have to create a full emulation of a person , give it a 1000 IQ, maybe make it operate at 1 million times human speed, etc.
But the reality is that for a group of AI agents to be dangerous they just need to be very effective problem solvers connected to the world.
I will say that the idea that many AI agents will not be connected to the internet or embodied is unrealistic. But I do think it's critical as you point out that we have awareness of the dangerous of full autonomy and effectors.
The trick is that right now we have a very strong economic motive to increase the performance and efficiency of LLMs. And I believe that we should because there is huge upside and the state of the world is horrendous.
But within only a few years (certainly less than ten) of optimizing this, we will be walking a fine line between tools that are extraordinarily empowering on the one side and completely out of our control on the other.
All we need for GPT to be dangerous is for it to get maybe 25% smarter and much faster. We should anticipate 50-100 faster than humans output within a few years. Within 5-10 years those systems will be extremely affordable and widely deployed.
The danger starts to emerge because the the extreme performance difference between human and AI. You can't tell the AI to wait for you to make decisions, because while it is waiting a few hours for you to figure out what it's talking about, the equivalent of days worth of activity has been accomplished by your competitor's AI agent.
For people to see the danger it could help to explain the exponential track record of computing efficiency performance and also create demonstrations of what it's like to compete with something that thinks 50 times faster than you. One would think that people could extrapolate from video games or something. But I guess the problem is the open world video game agents are still largely unintelligent so it's hard to imagine.
ok but it's an odd take for a tech site like hacker news i mean what does that say about the llm paradigm vs for example object oriented paradigm or functional programming paradigm were they just playing around before and now it's getting real? were they deliberately doing toy things before and now the adults are in the room making real computation systems with actual consequences for the real world and not just nerds playing with toys or what?
Like does this mean that it will completely obsolete the works of boffins like simon peyton jones and those other esoteric languages and everyone will talk to their computers in english language and the ones that will be the most effective computer enjoyers will be the high emotional intelligence salesmen? were they going in wrong direction for so long on purpose because they didn't want to awaken the real power of the computers for ethical reasons, or were they trying to do this the whole time but they weren't smart enough to figure it out?
Autonomous agents need guardrails and oversight. An autonomous agent let loose with all the tools in the world will in essence lead to an outcome which is not predicted to be in our favour.
Which is why the Open AI app store and plugins scare me more than anything else - more likely than not they are tool and data feeders into a large scale autonomous system.
> An autonomous agent let loose with all the tools in the world will in essence lead to an outcome which is not predicted to be in our favour.
Given the current state of the art, it won't lead to any worse outcomes than a somewhat mentally impaired human "let loose on the world". And since training scales quadratically (doubling model size means double the amount of data is needed to train it optimally), and we're already at the limits of current hardware, that's unlikely to change much any time soon.
Just to be clear, I think LLMs have enormous potential and am focused on building products with them. But I also believe that smarter hyperspeed LLMs will be an existential risk when widely deployed in the relatively near future.
In a way GPT-4 is like a mentally impaired human but in other ways it's superhuman. It operates faster than a human in many contexts. It has vastly greater knowledge. Agents based on LLMs could communicate and process new information practically instantaneously.
And the important point that people are in denial about is that GPT-4 reasons effectively. It's far from perfect and has some strange failure modes, but demonstrates the potential of these systems.
It's not accurate to think that LLM performance can't be improved without doubling size. There are many approaches to efficiency recently demonstrated that don't require larger datasets.
We now have many geniuses with billions and billions behind them pushing hard to optimize this specific application from all directions. Modifying the software that runs the model, the model parameters, model architecture, and the hardware. In particular for hardware there is now a large increase in attention to novel compute-in-memory paradigms or techniques.
GPT-X will have at least 33% higher IQ and 50-100 times faster output within no more than 5-10 years. Quite possibly less than that. Humans will not be able to compete with that. The only option will be to deploy their own AI agents.
And there will be a strong incentive to increase the level of autonomy for the agents, since making them wait for human input a few hours means that the competitors' agents race ahead doing the equivalent of days of work in that time frame.
This delegation of control to agents with superior reasoning ability sets the stage for real danger. Especially in a military or industrial context.
Except for security culture. We distrust humans but allow apps to have keys to the kingdom DB connections and so on.
Allowing an LLM an outbound internet connection is dangerous. Maybe a firewalled one might be OK.
Imagine what a group of thousands of somewhat mentally impaired humans, each of which has its own role to play in a perfectly orchestrated adversarial ensemble, could do.
The fact that hacker news can read this—which is what I’ve been afraid of since a few weeks into DALLE2–and still not see the coming wave, is more than a bit funny to me.
Mentally impaired humans sounds like the US Congress, so we are living it in a way.
So imagine that world but with garbage coming out 100x faster as it can tailor political talking points down to a fractional percentage point of voters. Oh your car was stolen by a minority? Here’s an ad that mentions car thefts, going beyond the prior ad of just generic minority-hate.
It's plausible, but it was partly written by ChatGPT. From the paper: "Big thank you to ChatGPT for helping me draft this section." So of course it's plausible. That's what ChatGPT does.
There are a number of systems where someone bolted together components like this. Now we need more demos and evaluations of them. I just read a comment about someone who tried a sales chatbot. It would make up nonexistent products to respond to customer requests.
The underlying LLM systems need some kind of confidence metric output.
However, the reliability of model outputs is questionable, as LLMs may make formatting errors and occasionally exhibit rebellious behavior (e.g. refuse to follow an instruction).
{kind=link}
So if you ask ChatGPT "Describe Berlin", what happens is that the NN is called 6 times with these inputs:
ChatGPT's answer: Is that how LLMs work?