https://brutalistwebsites.com/ started in 2016; it has been a while. I would even say that proper web brutalism is not a thing anymore. It never become mainstream for real, because it was too bold.
I think a much better definition for the style described in the article is "Corporate Memphis" https://en.wikipedia.org/wiki/Corporate_Memphis - that is also a 10-year-long trend of colorful corporate soullessness.
This is a great trick for a lot of things. For example, if a web server is getting lots of attacks against a particular URL, one could block that URL or otherwise make it inaccessible. That'll turn it into a 404 or 500, or whatever. But it turns out that a 200 is much faster, and so replacing the target with a blank file is faster than denying it. This is particularly true with xml-rpc.php. Instead of just removing it, empty it. Problem solved.
Shout out to Behdad https://en.wikipedia.org/wiki/Behdad_Esfahbod a one of a kind man doing god's work. If you've seen text on a screen, you've seen Behdad's work. I've had the lucky opportunity to chat with him briefly and he personally helped me debug a text rendering problem. He's a great guy!
By the way, if you think this is interesting, you might also be curious to read about how fonts are installed/registered on Unix systems. It is a rabbit hole involving a key piece of software on pretty much every computer in the world called Fontconfig (also by Behdad) https://en.wikipedia.org/wiki/Fontconfig
Text and fonts are HARD. Give a hand to those who work tirelessly behind the scenes on this stuff for us.
Another Fun(tm) rendering bug: In Firefox, when a word is split across lines between two characters normally connected by a ligature, the ligature doesn't get disabled and the two characters rendered separately, but the ligature is sliced in half and rendered across lines:
Thank you for sharing. Even thou I have a lot fewer projects and majority of my work happens on the projects of clients - I managed to take away some useful ideas and tips. Specifically using "issue" as a place where everything gets tied together and combining all aspects of a feature into a single main-branch commit is something I will try to do more from now on.
Since your workflow is so GitHub centered, one place that IMO could use more structuring is GitHub issue labels [1] [2] [3]. Defaults are quite ad-hoc, with color not really representing anything. And setting up new default labels for new projects can be automated with command line scripts.
Django has allowed me to enjoy some side entrepreneurship. I have released three products as a solo part time dev that I would never have been able to do in a reasonable time using Java/Spring (my strongest stack). My first project went nowhere, but the second generated 1k+ a month and sold for 50k, and the third one is following a similar trajectory.
My advice - keep it simple
- function based views
- centralize access to the ORM (avoid fat models, use a service layer)
- responsive bootstrap template with crispy forms
- minimal js
- 12 factor type setup - django-environ or similar
- be aware of n+1 select problem (I use django debug toolbar but looking into django-zen-queries)
- plop it on heroku, AWS lightsail, Digital Ocean or if containerizing use AWS Fargate
- avoid celery unless you are at a scale you need it - use django-cron, django-db-queue or similar
- use a managed database and managed email service
I have had zero scalability problems. People say Django is slow but it handled 10k active users on a small EC2 instance without any issues (static stuff served via cloudfront)
Or as Hamming says in his famous essay: He who works with a closed door is more productive today and tomorrow, but over time works on just slightly the wrong things to make an impact. But those with an open door are full of flitting and scattering and keep getting distracted, yet over time stay aligned with the field and are much more likely to do important work
It's hard to fathom why people wouldn't know why regulations exist.
Without regulatory bodies, markets would not exist.
This is because regular consumers don't have the energy or ability to evaluate the quality of products or services, so in certain areas (health, safety, finance), where it 'really matters' - we regulate.
Without a drug regulatory body, there would be no way to know what drugs work, and the market would be almost entirely scammers.
Have a look at 'moisterizers' - it's a ridiculous game of false and misleading information by so called 'reputable' companies using technology totally out of context i.e. 'collagen' in order to be able to put it on the label. There's nary a way to understand what is effective and what is not. It's a completely distorted market. Now, it's just moisturizer, so it doesn't matter.
But we don't want the same thing for diabetes drugs, now do we?
The financial system is highly, highly regulated because it used to be full of outright scams and the system couldn't grow without it.
Integrity is key to all long term growth, it's why we have rules.
Now it should be possible to invest in highly speculative, risky things - sure - that should be up to you - but the reason we don't want to allow that in some instances is because the mechanism itself is fraudulent and misrepresentation i.e. a Ponzi Scheme is a Ponzi Scheme and it's bad to have them going around, even if you want to invest in them.
The entire field of Crypto thus far has been a giant distraction and waste of time, while there is definitely the possibility of some good coming out of this, it hasn't happened yet, we should be in the experimental stage, not the 'using up more electricity than Argentina stage'.
"We thought of life by analogy with a journey, a pilgrimage, which had a serious purpose at the end, and the thing was to get to that end, success or whatever it is, maybe heaven after you're dead. But we missed the point the whole way along. It was a musical thing and you were supposed to sing or to dance while the music was being played."
Just a data point. My team manages about 15 different brands with a couple hundred million annual page views and we pay north of $100K a year for fonts and believe that to be a good value for the money. The difference between a good Monotype font and a free or cheap font is worlds different when your concerned with a brand looking as good as can be. The cheaper fonts sometimes have odd space in them that make letter spacing or line-height changes look horrible.
There's also a nice concept called an antilibrary [1]:
> The writer Umberto Eco belongs to that small class of scholars who are encyclopedic, insightful, and nondull. He is the owner of a large personal library (containing thirty thousand books), and separates visitors into two categories: those who react with “Wow! Signore professore dottore Eco, what a library you have! How many of these books have you read?” and the others — a very small minority — who get the point that a private library is not an ego-boosting appendage but a research tool. Read books are far less valuable than unread ones. The library should contain as much of what you do not know as your financial means, mortgage rates, and the currently tight real-estate market allows you to put there. You will accumulate more knowledge and more books as you grow older, and the growing number of unread books on the shelves will look at you menacingly. Indeed, the more you know, the larger the rows of unread books. Let us call this collection of unread books an antilibrary.
At least, it's a good excuse to buy more books that one can read. :)
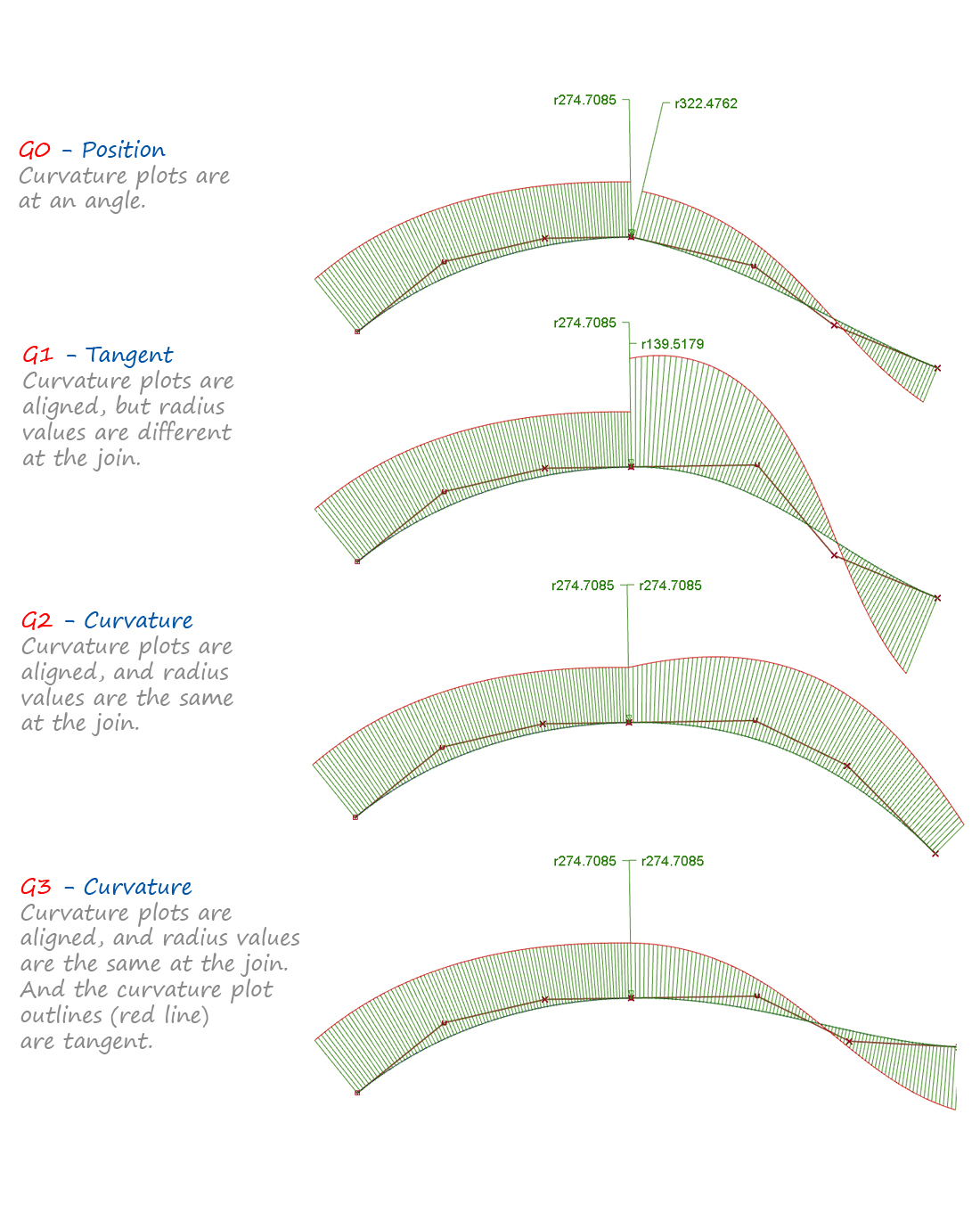
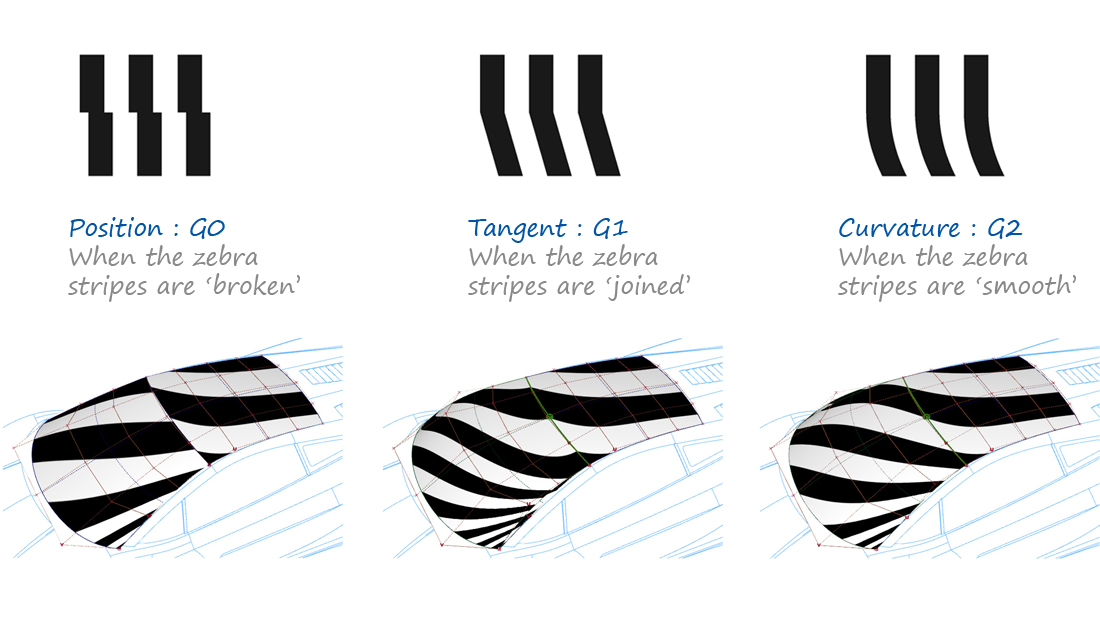
It's really interesting if you look at how CAD handles this stuff. It lets you set the degree of curvature-continuity/smoothness you want—and it kind of takes care of filling in the curve for you. You have to give up some direct control over the curve if you need it to meet these constraints.
"...Gautama Buddah found that there was a way to exit this vicious circle.
If, when the mind experiences something pleasant or unpleasant, it simply understand things as they are, then there is no suffering.
If you experience sadness without craving that the sadness go away, you continue to feel sadness but you do not suffer from it. There can actually be richness in the sadness.
If you experience joy without craving that the joy linger and intensify, you continue to feel joy without losing your peace of mind.”
There are lots of things to be said about Nix and NixOS, and many of these things have been mentionned in this page, but there's one thing I really like with Nix : the fact the the configuration is expressed as a function that takes its own result as argument, and that the final configuration is the fixed point of that function. This is a very powerful concept, as these functions can be composed together.
I think this idea is not specific to Nix, and I wish it was used a lot more in configuration languages. For example, it was something I really missed when using Ansible. The lack of this feature means that writing the inventory is much harder than it needs to be, and I've seen horrible hacks that try to get around this.
>Apply the dichotomy of control and the four virtues to everything you do and, as Epictetus promises, you will never be unhappy. You will be free, and you will live a life truly worth living. We all fall short of this ideal, of course. Yet trying to live up to it really works.
That "really works" part is why approximately 80% of western therapists practice CBT (cognitive behavioral therapy) which was pioneered by Albert Ellis and his team after inspiration from capital S Stoicism. Not psychoanalysis or any of the other popular 20th century approaches to the mental health of modern man, but a derivative of Stoicism that has proved very powerful.
As someone who has been reading Stoic works for 5+ years and for the last two years practicing my own derivation on a daily basis, a part of me agrees that the conflating of the modern adjective stoic and the philosophy and approach of Stoicism is indeed unfortunate. However, I do not believe that this is the primary barrier to entry, but rather the fact that practicing the philosophy is hard, slow work. Just as effective CBT asks a lot of the patient, Stoicism is not a quick fix. In some ways I see the misnomer as a tiny hurdle to entry that weeds out those only interested in dialectic rather than the hard work of changing and crafting one's character.
I would be dishonest if I didn't also point out that Ancient Stoicism has some fundamental problems that are also likely a barrier to the thoughtful. One of its founding pillars is a teleological universe which, thanks to advances in science, we now know to be false. Further, Stoicism glosses over aspects of human behavior (such as addiction and trauma) and is outdated in its approach to inter-community relations, approaching social contracts in the context of small, warlike city states (and later in the context of an authoritarian, imperialistic empire).
A modern, widely adoptable descendant of Ancient Stoicism would be quite different and most certainly wouldn't be called Stoicism. In the end, I don't believe the layperson's misunderstanding of Stoicism needs to be fixed. Truth needs no defense - the predictive and eudaimonic power of Stoicism is there for anyone to pluck if they have the impulse to reach for it and the courage to do the hard work of applying and reforming the self, along with the philosophy.
That said, it's awesome, you all should check it out.
There is a trick that I wish all senior staff knew but we find ourselves having to teach as a matter of routine.
1) Don't advertise what you're not selling
2) Don't sell everything that you've made
It's possible to write software that has a public contract that allows only a subset of states that the internal system allows. You can use this to support one customer that has a requirement that is mutually incompatible with another customer's, but you can also use it for migrations. One should be able to create an API where the legal values in the system are strictly limited, but the data structures and storage format may have affordances to support migration.
That doesn't necessarily solve the problem of communication between services and migrating these changes into a running system, but it's a useful tool. If you've ever had a coworker who insists on your service call diagrams looks like a tree or an acyclic graph, this problem is certainly one of many reasons they may be insisting on this. With a DAG there is an order in which I can deploy things that has a prayer (but not a guarantee) of letting all of the systems understand each other during each increment of deployment.
People have come up with alternative solutions for this problem by employing sophisticated sets of feature toggles, and in some ways this is superior, but it trades the number of steps (each of which has a potential for human error, and consumes calendar time) for increased reliability on average.
You need to separate sales from marketing. Sales is a conversation, marketing is a broadcast. Marketing gets the phone to ring, sales takes the call and closes the deal.
For B2B sales resembles project management: the goal is not to convince everyone to buy your product or service but to diagnose their needs and only engage with firms that will benefit.
For larger deals you "sell with your ears" as much as you talk.
I find Neil Rackham's "Spin Selling" very useful. Peter Cohan's "Great Demo" embeds a lot of discovery advice and suggests that a good demo is really a conversation driven by mutual curiosity about customer needs and software capabilities.
Two final books I would suggest, while not exactly sales books, are "The Innovator's DNA" by Clayton Christensen and "The Right It (Pretotype It)" by Alberto Savoia. They cover a number of techniques for finding the right problem to solve and determining if your solution is a good fit for customer needs. I mention them because it's not uncommon for a startup to have a product problem that manifests as a sales problem.
Lots of people make the mistake of thinking there's only two vectors you can go to improve performance, high or wide.
High - throw hardware at the problem, on a single machine
Wide - Add more machines
There's a third direction you can go, I call it "going deep". Today's programs run on software stacks so high and so abstract that we're just now getting around to redeveloping (again for like the 3rd or 4th time) software that performs about as well as software we had around in the 1990s and early 2000s.
Going deep means stripping away this nonsense and getting down closer to the metal, using smart algorithms, planning and working through a problem and seeing if you can size the solution to running on one machine as-is. Modern CPUs, memory and disk (especially SSDs) are unbelievably fast compared to what we had at the turn of the millenium, yet we treat them like they're spare capacity to soak up even lazier abstractions. We keep thinking that completing the task means successfully scaling out a complex network of compute nodes, but completing the task actually means processing the data and getting meaningful results in a reasonable amount of time.
This isn't really hard to do (but it can be tedious), and it doesn't mean writing system-level C or ASM code. Just seeing what you can do on a single medium-specc'd consumer machine first, then scaling up or out if you really need to. It turns out a great many problems really don't need scalable compute clusters. And in fact, the time you'd spend setting that up, and building the coordinating code (which introduces yet more layers that soak up performance) you'd probably be better off just spending the same time to do on a single machine.
Bonus, if your problem gets too big for a single machine (it happens), there might be trivial parallelism in the problem you can exploit and now going-wide means you'll probably outperform your original design anyways and the coordination code is likely to be much simpler and less performance degrading. Or you can go-high and toss more machine at it and get more gains with zero planning or effort outside of copying your code and the data to the new machine and plugging it in.
Oh yeah, many of us, especially experienced people or those with lots of school time, are taught to overgeneralize our approaches. It turns out many big compute problems are just big one-off problems and don't need a generalized approach. Survey your data, plan around it, and then write your solution as a specialized approach just for the problem you have. It'll likely run much faster this way.
Some anecdotes:
- I wrote an NLP tool that, on a single spare desktop with no exotic hardware, was 30x faster than a 6-high-end-system-distributed-compute-node that was doing a comparable task. That group eventually used my solution with a go-high approach and runs it on a big multi-core system with as fast of memory and SSD as they could procure and it's about 5 times faster than my original code. My code was in Perl, the distributed system it competed against was C++. The difference was the algorithm I was using, and not overgeneralizing the problem. Because my code could complete their task in 12 hours instead of 2 weeks, it meant they could iterate every day. A 14:1 iteration opportunity made a huge difference in their workflow and within weeks they were further ahead than they had been after 2 years of sustained work. Later they ported my code to C++ and realized even further gains. They've never had to even think about distributed systems. As hardware gets faster, they simply copy the code and data over and realize the gains and it performs faster than they can analyze the results.
Every vendor that's come in after that has been forced to demonstrate that their distributed solution is faster than the one they already have running in house. Nobody's been able to demonstrate a faster system to-date. It has saved them literally tens of millions of dollars in hardware, facility and staffing costs over the last half-decade.
- Another group had a large graph they needed to conduct a specific kind of analysis on. They had a massive distributed system that handled the graph, it was about 4 petabytes in size. The analysis they wanted to do was an O(N^2) analysis, each node needed to be compared potentially against each other node. So they naively set up some code to do the task and had all kinds of exotic data stores and specialized indexes they were using against the code. Huge amounts of data was flying around their network trying to run this task but it was slower than expected.
An analysis of the problem showed that if you segmented the data in some fairly simple ways, you could skip all the drama and do each slice of the task without much fuss on a single desktop. O(n^2) isn't terrible if your data is small. O(k+n^2) isn't much worse if you can find parallelism in your task and spread it out easily.
I had a 4 year old Dell consumer level desktop to use so I wrote the code and ran the task. Using not much more than Perl and SQLite I was able to compute a large-ish slice of a few GB in a couple hours. Some analysis of my code showed I could actually perform the analysis on insert in the DB and that the size was small enough to fit into memory so I set SQLite to :memory: and finished it in 30 minutes or so. That problem solved, the rest was pretty embarrassingly parallel and in short order we had a dozen of these spare desktops occupied running the same code on different data slices and finishing the task 2 orders of magnitude than what their previous approach had been. Some more coordinating code and the system was fully automated. A single budget machine was theoretically now capable of doing the entire task in 2 months of sustained compute time. A dozen budget machines finished it all in a week and a half. Their original estimate on their old distributed approach was 6-8 months with a warehouse full of machines, most of which would have been computing things that resulted in a bunch of nothing.
To my knowledge they still use a version of the original Perl code with SQlite running in memory without complaint. They could speed things up more with a better in-memory system and a quick code port, but why bother? It's completing the task faster than they can feed it data as the data set is only growing a few GB a day. Easily enough for a single machine to handle.
- Another group was struggling with handling a large semantic graph and performing a specific kind of query on the graph while walking it. It was ~100 million entities, but they needed interactive-speed query returns. They had built some kind of distributed Titan cluster (obviously a premature optimization).
Solution, convert the graph to an adjacency matrix and stuff it in a PostgreSQL table, build some indexes and rework the problem as a clever dynamically generated SQL query (again, Perl) and now they were realizing .01second returns, fast enough for interactivity. Bonus, the dataset at 100m rows was tiny, only about 5GB, with a maximum table-size of 32TB and diskspace cheap they were set for the conceivable future. Now administration was easy, performance could be trivially improved with an SSD and some RAM and they could trivially scale to a point where dealing with Titan was far into their future.
Plus, there's a chance for PostgreSQL to start supporting proper scalability soon putting that day even further off.
- Finally, a e-commerce company I worked with was building a dashboard reporting system that ran every night and took all of their sales data and generated various kinds of reports, by SKU, by certain number of days in the past, etc. It was taking 10 hours to run on a 4 machine cluster.
A dive in the code showed that they were storing the data in a deeply nested data structure for computation and building and destroying that structure as the computation progressed was taking all the time. Furthermore, some metrics on the reports showed that the most expensive to compute reports were simply not being used, or were being viewed only once a quarter or once a year around the fiscal year. And cheap to compute reports, where there were millions of reports being pre-computed, only had a small percentage actually being viewed.
The data structure was built on dictionaries pointing to other dictionaries and so-on. A quick swap to arrays pointing to arrays (and some dictionary<->index conversion functions so we didn't blow up the internal logic) transformed the entire thing. Instead of 10 hours, it ran in about 30 minutes, on a single machine. Where memory was running out and crashing the system, memory now never went above 20% utilization. It turns out allocating and deallocating RAM actually takes time and switching a smaller, simpler data structure makes things faster.
We changed some of the cheap to compute reports from being pre-computed to being compute-on-demand, which further removed stuff that needed to run at night. And then the infrequent reports were put on a quarterly and yearly schedule so they only ran right before they were needed instead of every night. This improved performance even further and as far as I know, 10 years later, even with huge increases in data volume, they never even had to touch the code or change the ancient hardware it was running on.
It seems ridiculous sometimes, seeing these problems in retrospect, that the idea was that to make these problems solvable racks in a data center, or entire data centeres were ever seriously considered seems insane. A single machine's worth of hardware we have today is almost embarrassingly powerful. Here's a machine that for $1k can break 11 TFLOPS [1]. That's insane.
It also turns out that most of our problems are not compute speed, throwing more CPUs at a problem don't really improve things, but disk and memory are a problem. Why anybody would think shuttling data over a network to other nodes, where we then exacerbate every I/O problem would improve things is beyond me. Getting data across a network and into a CPU that's sitting idle 99% of the time is not going to improve your performance.
Analyze your problem, walk through it, figure out where the bottlenecks are and fix those. It's likely you won't have to scale to many machines for most problems.
I'm almost thinking of coming up with a statement: Bane's rule, you don't understand a distributed computing problem until you can get it to fit on a single machine first.
So Vitamin D deficiency is linked to cancer, heart disease, respiratory infection, stroke, diabetes, and death. But taking it as a supplement helps with none of the above. What is a reasonable hypothesis then? That having an active lifestyle that brings you outside in the sun both causes your Vitamin D to go up, and is correlated with better physical health in general?
Don't make your readers hold parts of the sentence in their head. Reorder or split sentences until it can be avoided. In other words, use a really small buffer.
"You must fill form 331 unless you are over 60 years old, in which case you must fill form 445."
"You must fill form 331. If you are over 60 years old, you must fill 445 instead."
"If you are over 60 years old, you must fill form 445. Otherwise, you must fill form 331."
You might have noticed that the last version is an if-else statement.
This is part of why I blog and run r/GigWorks and r/ClothingStartups: I figured out how to make money from the street while very ill.
This is solvable. We just aren't working on the right things.
We need to get people working again in a way that doesn't spread the virus. We need to work on resolving our housing supply issues. We've torn down a million SROs and not replaced them. We've largely zoned Missing Middle housing out of existence.
We collectively know how to create affordable market rate housing in walkable neighborhoods. We just basically choose not to in the US.
And now it's A Real Crisis, not "just a few losers with personal problems". We need to get our head out the sand and stop pretending we are too stupid to fix this, good god. We aren't too stupid. That's not the issue.
> still don’t know if I understand what this presentation is about
1. The simplicity of a system or product is not the same as the ease with which it is built.
2. Most developers, most of the time, default to optimizing for ease when building a product even when it conflicts with simplicity
3. Simplicity is a good proxy for reliability, maintainability, and modifiability, so if you value those a lot then you should seek simplicity over programmer convenience (in the cases where they are at odds).
{kind=link}
{kind=link}
{kind=link}